More than anything else, modern development’s primary focus is often based around three central concepts:
- efficiency
- reliability
- repeatability
But how do you achieve these three objectives when modern application architectures often have a range of variables in play at any one time, which is further exacerbated by multiple deployment environments?
To achieve these goals, you need a technology that removes much of the variability in the design, development, and deployment processes.
For me, Docker is that technology; especially if you’re keen to predictably streamline deployments from development, across a range of testing and review environments, to production.
This might sound like a big claim, something that has been argued by other technologies in the past that have failed to live up to it. But I believe Docker is different. In this article, I set out three key reasons why it’s key to streamlining production. Let’s begin.
1 – It Supports Packaged Applications
When I first came to Docker several few months ago, this was what struck me most clearly. The central concept of Docker is that it allows you to containerize an application. Or, it allows you to package up your application and deploy it.
This assumption works best when your application is a single binary, such as software written in Go or a Java JAR file. But it can work equally well for applications using dynamic languages, such as PHP, Python, and Ruby.
When working with Docker, applications don’t have to be single binaries. They can incorporate an n-tier architecture consisting of a runtime, a web server, and any number of other services, such as database, caching, and queuing servers.
To illustrate what I mean, take a look at the following image. It represent a basic PHP application (the ones with which I’m most familiar) that contains three components:
- A PHP runtime, which includes the application code
- A web server (NGINX, Apache, Lighttpd, etc.)
- A data source (MariaDb, PostgreSQL, SQLite, etc.)
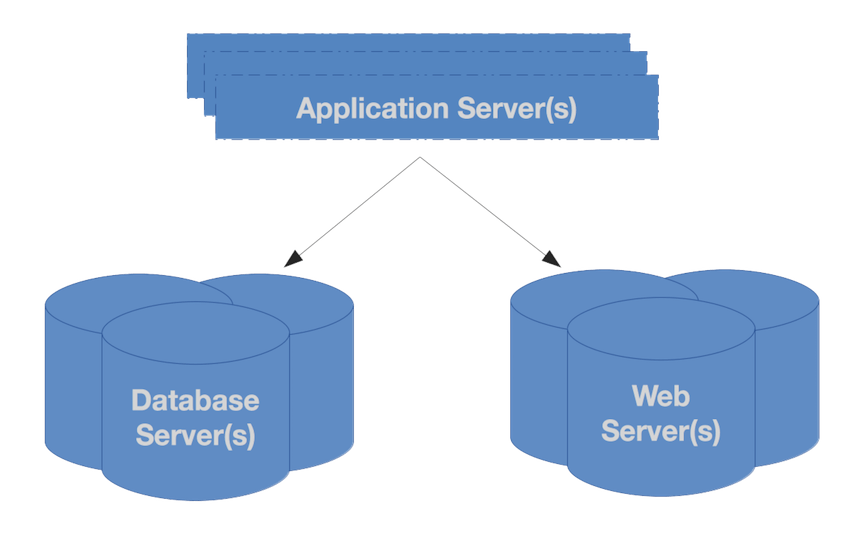
However, if our application is written correctly, then it won’t be dependent on a particular database vendor nor on any of the other services I mentioned. It will likely use a framework and a set of development practices which abstracts away the specific interaction with any given service.
When that’s the case, Docker is extremely well suited. We can package up the application and drop it into a container configuration with all the other services it needs; services that can change, as necessary, between development, staging, testing, and production.
To put this in proper context, take the simplistic Dockerfile below. This will package up the hypothetical PHP application I’ve been working on into a custom Docker container:
FROM php:7.0-fpm
EXPOSE 9000
RUN mkdir -p /var/www/html
COPY . /var/www/html
WORKDIR /var/www/html
RUN docker-php-ext-install pdo_mysql \
&& docker-php-ext-install json
RUN apt-get update \
&& apt-get --yes --force-yes install git \
&& apt-get --yes --force-yes install zip \
&& apt-get --yes --force-yes install unzip
RUN ./composer.phar installWorking through it from top to bottom, we see that it starts off basing the container on the official Docker PHP 7 FPM image, as the codebase requires a minimum version of PHP 7.0.
Then, within the container, it creates the project’s directory root, copies the code there, and sets that as the working directory.
After that, it makes two PHP extensions available, along with three binaries, which are all required for the application to run.
Following this, it then uses PHP’s package manager, Composer, to include the third-party library dependencies the codebase needs; dependencies identified in the application’s composer.json package configuration file.
Whether this was the first, tenth, hundredth, or even millionth build, the steps to build the container are the same. What’s more, they’re very clear and very precise. They also have the bonus of being concise; something I can’t say for other approaches.
This approach removes enormous variability from the equation. The PHP runtime, whether it’s being used in development (or any other environment), will be the same. It will be based on the same version of PHP, have the same extensions (at the same major, minor, and point releases), and have all the other binaries it needs, at the same versions.
As I argued recently here on the Codeship blog, this significantly reduces technical risk, as well as increases confidence in the quality of the product.
Lazy arguments, such as “it works on my computer”, are virtually impossible. How can a build fail because of a difference from one environment to another, when no difference should exist?
Here, I’ll defer to my friend and one of the resident Docker experts in the PHP community, Chris Tankersley, when he says:
Since each build is bundled into an image [container], you are assured that each time the build goes to a server, it is exact and complete.
And here’s what another, David McKay of Docker Glasgow, has to say:
Because you’ve built an artifact, you’ve got confidence that the same thing you ran your tests against is what you deploy.
Given this, nothing will be missing, unless the container configuration is incomplete. However, this should have been picked up already.
!New Call-to-action
2 – It Supports “Build Once, Deploy Many Times” In Multiple Locations
Assuming that building the Docker container we’ve described in the last section is part of our continuous deployment process, it would be run and create a new version of the application container every time a commit was pushed or a pull request was merged.
Once the container is created, it could then be deployed to any environment, whether that was test, staging, production, or anywhere else.
The build steps may change over time; they may get more sophisticated, they may not. But given the clarity of the build instructions, it’s incredibly easy to repeat, which makes it extremely predictable and reliable.
Once built, it’s now a self-contained component able to be deployed anywhere. It can, if applicable, be stored in the official Docker Hub. Or, it could be stored in a custom Docker container repository maintained by your organization. Regardless, once there, it can be pulled in to a container setup anywhere.
What’s more, when built properly, the application won’t store any configuration or credentials in the codebase. Instead, they’ll be in the environment as environment variables. When this is done, the variables can be picked up by the container and passed to the application.
Want to use a local Redis container in development (or a filesystem-based cache if you’re so inclined), but in production, you want to use a remote service like Redis Cloud? Not a problem. In the respective environments, change the environment variables and watch the application to make use of the different service setups.
Regardless of the combination, location, size, and complexity, from the perspective of your application, it makes use of a remote service located somewhere. As long as the service is reachable and does what it should, your application will work.
With all that in mind, so long as the tests pass, then the container containing the application can be built and stored for later use. From there, it can then be retrieved and deployed to whatever environment is required.
Think of the simplification that presents.
As another Docker expert, Chris Fidao, says:
This fulfills the promise that virtual machines promised us, but failed to enforce
3 – It Supports Easy Rollback
While the focus of deployments is most often on deploying the next release, things can go wrong. That’s actually ok — every now and then.
Sometimes, despite the best efforts in our processes and test procedures, bugs slip through or occur for all but the most unexpected of reasons.
In times like these, it’s essential that you can back out of the last release, back to a point when the application was working as expected (hopefully, the last release), even if it has slightly reduced functionality.
Well, depending on how your Docker containers are built and stored, this might be available as a matter of course. Now, to the best of my knowledge, Docker doesn’t provide this type of functionality out of the box. But you should be able to implement it quite easily.
In a simple setup, a newly created build would overwrite the previous one, resulting in only one copy of the application container. But your continuous deployment service could be set up differently. It could, instead, create and maintain a container for any number of releases.
Let’s assume that the build pipeline creates and stores in your container repository at least the last five builds. If the current build fails, you can then successively deploy the container with the previous release, until the application works again.
As I said, I don’t have a specific implementation to point to. But, in addition to setting up your existing CI pipeline, it would not take a lot of work to make this available.
If time and expense are of a concern, and I’m not saying that they shouldn’t be, think of the cost this would reduce, along with the lost income and impact on your reputation when your service unexpectedly goes down.
Conclusion
There are three solid reasons why I believe that Docker streamlines production deployments:
- It supports packaged applications.
- It supports “build once, deploy many times” in multiple locations.
- It supports easy rollback.
By using Docker, a tool that allows you to containerize your application, you can streamline the deployments of your application across all of your environments, from development through to production.
If you’ve not considered Docker as a part of your development toolchain yet, I hope that this will motivate you to do so. It’s a tool with a lot of merit, one that’s only getting better.
| Reference: | How Docker Streamlines Production Deployments from our JCG partner Matthew Setter at the Codeship Blog blog. |
