In the first post of this series, we saw how to unit test Spark Streaming operations using Spark Testing Base. Here we’ll see how to do integration testing using Docker Compose.
What is Integration testing
We previously saw a discussion about unit and integration testing. Again, as we want to keep the post focused, we’ll work with a definition of integration testing that holds these characteristics:
- Network integration: our code should call the network to integrate with the third party dependencies. Part of our integration test effort will be then verifying the behaviour of our code in the presence of network issues.
- Framework integration: frameworks try to produce predictable and intuitive APIs. However, that’s not always the case and integration testing gives us verification about our assumptions.
What is Docker Compose
Docker provides a lightweight and secure paradigm for virtualisation. As a consequence Docker is the perfect candidate to set up and dispose container(processes) for integration testing. You can wrap your application or external dependencies in Docker containers and managing their lifecycle with ease.
Orchestrating the relationships, order of execution or shared resources of a bunch of containers could be cumbersome and tedious. Instead of baking our own solutions with Bash scripts, we can use Docker Compose.
Controlling the lifecycle
Managing how and when a process should start, stop or move into different states is part of the process lifecycle management. Let’s make some considerations about this management when integration testing.
- If the process is expensive to set up, from time or space point of view, maintaining the process started for the whole test suite could be convenient.
- That might be problematic if the process is stateful. If that’s the case we need to be sure that the data is partitioned between tests, so tests won’t step on each other toes.
- If isolating data becomes too complicated, we can dispose the process associated with every test or logical group of tests, in order to be sure that we work with a clean slate.
- Another approach is deleting the data generated by the test. Deleting the data after the test has the following problems: harder to diagnose if the test fails and risk of not deleting data if the test fails catastrophically in the middle. My preferred approach is deleting the data before starting every test.
- Being sure that a process has ‘spun up’ completely is hard to say. Some processes could be up with a PID assigned but not ready to receive messages until some warm up happens. That complicates massively the management as there is no general solution.
Coupling testing dependencies with your build system.
In this post we’re going to explore Docker Compose to control external dependencies. Docker Compose is a lightweight way of packaging applications, but even that it takes some time to start the containers (often related with the startup time of the processes themselves).
Therefore we’ll go with the approach of starting the containers once per test suite.
plugins.sbt
addSbtPlugin("com.tapad" % "sbt-docker-compose" % "1.0.11")build.sbt
lazy val dockerComposeTag = "DockerComposeTag" enablePlugins(DockerComposePlugin) testOptions in Test += Tests.Argument(TestFrameworks.ScalaTest, "-l", dockerComposeTag), composeFile := baseDirectory.value + "/docker/sbt-docker-compose.yml", testTagsToExecute := dockerComposeTag )
I’ve copied the most relevant bits from our example. As you can see, we’re using sbt-docker-compose library. That means that we’re coupling our tests (at least their dependencies) with the build system (sbt). That could be a problem as we’re locked-in our solution to this particular build provider, but as usual, there is a trade-off in every technical decision.
Every test that is tagged with DockerComposeTag will be executed when running sbt dockerComposeTest. This command will set up and tear down the containers defined in sbt-docker-compose.yml:
version: '2'
services:
cassandra:
image: cassandra:2.1.14
ports:
- "9042:9042"
kafka:
image: spotify/kafka:latest
ports:
- "9092:9092"
- "2181:2181"
environment:
ADVERTISED_HOST: localhost # this must match the docker host ip
ADVERTISED_PORT: 9092Writing a Spark Streaming integration test
Now that we have our test infrastructure ready, we can write our first integration test. Let’s remember the code that we want to test:
val lines = ingestEventsFromKafka(ssc, brokers, topic).map(_._2)
val specialWords = ssc.sparkContext.cassandraTable(keyspace, specialWordsTable)
.map(_.getString("word"))
countWithSpecialWords(lines, specialWords)
.saveToCassandra(keyspace, wordCountTable)def countWithSpecialWords(lines: DStream[String], specialWords: RDD[String]): DStream[(String, Int)] = {
val words = lines.flatMap(_.split(" "))
val bonusWords = words.transform(_.intersection(specialWords))
words.union(bonusWords)
.map(word => (word, 1))
.reduceByKey(_ + _)
}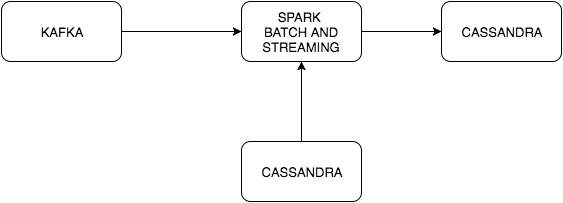
Events are received from Kafka, that stream is joined with a Cassandra table that contains special words. Those events contains words separated by space and we want to count (if a word appears twice) the words on that stream. There are two external dependencies so our sbt-docker-compose.yml will have to start those for us.
class WordCountIT extends WordSpec
with BeforeAndAfterEach
with Eventually
with Matchers
with IntegrationPatience {
object DockerComposeTag extends Tag("DockerComposeTag")
var kafkaProducer: KafkaProducer[String, String] = null
val sparkMaster = "local[*]"
val cassandraKeySpace = "kafka_streaming"
val cassandraWordCountTable = "word_count"
val cassandraSpecialWordsTable = "special_words"
val zookeeperHostInfo = "localhost:2181"
val kafkaTopic = "line_created"
val kafkaTopicPartitions = 3
val kafkaBrokers = "localhost:9092"
val cassandraHost = "localhost"
override protected def beforeEach(): Unit = {
val conf = new Properties()
conf.put("bootstrap.servers", kafkaBrokers)
conf.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
conf.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
kafkaProducer = new KafkaProducer[String, String](conf)
}We defined a test with WordSpec from ScalaTest. The rest of the code is basically preparation for our test.
"Word Count" should {
"count normal words" taggedAs (DockerComposeTag) in {
val sparkConf = new SparkConf()
.setAppName("SampleStreaming")
.setMaster(sparkMaster)
.set(CassandraConnectorConf.ConnectionHostParam.name, cassandraHost)
.set(WriteConf.ConsistencyLevelParam.name, ConsistencyLevel.LOCAL_ONE.toString)
eventually {
CassandraConnector(sparkConf).withSessionDo { session =>
session.execute(s"DROP KEYSPACE IF EXISTS $cassandraKeySpace")
session.execute(s"CREATE KEYSPACE IF NOT EXISTS $cassandraKeySpace WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 };")
session.execute(
s"""CREATE TABLE IF NOT EXISTS $cassandraKeySpace.$cassandraWordCountTable
|(word TEXT PRIMARY KEY,
|count COUNTER);
""".stripMargin
)
session.execute(
s"""CREATE TABLE IF NOT EXISTS $cassandraKeySpace.$cassandraSpecialWordsTable
|(word TEXT PRIMARY KEY);
""".stripMargin
)
session.execute(s"TRUNCATE $cassandraKeySpace.$cassandraWordCountTable;")
session.execute(s"TRUNCATE $cassandraKeySpace.$cassandraSpecialWordsTable;")
}
createTopic(zookeeperHostInfo, kafkaTopic, kafkaTopicPartitions)
val ssc = new StreamingContext(sparkConf, Seconds(1))
SampleStreaming.start(ssc, kafkaTopic, kafkaTopicPartitions, cassandraHost, kafkaBrokers,
cassandraKeySpace, cassandraWordCountTable, cassandraSpecialWordsTable)
import ExecutionContext.Implicits.global
Future {
ssc.awaitTermination()
}
produceKafkaMessages()
eventually {
ssc.cassandraTable(cassandraKeySpace, cassandraWordCountTable).cassandraCount shouldEqual 2
}
}
}
}There is plenty of noise but this test is basically doing the following:
- Setting up a Spark Conf. We need to do it first as it’s needed for spark-cassandra-connector
- Executing some DDLs and DMLs in Cassandra. Keyspace and tables if they don’t exist yet, and truncating the tables just in case, so we can start with a clean slate. In this particular example we just want to count the number of rows generated, so we don’t care about special words, but it would be easier to populate that table with data.
- We create the Kafka topic that Spark Streaming will use to ingest data from.
def createTopic(zookeeperHostInfo: String, topic: String, numPartitions: Int) = {
val timeoutMs = 10000
val zkClient = new ZkClient(zookeeperHostInfo, timeoutMs, timeoutMs, ZKStringSerializer)
val replicationFactor = 1
val topicConfig = new Properties
AdminUtils.createTopic(zkClient, topic, numPartitions, replicationFactor, topicConfig)
}- We start our spark streaming application, using a spark streaming context.
- Now that our spark streaming is ready to consume messages, we publish a single message into that Kafka topic.
def produceKafkaMessages() = {
val record = new ProducerRecord[String, String](kafkaTopic, "Hi friend Hi")
kafkaProducer.send(record)
}- The result of this computation will look something like: Hi -> 2, friend -> 1. That’s two rows in the ‘word_count’ table in Cassandra. And that’s the assertion that we’ll do finally in our test (in a real application the assertion would be more meaty, but the example just show a point).
Conclusion
Even if it seems plenty of code, most of the bits for integration testing spark streaming applications are related with setting up the data in the external dependencies. These tests will be a pleasure to work with, using the proper abstractions.
In the next post we’ll see how to do integration testing without Docker Compose, controlling those dependencies directly from ScalaTest.
| Reference: | Testing Spark Streaming: Integration testing with Docker Compose from our JCG partner Felipe Fernandez at the Crafted Software blog. |
