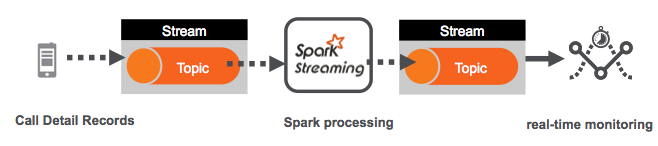
This post will help you get started using Apache Spark Streaming for consuming and publishing messages with MapR Streams and the Kafka API. Spark Streaming is an extension of the core Spark API that enables continuous data stream processing. MapR Streams is a distributed messaging system for streaming event data at scale. MapR Streams enables producers and consumers to exchange events in real time via the Apache Kafka 0.9 API. MapR Streams integrates with Spark Streaming via the Kafka direct approach. This post is a simple how to example, if you are new to Spark Streaming and the Kafka API you might want to read these first:
- Real-Time Streaming Data Pipelines with Apache APIs: Kafka, Spark Streaming, and HBase
- Getting Started with MapR Streams
- Spark Streaming with HBase
Example Use Case Data Set
The example data set is from the Telecom Italia 2014 Big Data Challenge, it consists of aggregated mobile network data generated by the Telecom Italia cellular network over the city of Milano and Trento. The data measures the location and level of interaction of the users with the mobile phone network based on mobile events that occurred on the mobile network over 2 months in 2013. The projects in the challenge used this data to provide insights, identify and predict mobile phone-based location activity trends and patterns of a population in a large metropolitan area.
The Data Set Schema
- Square id: id of the location in the city grid
- Time interval: the beginning of the time interval
- Country code: the phone country code
- SMS-in activity: SMS received inside the Square id
- SMS-out activity: SMS sent inside the Square id
- Call-in activity: received calls inside the Square id
- Call-out activity: issued calls inside the Square id
- Internet traffic activity: internet traffic inside the Square id
The Data Records are in TSV format, an example line is shown below:

Example Use Case Code
First you import the packages needed to integrate MapR Streams with Spark Streaming and Spark SQL.
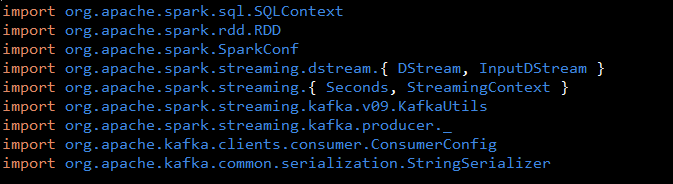
In order for Spark Streaming to read messages from MapR Streams you need to import from org.apache.spark.streaming.kafka.v09. In order for Spark Streaming to write messages to MapR Streams you need to import classes from org.apache.spark.streaming.kafka.producer._ ;
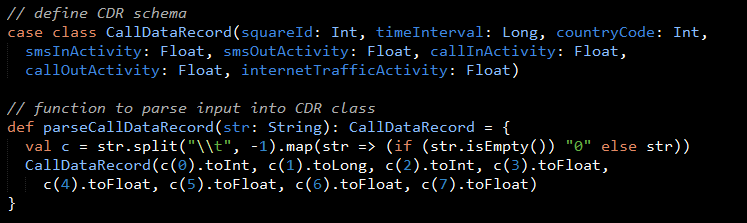
Parsing the Data Set Records
A Scala CallDataRecord case class defines the schema corresponding to the TSV records. The parseCallDataRecord function parses the tab separated values into the CallDataRecord case class.
Spark Streaming Code
These are the basic steps for the Spark Streaming Consumer Producer code:
- Configure Kafka Consumer Producer properties.
- Initialize a Spark StreamingContext object. Using this context, create a DStream which reads message from a Topic.
- Apply transformations (which create new DStreams).
- Write messages from the transformed DStream to a Topic.
- Start receiving data and processing. Wait for the processing to be stopped.
We will go through each of these steps with the example application code.
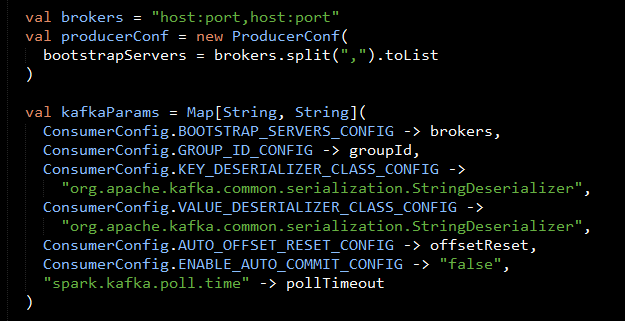
1) Configure Kafka Consumer Producer properties
The first step is to set the KafkaConsumer and KafkaProducer configuration properties, which will be used later to create a DStream for receiving/sending messages to topics. You need to set the following paramters:
- Key and value deserializers: for deserializing the message.
- Auto offset reset: to start reading from the earliest or latest message.
- Bootstrap servers: this can be set to a dummy host:port since the broker address is not actually used by MapR Streams.
For more information on the configuration parameters, see the MapR Streams documentation.
2) Initialize a Spark StreamingContext object.
We use the KafkaUtils createDirectStream method with a StreamingContext object , the Kafka configuration parameters, and a list of topics to create an input stream from a MapR Streams topic. This creates a DStream that represents the stream of incoming data, where each message is a key value pair. We use the DStream map transformation to create a DStream with the message values.

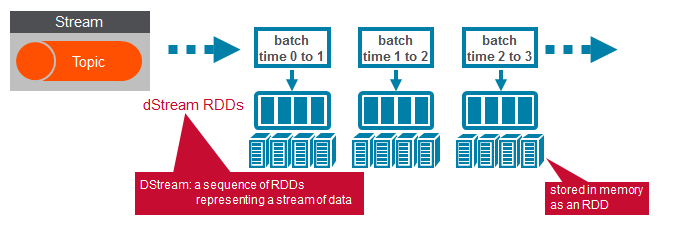
3) Apply transformations (which create new DStreams)
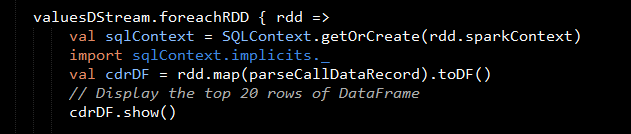
Next we use the DStream foreachRDD method to apply processing to each RDD in this DStream. We parse the message values into CallDataRecord objects, with the map operation on the DStream, then we convert the RDD to a DataFrame, which allows you to use DataFrames and SQL operations on streaming data.
Here is example output from the cdrDF.show :

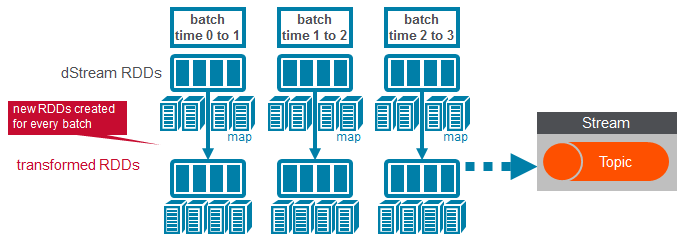
4) Write messages from the transformed DStream to a Topic
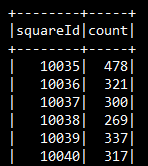
The CallDataRecord RDD objects are grouped and counted by the squareId. Then this sendToKafka method is used to send the messages with the squareId and count to a topic.

Example output for the squareId and count is shown below:
5) Start receiving data and processing it. Wait for the processing to be stopped.
To start receiving data, we must explicitly call start() on the StreamingContext, then call awaitTermination to wait for the streaming computation to finish.

Software
This tutorial will run on the MapR v5.2 Sandbox, which includes MapR Streams and Spark 1.6.1. You can download the code, data, and instructions to run this example from here: Code: https://github.com/caroljmcdonald/mapr-streams-spark
Summary
In this blog post, you learned how to integrate Spark Streaming with MapR Streams to consume and produce messages using the Kafka API.
References and More Information:
- This use case example builds upon an example from the book Pro Spark Streaming By Zubair Nabi, which contains other interesting Spark Streaming examples.
- Integrate Spark with MapR Streams Documentation
- Free Online training on MapR Streams, Spark at learn.mapr.com
- Getting Started with Spark on the MapR Sandbox
- Apache Spark Streaming Programming Guide

| Reference: | How to Get Started with Spark Streaming and MapR Streams Using the Kafka API from our JCG partner Chase Hooley at the Mapr blog. |
