How can serverless computing help your production infrastructure?
The serverless computing architecture has been gaining attention during the past few years, since it’s focused on one of the major components in an application: the servers. This architecture takes a different approach.
In the following post we’ll explain what it means to go serverless, and try to understand if and when it can help your application. Buckle up.
The Cloud’s New Clothes
The concept of serverless computing talks about deploying code, not servers. It might sound a little confusing at first, since it implies that you can discard your servers as a whole and run your app without them. But as you can guess, that’s not really the case here.
Instead of purchasing, managing and scaling them, the cloud provider is the one handling the requests made to the VMs. So you still need servers, but this new model takes the responsibility away from you. Or in other words, there’s no hassle in dealing with deployments onto servers or installed software of any kind. Basically, all you need is a managed cloud service and a computer.
Enter AWS Lambda
This model was first introduced by Amazon, as AWS Lambda in 2014. The company was the first to offer the serverless service, as part of the Amazon Web Services suite.
AWS Lambda is based on an event-driven platform, triggered by events such as signups, updates and so on. When an event happens, it will call the relevant functions that in turn, will run the code. All this, while managing and computing the resources required to run and using only them.
In other words, the basic workflow stays the same: write code, upload it to a server for it to run, and remove the concerns about response time, operations and so on.
AWS Lambda is sometimes referred to as Function as a Service (FaaS), since the events trigger the relevant functions needed to proceed the requests, allowing us to run our functions without the hassle behind it.
Along with FaaS, the serverless architecture is also known as Backend as a Service (BaaS), that removes a significant part of the database administration overhead, and provide authorization for different users and levels.
Tim Wagner, General Manager of AWS Lambda shared a diagram that illustrates the components and their connections: a Lambda function as the compute resource (“backend”) and a mobile app that connects directly to it, plus Amazon API Gateway to provide an HTTP endpoint for a static Amazon S3-hosted website:
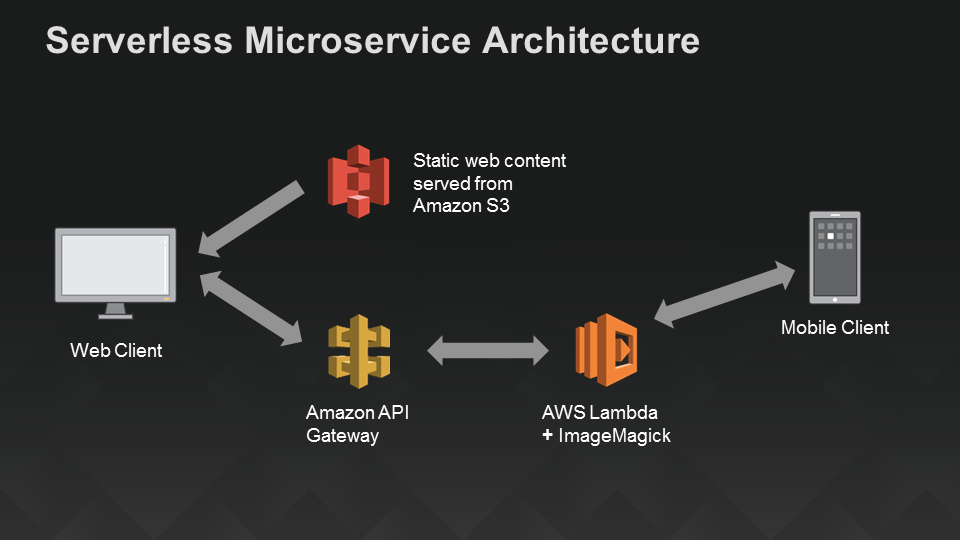
Taking Care of Your Code
AWS Lambda’s main goal is allowing developers to build smaller, on-demand and event-responsive applications in a simple way. It works for you and manages the “compute fleet” that balance memory, CPU, network, apply security patches, monitor health and any other resources and actions needed.
A nice way to look at it is as an outsourcing service. Not only it “relocates the IT”, it can even help you reduce operational costs, since you can remove infrastructure costs and even cut down on the amount of team members needed to maintain the servers.
Speaking of costs, you only pay for what you use, based on the number of requests for your functions and the time your code executes. And it’s important to state that the free tier includes 1M free requests per month and and up to 3.2 million seconds of compute time per month.
The calculation of each request is counted from when it starts executing as a response to an event or invoke call. And that also includes tests from the console.
According to Amazon, AWS Lambda is the platform for many application scenarios. But of course, there’s a catch, this statement is only relevant to the languages supported by AWS Lambda: Node.js, Java, and Python.
On the bright side, building AWS Lambda functions with Java can be done with the tools you already know, Maven or Gradle, and the build process remains pretty much the same.
Show Me the Code
Invoking an AWS Lambda function is pretty easy after a basic setup and you can view the full explanation here.
It includes defining POJOs that represent the input and output JSON, specifying an interface that represents our microservice and annotate it with the name of the Lambda function to invoke when it’s called.
The next step will be using the LambdaInvokerFactory to create an implementation of this interface. This will allow us to make calls to the service that’s running on Lambda. Then we can simply invoke our service using this proxy object, like… counting cats:
CountCatsInput input = new CountCatsInput();
input.setBucketName("pictures-of-cats");
input.setKey("three-cute-cats");
int cats = catService.countCats(input).getCount();Before You Start…
Of course, nothing is perfect and the option to focus mainly on code comes with a few drawbacks. Since it’s still a pretty new technology, it’s easy finding a list of issues that the users are not quite happy about, such as:
Control – You’re “handing away” your servers in hope your cloud host will handle them the best way possible. But you might experience major issues that you’ll have to sit back and wait for them to work out, and that may even include downtime and unhappy customers.
Locked-In – Speaking of handing everything to your cloud host, using AWS Lambda means you have to use AWS. It might not be an issue right now, but it will become one if you ever think about moving to Google or simply using your own servers.
Flexibility – You won’t be able to login to compute instances, or customize the operating system or language runtime.
Security – Using a 3rd party also means using his security. We’re not saying AWS is not secure, but you’re passing on this responsibility completely to a 3rd party which can be less than ideal. .
Monitoring – With AWS Lambda you can monitor and debug your system only with the in-house tool, CloudWatch. While you can still create custom alarms, view request rates and error rates – it’s a pretty basic tool, and it might not help you understand the root cause of your problems.
And that’s just a small (but important) part of the downsides this architecture has. It’s also important to point out that if you already have an application and you would like to migrate it to a serverless architecture, you might find yourself writing it from scratch. So you might have to think it over or simply backlog it to the next new app you’re planning on working on.
Final Thoughts
Amazon started a serverless movement with AWS Lambda and nowadays other companies such as Microsoft, Google, IBM and others offer this model as well as small companies and startups.
If we had to gamble, we’d say that serverless is the future. If you think about it, it’s the next step in the evolution of cloud computing, that’s leading us to put our full trust in the cloud and the providers other than in ourselves.
For now, it’s better to hold onto your current cloud or on-premise servers. It’s still a new technology and there are a few bumps Amazon, Google and others have to go through before we can ditch our servers. It might be baby steps, but we’re heading in this direction, whether we like it or not.
| Reference: | AWS Lambda for Serverless Java Developers: What’s in It for You? from our JCG partner Henn Idan at the Takipi blog. |
