Continuing on with my series about microservices implementations (see “Why Microservices Should Be Event Driven”, “Three things to make your microservices more resilient”, “Carving the Java EE Monolith: Prefer Verticals, not Layers” for background) we’re going to explore probably the hardest problem when creating and developing microservices. Your data. Using Spring Boot/Dropwizard/Docker doesn’t mean you’re doing microservices. Taking a hard look at your domain and your data will help you get to microservices.
Follow along for the rest of the series (twitter: @christianposta, RSS/blog: blog.christianposta.com)
Of the reasons we attempt a microservices architecture, chief among them is allowing your teams to be able to work on different parts of the system at different speeds with minimal impact across teams. So we want teams to be autonomous, capable of making decisions about how to best implement and operate their services, and free to make changes as quickly as the business may desire. If we have our teams organized to do this, then the reflection in our systems architecture will begin to evolve into something that looks like microservices.
To gain this autonomy, we need to “shed our dependencies” but that’s a lot easier to say than do. I’ve seen folks refer to this idea in part, trivially, as “each microservice should own and control its own database and no two services should share a database.” The idea is sound: don’t share a single database across services because then you run into conflicts like competing read/write patterns, data-model conflicts, coordination challenges, etc. But a single database does afford us a lot of safeties and conveniences: ACID transactions, single place to look, well understood (kinda?), one place to manage, etc. So when building microservices how do we reconcile these safeties with splitting up our database into multiple smaller databases?
Let’s see. First, for an “enterprise” building microservices, we need to make the following things clear:
- What is the domain? What is reality?
- Where are the transactional boundaries?
- How should microservices communicate across boundaries?
- What if we just turn the database inside out?
What is the domain?
This seems to be ignored at a lot of places but is a huge difference between how the internet companies practice microservices and how a traditional enterprise may (or may fail because of neglecting this) implement microservices.
Before we can build a microservice, and reason about the data it uses (produces/consumes, etc) we need to have a reasonably good, crisp understanding about what that data is representing. For example, before we can store information into a database about “bookings” for our TicketMonster and its migration to microservices, we need to understand “what is a booking”. Just like in your domain, you may need to understand what is an Account, or an Employee, or a Claim, etc.
To do that we need to dig into what is “it” in reality? For example, “what is a book”? Try to stop and think about that, as it’s a fairly simple example. Try to think what is a book. How would we express this in a data model?
Is a book something with pages? Is a newspaper a book (it has pages)? So maybe a book has a hard cover? Or is not something that’s released/published every day? If I write a book (which I did :) Microservices for Java Developers) the publisher may have an entry for me with a single row representing my book. But a bookstore may have 5 of my books. Is each one a book? Or are they copies? How would we represent this? What if a book is so long it has to be broken down into volumes? Is each volume a book? Or all of them combined? What if many small compositions are combined together? Is the combination the book? Or each individual one? So basically I can publish a book, have many copies of it in a bookstore, each one with multiple volumes. So what is a book then?
The reality is there is no reality. There is no objective definition of “what is a book” with respect to reality so to answer any question like that, we have to know “who’s asking the question and what is the context”. Context is king. We as humans can quickly (and even unconsciously) resolve the ambiguity of this understanding because we have a context in our heads, in the environment, and in the question. But a computer doesn’t. We need to make this context explicit when we build our software and model our data. Using a book is to illustrate this is simplistic. Your domain (an enterprise) with its Accounts, Customers, Bookings, Claims, etc is going to be far more complicated and far more conflicting/ambiguous. We need boundaries.
Where do we draw the boundaries? The work in the Domain Driven Design community helps us deal with this complexity in the domain. We draw a bounded context around Entities, Value Objects, and Aggregates that *model** our domain. Stated another way, we build and refine a model that represents our domain and that model is contained within a boundary that defines our context. And this is explicit. These boundaries end up being our microservices, or, the components within the boundaries end up being microservices, or both. Either way, microservices is about boundaries and so is DDD.
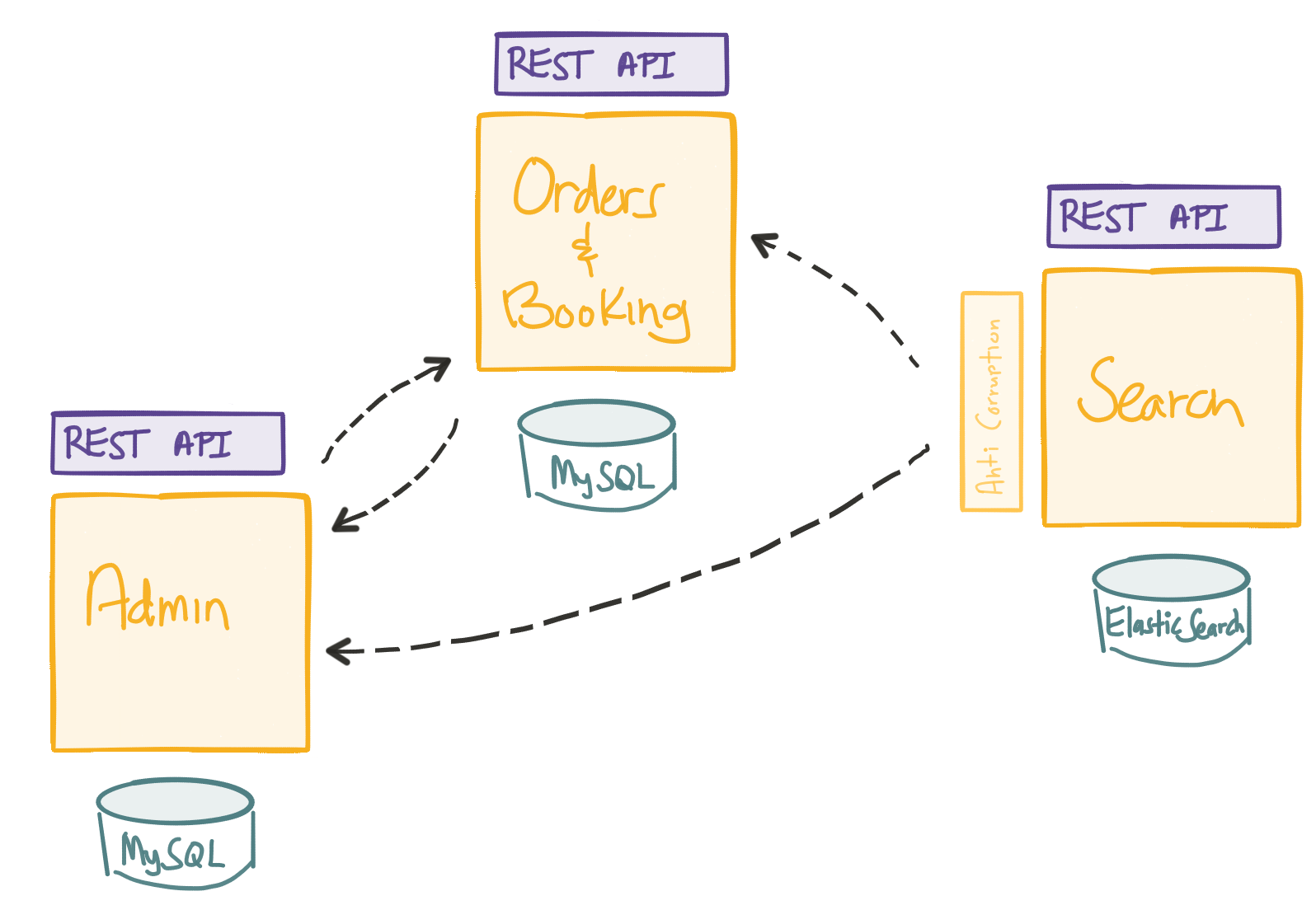
Our data model (how we wish to represent concepts in a physical data store…note the explicit difference here) is driven by our domain model, not the other way around. When we have this boundary, we know, and can make assertions, about what is “correct” in our model and what is incorrect. These boundaries also imply a certain level of autonomy. Bounded context “A” may have a different understanding of what a “book” is than bounded context “B” (eg, maybe bounded context “A” is a search service that searches for titles where a single title is a “book”; maybe bounded context “B” is a checkout service that processes a transaction based on how many books (titles+copies) you’re buying, etc).
You may stop and say “wait a minute… Netflix doesn’t say anything about Domain Driven Design… Neither does Twitter.. nor LinkedIn… why should I listen to this about DDD”?
Well here’s why:
“People try to copy Netflix, but they can only copy what they see. They copy the results, not the process” – Adrian Cockcroft, former Netflix Chief Cloud Architect
The journey to microservices is just that: a journey. It will be different for each company. There are no hard and fast rules, only tradeoffs. Copying what works for one company just because it appears to work at this one instant is an attempt to skip the process/journey and will not work. And the point to make here is that your enterprise is NOT Netflix. In fact, I’d argue that for however complex the domain is at Netflix, it’s NOT as complicated as it is at your legacy enterprise. Searching for and showing movies, posting tweets, updating a linkedIn profile, etc are all a lot simpler than your Insurance Claims Processing systems. These internet companies went to microservices because of speed to market and sheer volume/scale (posting a tweet to twitter is simple…. posting tweets and displaying tweet streams for 500 million users is incredibly complex). Enterprises today are going to have to confront complexity in BOTH the domain as well as scale. So accept the fact that this is a journey that balances domain, scale, and organizational changes. It will be different for each organization. Don’t ignore it.
What are the transactional boundaries?
Back to the story. We need something like domain driven design to help us understand the models we’ll use to implement our systems and draw boundaries around these models within a context. So we accept that a Customer, Account, Booking, etc may mean different things to different bounded contexts. But at the end of the day, we may end up with these related concepts distributed around our architecture but we need some way to reconcile changes across these different models when changes happen. We need to account for this, but first we need to identify our transactional boundaries.
Unfortunately, we as developers still seem to approach building distributed systems all wrong: we still look through the lens of one, single, relational, ACID, database. We also ignore the perils of an asynchronous, unreliable networks. To wit, we do things like write fancy frameworks that keep us from having to know anything about the network (including RPC frameworks, database abstractions that also ignore the network) and try to implement everything with point-to-point synchronous invocations (REST, SOAP, other CORBA like object serialization RPC libraries, etc). We build systems without regard to authority vs autonomy and end up trying to solve the distributed data problem with things like two-phase commit across lots of independent services. Or we ignore these concerns all together? This mindset leads to building very brittle systems that don’t scale…And it doesn’t matter if you call it SOA, Microservices, Miniservices, whatever.
So what do I mean by transactional boundaries? I mean the smallest unit of atomicity that you need with respect to the business invariants. Whether you use a database’s ACID properties to implement the atomicity or a two-phase commit, etc, doesn’t really matter. The point is we want to make these transactional boundaries as small as possible (ideally a single transaction on a single object: Vernon Vaughn has a series of essays describing this approach with DDD Aggregates ) so we can scale. When we build our domain model, using DDD terminology, we identify Entities, Value Objects and Aggregates. Aggregates in this context are objects that encapsulate other Entities/Value Objects and are responsible for enforcing invariants (there can be multiple Aggregates within a Bounded Context).
For example, let’s say we have the following use cases:
- “allow customers to search for flights”
- “allow a customer to pick a seat on a particular flight”
- “allow customer to book a flight”
We’d probably have three bounded contexts here: Search, Booking, and Ticketing (we’d likely have lots more like Payments, Loyalty, StandBy, Upgrades, etc but we’ll keep it narrowed to these three) . Search is responsible for showing flights for specific routes and itineraries for a given time frame (range of days, times, etc). Booking will be responsible for teeing up the Booking process with customer information (name, address, frequent flyer number, etc), seat preferences, and payment information. Ticketing would be responsible for actually settling the reservations with the airline and issuing a Ticket. Within each Bounded Context, we want to identify transactional boundaries where we can enforce constraints/invariants. We will not consider atomic transactions across bounded contexts (we’ll discuss this in the next section).
How would we model this considering we want small transaction boundaries (this is a very simplified version of booking a flight btw)? Maybe a Flight aggregate that encapsulates values like Time, Date, Route and entities like Customers, Planes, and Bookings? This seems to make sense: a flight has a plane, seats, customers, and bookings. The Flight aggregate is responsible for keeping track of Planes, Seats, etc for the purposes of creating Bookings. This may make some sense from a data model standpoint inside of a database (nice relational model with constraints and foreign keys, etc), or make a nice object model (inheritance/composition) in our source code, but let’s look at what happens.
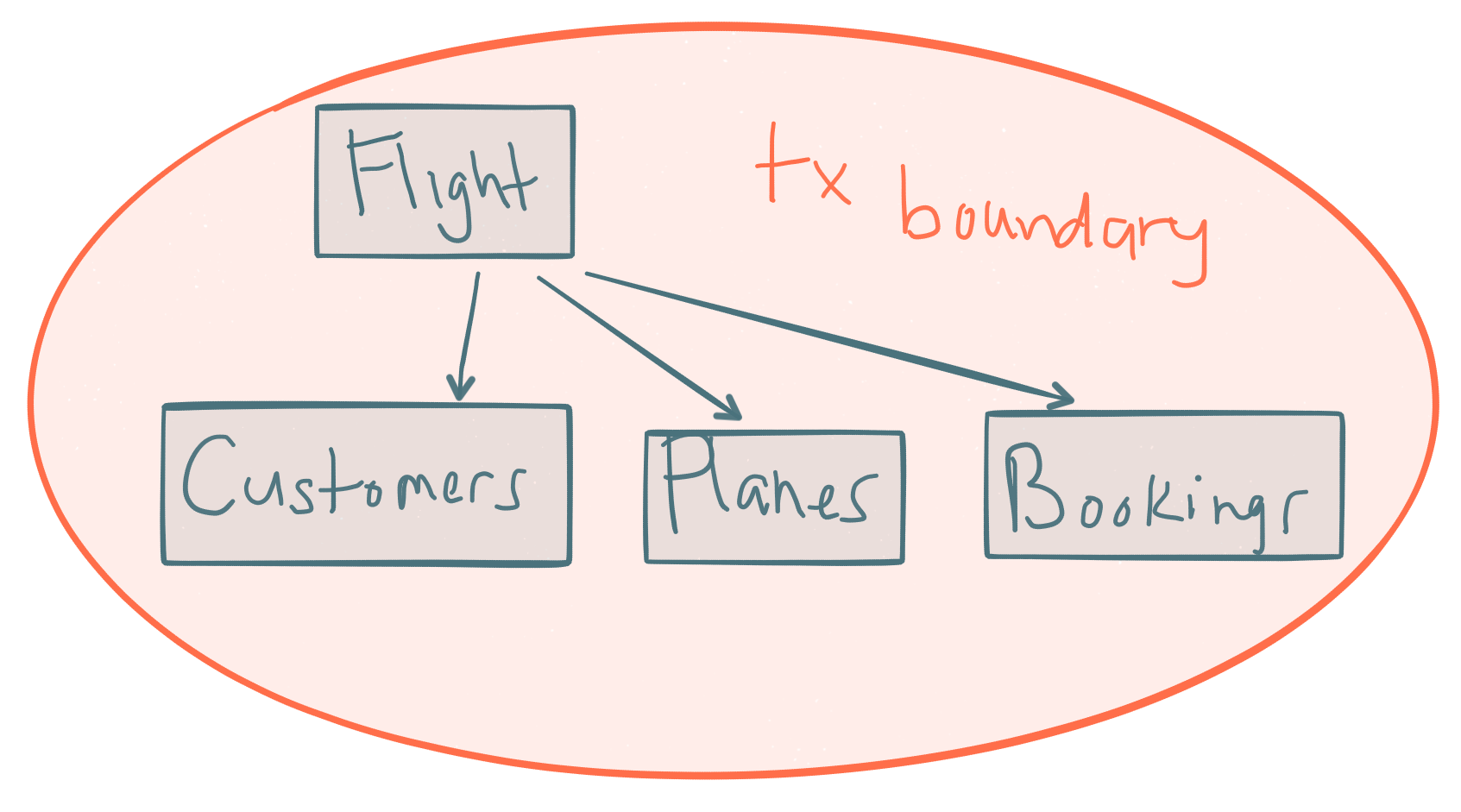
Are there really invariants across all Bookings, Planes, Flights etc just to create an Booking? That is, if we add a new Plane to the Flight aggregate, should we really include Customers and Bookings in that transaction? Probably not. What we have here is an Aggregate built with compositional and data model conveniences in mind. However, the transactional boundaries are too big. If we have lots of changes to flights, seats, Bookings, etc, we’ll have a lot of transactional conflicts (whether using optimistic or pessimistic locking won’t matter). And that obviously doesn’t scale (never mind failing orders all the time just because a flight schedule is changing being a terrible customer experience).
What if we broke the transactional boundaries a little smaller.
Maybe Booking, SeatAvailability, and Flights are their own independent aggregates. A Booking encapsulates customer information, preferences and maybe payment information. The SeatAvailability aggregate encapsulates planes and plane configurations. Flights aggregate is made up of schedules, routes, etc. … but we can proceed with creating bookings without impacting transactions on Flight Schedules and Planes/SeatAvailability. From a domain perspective, we want to be able to do that. We don’t need 100% strict consistency across planes/flights/bookings, but we do want to correctly record Flight schedule changes as an admin, Plane configurations as a vendor, and Bookings from customers. So how do we implement things like “pick a particular seat” on a flight?
During the booking process we may call into the SeatAvailability aggregate and ask it to reserve a seat on a plane. This seat reservation would be implemented as a single transaction, for example, (hold seat 23A) and return a reservation ID. We can associate this reservation ID with the Booking and submit the Booking knowing the seat was at one point “reserved”. Each of these (reserve a seat, and accept a booking) are individual transactions and can each proceed independently without any kind of two-phase commit or two-phase locking. Note using a “reservation” here is a business requirement. We don’t do seat assignment here, we just reserve the seat. This requirement would need to be fettered out potentially through iterations of the model because the language for the use case at first may simply say “allow a customer to pick a seat”. A developer could try to infer that the requirement means “pick from the remaining seats, assign this to the customer, remove it from inventory, and don’t sell more tickets than seats”. This would be extra, unnecessary invariants that would add additional burden to our transactional model which the business doesn’t really hold as an invariant. The business is certainly okay taking bookings without complete seat assignments and even overselling the flight.
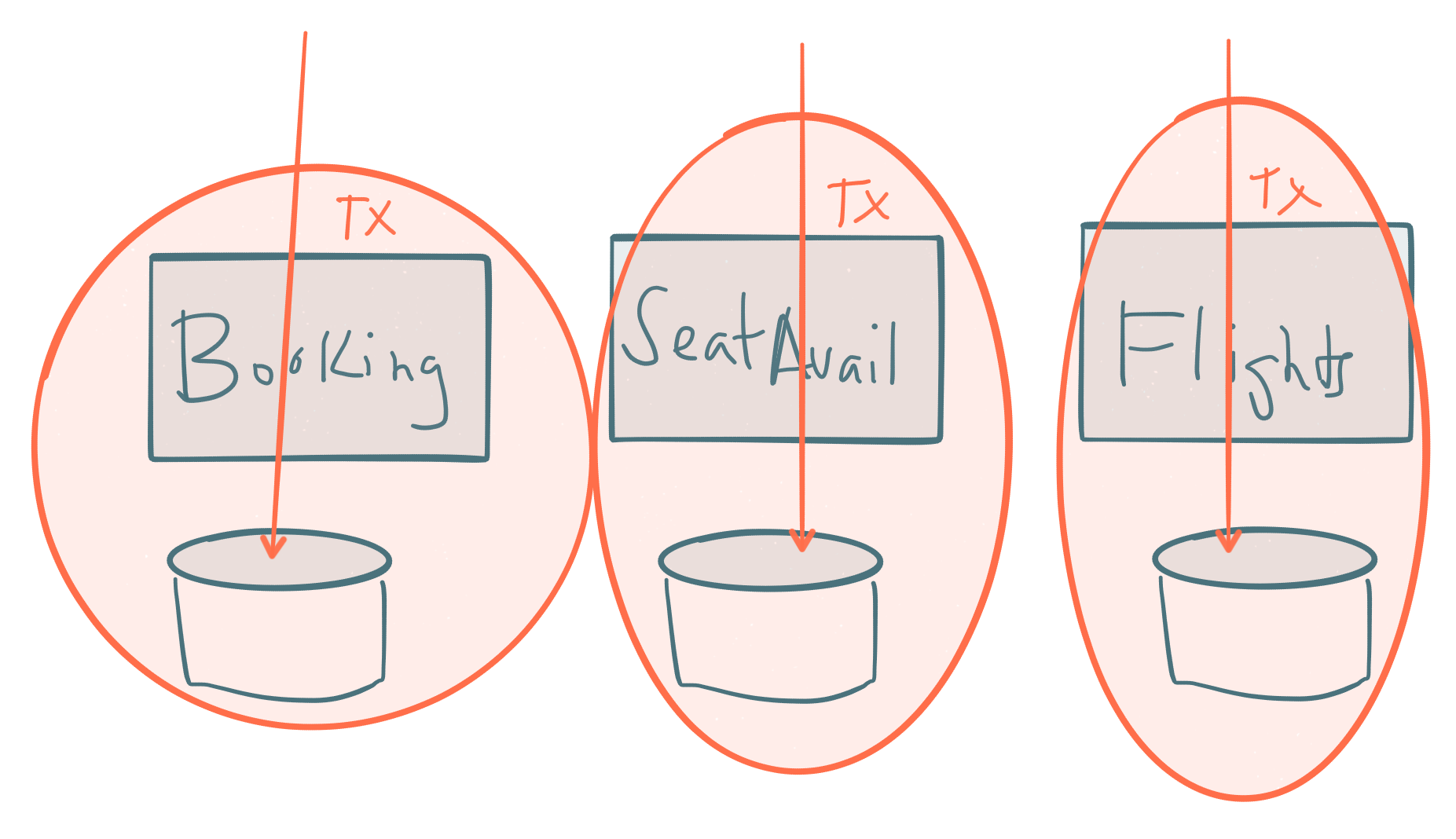
This is an example of allowing the true domain guide you toward smaller, simplified, yet fully atomic transactional boundaries for the individual aggregates involved. The story cannot end here though because we now have to rectify the fact that there are all these individual transactions that need to come together at some point. Different parts of the data are involved (ie, I created a booking and seat reservations, but these are not settled transactions wrt to getting a boarding pass/ticket, etc.)
How should microservices communicate across boundaries?
We want to keep the true business invariants in tact. With DDD we may chose to model these invariants as aggregates and enforce them using single transactions for an aggregate. There may be cases where we’re updating multi-aggregates in a single transaction (across a single database or multiple databases) but those scenarios would be the exception. We still need to maintain some form of consistency between aggregates (and eventually between bounded contexts) so how should we do this?
One thing we should understand: distributed systems are finicky. There are very few guarantees if any we can make about anything in a distributed system in bounded time (things WILL fail, things are non-deterministically slow or appear to have failed, systems have non-synchronized time boundaries, etc), so why try to fight it? What if we embrace this and bake it into our consistency models across our domain? What if we say “between our necessary transactional boundaries we can live with other parts of our data and domain to be reconciled and made consistent at some later point in time”?
As we’ve been saying, for microservices we value autonomy. We value being able to make changes independent of other systems (in terms of availability, protocol, format, etc). This decoupling of time and any guarantees about anything between services in any bounded time allows us to truly achieve this sort of autonomy (this is not unique to computer systems… or any systems for that matter. So I say, between transaction boundaries and between bounded contexts, use events to communicate consistency. Events are immutable structures that capture an interesting point in time that should be broadcast to peers. Peers will listen to the events in which they’re interested and make decisions based on that data, store that data, store some derivative of that data, update their own data based on some decision made with that data, etc, etc.
Continuing the Flight booking example I somehow started (lol instead of using my TicketMonster example… that’s what happens when I start writing!), when a booking is stored via an ACID-style transaction, how do we end up Ticketing that? That’s where the aforementioned Ticketing bounded context comes in. The Booking bounded context would publish an event like “NewBookingCreated” and the Ticketing Bounded Context would consume that event and proceed to interact with the backend (potentially legacy) ticketing systems. This obviously requires some kind of integration and data transformation which something Apache Camel would be great at. It also brings up some other questions. How do we do a write to our database AND publish to a queue/messaging appliance atomically? And what if we have ordering requirements/causal requirements between our events? And what about one database per service?
Ideally our Aggregates would use commands and domain events directly (as a first class citizen.. .that is, any operation is implemented as commands, and any response is implemented as reacting to events) and we could more cleanly map between the events we use internal to our bounded context and those we use between contexts. We could just publish events (ie, NewBookingCreated) to a messaging queue and then have a listener consume this from the queue and insert it idempotently into the database without having to use XA/2PC transactions instead of inserting into the database ourselves. We could insert the event into an dedicated event store that acts like both a database and a messaging publish-subscribe topic (this is probably the preferred route). Or you can just continue to use an ACID database and stream changes to that database to a persistent, replicated log like Apache Kafka using something like Debezium and deduce the events using some kind of event processor/steam processor. Either way, the point is we want to communicate between boundaries with immutable point in time events.
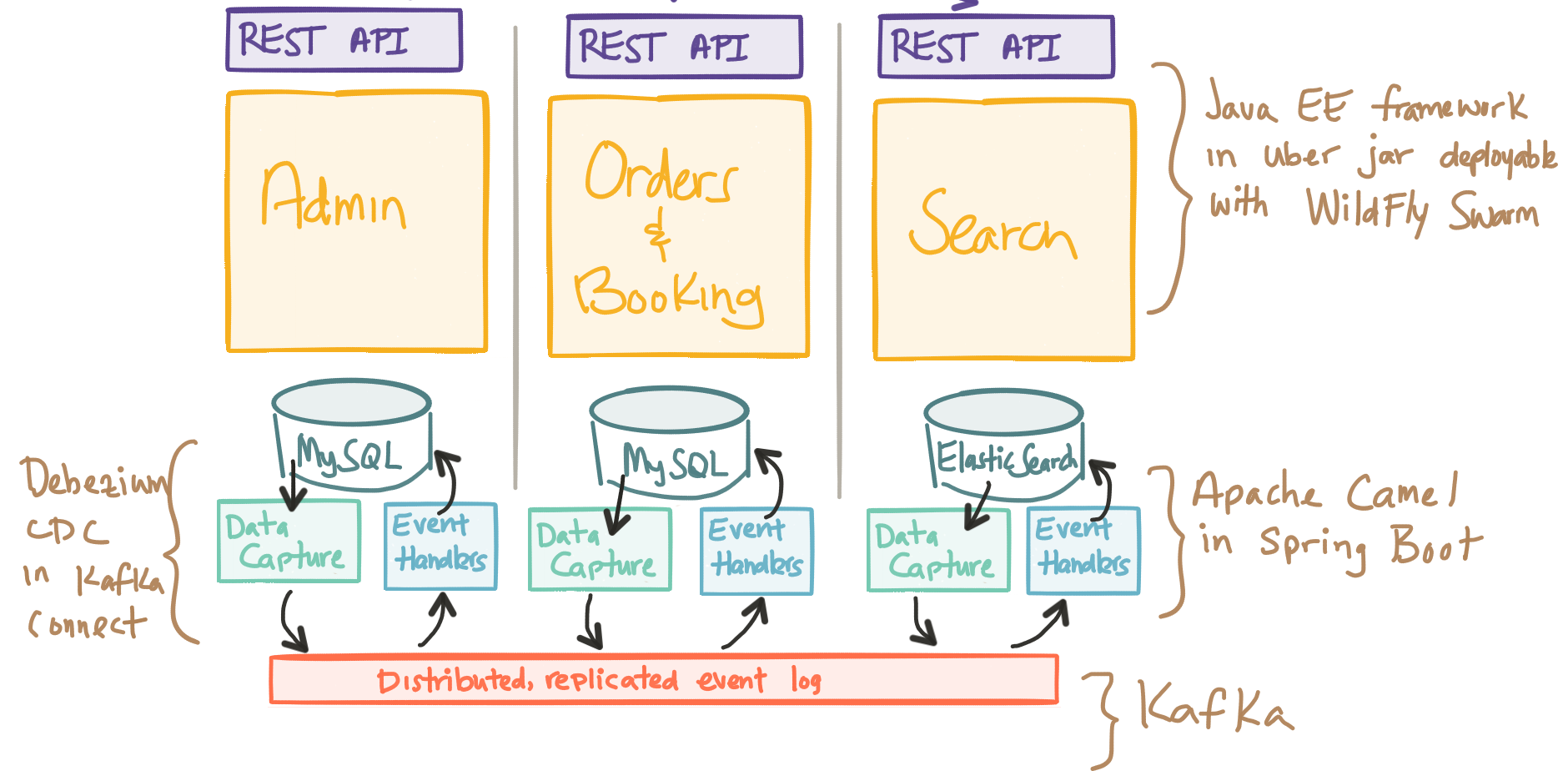
This comes with some great advantages:
- we avoid expensive, potentially impossible transaction models across boundaries
- we can make changes to our system without impeding progress of other parts of the system (timing and availability)
- we can decide how quickly or slowly we want to see the rest of the outside world and become eventually consistent
- we can store the data in our own databases however we’d like using the technology appropriate for our service
- we can make changes to our schema/databases at our leisure
- we become much more scalable, fault tolerant, and flexible
- you have to pay even more attention to CAP Theorem and the technologies you chose to implement your storage/queues
Noteably, this comes with disadvantages:
- it’s more complicated
- difficult to debug
- since you have a delay when seeing events, you cannot make any assumptions about what other systems know (which you cannot do anyway, but it’s more pronounced in this model)
- more difficult to operationalize
- you have to pay even more attention to CAP Theorem and the technologies you chose to implement your storage/queues
I listed “paying attention to CAP, et al” in both columns because although it places a bit more of a burden on you, it’s imperative that you do so anyway!! It’s imperative that we always pay attention to the different forms of data consistency and concurrency in our distributed data systems! Relying on “our database in ACID” is no longer acceptable (especially when that ACID database most likely defaults to some weak consistency anyway… so much for your ACID properties).
Another interesting concept that emerges from this approach is the ability to implement a pattern known as “Command Query Separation Responsibility” where we separate our read model and our write models into separate services. Remember we lamented the internet companies don’t have very complex domain models. This is evident in their write models being simple (insert a tweet into a distributed log for example). However their read models are crazy complicated because of their scale. CQRS helps separate these concerns. On the flip side, in an enterprise, the write models might be incredibly complicated while the read models may be simple flat select queries and flat DTO objects. CQRS is a powerful separation of concerns pattern to evaluate once you’ve got proper boundaries and a good way to propogate data changes between aggregates and between bounded contexts.
So what about a service has only one database and doesn’t share with any other service? In this scenario, we may have listeners that subscribe to the stream of events and may insert data into a shared database that the primary aggregates might end up using. This “shared database” is perfectly fine. Remember, there are no rules, just tradeoffs. In this instance we may have multiple services working in concert together with the same database and so long as we (our team) owns all the processes, we don’t negate any of our advantages of autonomy. Thusly when you hear someone say “a microservice should have its own database and not share it anyone else” you can respond “well, kinda” :)
What if we just turn the database inside out?
What if we take the concepts in the previous section to its logical extreme? What if we just say we’ll use events/streams for everything AND also persist these events forever? What if we say databases/caches/indexes are really just materialized views of a persistent log/stream of events that happened in the past, and the current state is a left fold over all of those events?
This approach brings even more benefits that you can add to the benefits of communicating via events (listed above):
- Now you can treat your database as a “current state” of record, not the true record
- You can introduce new applications and re-read the past events and examine their behaviors in terms of “what would have happened”
- You can perfect audit logging for free
- You can introduce new versions of your application and perform quite exhaustive testing on it by replaying the events
- You can more easily reason about database versioning/upgrades/schema changes by just replaying the events into the new database
- You can migrate to completely new database technology (ie, maybe you find you’ve outgrown your relational DB and you want to switch to a specialized database/index)
For more information on this, take a look at Martin Kleppmann’s talk/blog post titled “Turning the database inside-out with Apache Samza”

When you book a flight on aa.com, delta.com, or united.com, you’re seeing some of these concepts in action. When you choose a seat, you don’t actual get assigned it, you reserve it. When you book your flight, you don’t actually have a ticket. You get an email later telling you you’ve been confirmed/Ticketed. Have you ever had a plane change and be assigned a different seat for the actual flight? Or been to the gate and heard them ask for volunteers to give up their seat because they oversold the flight? These are all examples of transactional boundaries, eventual consistency, compensating transactions, and even apologies at work.
Moral of the story
The moral of the story here is that data, data integration, data boundaries, enterprise usage patterns, distributed systems theory, timing, etc, are all the hard parts of microservices (since microservices is really just distributed systems!). I’m seeing too much confusion around technology (“if i use Spring Boot i’m doing microservices”, “i need to solve service discovery, load balancing in the cloud before i can do microservices”, “i must have a single database per microservice”) and useless “rules” regarding microservices. Don’t worry. Once the big vendors have come and sold you all the fancy suites of products (mmm… SOA ring a bell), you’ll still be left to do the hard parts listed above.
| Reference: | The Hardest Part About Microservices: Your Data from our JCG partner Christian Posta at the Christian Posta – Software Blog blog. |
