This is the fifth post in the series about integrating sync clients with async systems (1, 2, 3, 4). Here we’ll see how to manage the actor’s lifecycle, so our service can use the available resources efficiently.
Lifecycle
Actors, threads, objects, resources… All of them have different states during their lifetime. Some of those states are internal and they shape the entity’s behaviour when receiving an external stimulus. However there are state transitions that should be handled by external entities: creation, error recovery and disposal.
Actor Pools
A long time ago dependency injection showed us that an object should not be in charge of creating its dependencies. Externalising those concerns into a factory makes code more testable, loosely coupled and readable. We’ll need different creation strategies irrespective of the use of DI frameworks or poor man’s dependency injection. Guice Scopes is a good example about how to create one instance per application (@Singleton) or one per scope (@SessionScoped and @RequestScoped).
Often system resources are scarce, expensive to create or they’re under heavy load. That means that we can’t afford neither a Singleton nor an unbounded creation strategy like Prototype in Spring. A good example is thread pools.
Using worker threads minimizes the overhead due to thread creation. Thread objects use a significant amount of memory, and in a large-scale application, allocating and deallocating many thread objects creates a significant memory management overhead.
Akka Actors are extremely lightweight. We could afford creating millions of them if we knew that they would be disposed quickly. However that’s not the case with our use case:
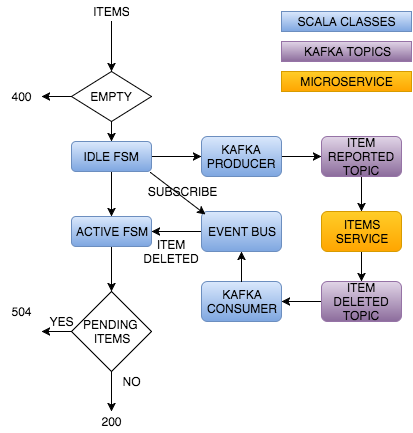
As you can see Finite State Machine (FSM) actors will wait until the Items service finishes deleting the items. It’s important to note that the actor is waiting, but not blocking. Actors are attached to Dispatchers that have a Thread Pool inside. Those thread pools have a limited number of threads; blocking one of the actors would mean running out of threads pretty quickly. In this particular example we want to bound the number of actors, not threads. Maybe it is overkill, but the point of this series is mainly educational. Let’s see a diagram of our service with the proper level of abstraction.
Akka HTTP
Akka HTTP is a library based on Spray to create HTTP integration layers. Akka HTTP offers a routing DSL extremely powerful and easy to read as you can see in our code:
val deleteItem = get {
path("item" / JavaUUID) { itemId =>
onComplete(deleteItem(itemId)) {
case Success(Result(Right(_))) =>
complete(StatusCodes.OK)
case Success(Result(Left(Timeout(errorMessage)))) =>
complete(StatusCodes.GatewayTimeout)
// many other cases we won't cover here
}
}
}
private def deleteItem(itemId: UUID)= itemCoordinator ask ItemReported(itemId)In this snippet I’d like to stress out ask vs tell pattern. Just to clarify, these are Akka patterns, nothing to do with the amazing Tell, don’t ask principle. The tell pattern involves firing a message and forgetting about the response. In this approach information flows in one direction. However for our scenario we’re interested in the ask pattern. When we send a message to an actor through ask pattern a future is created with an eventual response bounded by a timeout. As the documentation says:
Using ask will send a message to the receiving Actor as with tell, and the receiving actor must reply with sender() ! reply in order to complete the returned Future with a value. The ask operation involves creating an internal actor for handling this reply, which needs to have a timeout after which it is destroyed in order not to leak resources; see more below.
First actor ->
val future = myActor.ask("hello")(5 seconds)
Second actor ->
sender() ! resultCoordinating actors
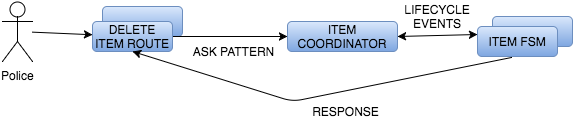
Let’s see Item Coordinator code:
override def receive: Receive = {
case itemReported: ItemReported =>
if (actorPool.isEmpty)
sender() ! Result(Left("No actors available"))
else {
actorPool.get() forward ItemReported
}
case Result(_) =>
sender() ! FlushItemFSM
actorPool.putBack(sender())
}sender method exposes the ActorRef of the actor that sent the message. If the actor pool is exhausted we need to communicate with the Route actor that we won’t able to serve the request. Otherwise we’ll retrieve one of the actors in the pool and we’ll forward the received message. Forward allows us to keep the original sender. The FSM will communicate the result of its work to the Route actor that is waiting bounded by the ask pattern.
The FSM needs a reference into the coordinator, as it’s responsible for managing the lifecycle of the FSMs. Coordinator sends a message to the FSM telling to flush its internal state. At the same time puts back the FSM into the pool.
Creating actors
Remember how the FSM notifies that its work has finished:
private def finishWorkWith(message: Any) = {
replyTo ! message
coordinator ! message
goto(Idle)
}replyTo is a variable that was initialised with sender() when receiving the first ItemReported message. Remember that the message was forwarded so the sender is the Route Actor. coordinator is an ActorRef that has been injected when the actor was created. We’re using poor man’s dependency injection for that purpose. Let’s see the definition of our actor factory:
lazy val itemFSMFactory: (ActorContext, ActorRef) => ActorRef =
(context, self) => {
val itemFSM = ItemFSM.props(itemReportedProducer, itemDeletedBus, coordinator = self)
context.actorOf(itemFSM)
}This factory will be called n times (depending on the size of the pool) when creating the Actor Pool.
Supervising actors
Our coordinator is in charge of the pool and what to do when the FSM finishes in an expected way. However we didn’t talk about what happens when our actor fails. Akka has a built-in mechanism for dealing with failures called supervision. There are different recovery strategies, we’ll go for the Restart strategy:
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 3, withinTimeRange = 15 seconds) {
case e: Exception =>
actorPool.putBack(sender())
SupervisorStrategy.Restart
}As the Restart strategy documentation says:
Discards the old Actor instance and replaces it with a new one, then resumes message processing.
This strategy has been defined in the coordinator. How can we specify that this coordinator is the parent of the FSM to be supervised? Remember how we created the FSM:
context.actorOf(itemFSM)
Let’s see the Scaladoc for actorOf :
Create new actor as the child actor of this context
itemFSMFactory is called in the scope of the coordinator. Every single actor has a context that includes the sender, self and different meta objects. Creating an actor using coordinator’s context binds those actors as parent-child.
Summary
Thanks to Akka constructs and patterns, and the functional and async goodies of Scala we could write coordination code quite easily. In the next post we’ll se how to test Akka.
Part 1 | Part 2 | Part 3 | Part 4
| Reference: | Coordination in Akka from our JCG partner Felipe Fernandez at the Crafted Software blog. |
