This is the fourth post in the series about integrating sync clients with async systems (1, 2, 3). Here we’ll try to understand how Kafka works in order to correctly leverage its publish-subscribe implementation.
Kafka concepts
According to the official documentation:
Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design.
Kafka runs as a cluster and the nodes are called brokers. Brokers can be leaders or replicas to provide high-availability and fault tolerance. Brokers are in charge of partitions, being the distribution unit where messages are stored. Those messages are ordered and they’re accessible by an index called offset. A set of partitions forms a topic, being a feed of messages. A partition can have different consumers, and they access to the messages using its own offset. Producers publish messages into Kafka topics. This diagram from Kafka’s documentation could help to understand this:
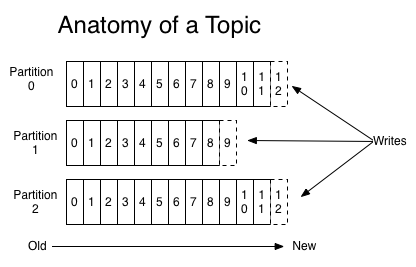
Queuing vs publish-subscribe
Consumer groups is another key concept and helps to explain why Kafka is more flexible and powerful than other messaging solutions like RabbitMQ. Consumers are associated to consumer groups. If every consumer belongs to the same consumer group, the topic’s messages will be evenly load balanced between consumers; that’s called a ‘queuing model’. By contrast, if every consumer belongs to different consumer group, all the messages will be consumed in every client; that’s called a ‘publish-subscribe’ model.
You can have a mix of both approaches, having different logical consumer groups, for different needs, and several consumers inside of every group to increase throughput through parallelism. Again, another diagram from Kafka’s documentation:
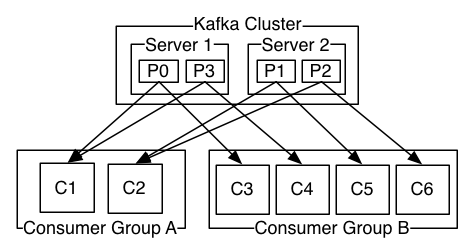
Understanding our needs
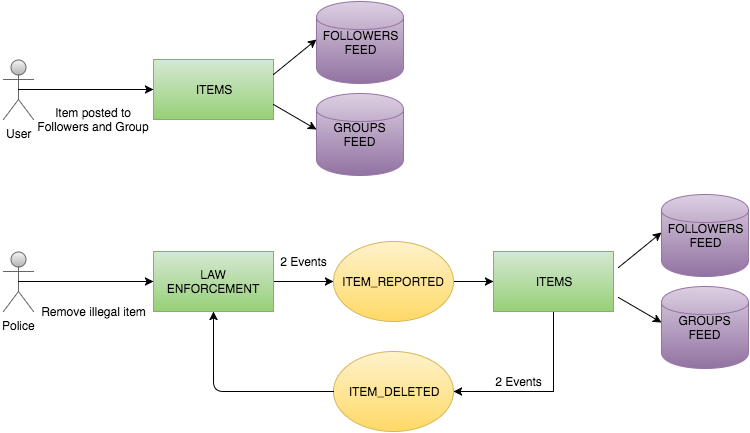
As we saw in previous posts (1, 2, 3) the Items service publishes messages into a Kafka topic called item_deleted. This message will live in one partition of the topic. To define in which partition the message will live, Kafka provides three alternatives:
- If a partition is specified in the record, use it
- If no partition is specified but a key is present choose a partition based on a hash of the key
- If no partition or key is present choose a partition in a round-robin fashion
We’ll use item_id as a key. Consumers contained in different instances of the Law Enforcement service are only interested in particular partitions, as they’re keeping internal state for some items. Let’s inspect different Kafka consumer implementations to see which is the most convenient for our use case.
Kafka Consumers
There are three consumers in Kafka: High level consumer, Simple Consumer and New Consumer
Out of the three consumers, Simple Consumer operates at the lowest-level. It meets our requirements as allows the consumer to “consume only a subset of the partitions in a topic in a process”. However, as the documentation says:
The SimpleConsumer does require a significant amount of work not needed in the Consumer Groups:
- You must keep track of the offsets in your application to know where you left off consuming
- You must figure out which Broker is the lead Broker for a topic and partition
- You must handle Broker leader changes
If you read the code suggested for handling those concerns, you’ll be quickly discouraged to use this consumer.
New Consumer offers the right level of abstraction and allows us to subscribe to specific partitions. They suggest the following use case in the documentation:
The first case is if the process is maintaining some kind of local state associated with that partition (like a local on-disk key-value store) and hence it should only get records for the partition it is maintaining on disk.
Unfortunately our system is using Kafka 0.8, and this consumer is only available from 0.9. We don’t have the resources to migrate to that version, so we’ll need to stick with High level consumer.
That consumer offers a nice API, but it doesn’t allow us to subscribe to specific partitions. That means that every instance of the Law Enforcement service will consume every message, even those that are not pertinent. We can achieve that by defining different consumer groups per instance.
Leveraging Akka Event Bus
In the previous post we have defined some Finite State Machine actor that is waiting for ItemDeleted messages.
when(Active) {
case Event(ItemDeleted(item), currentItemsToBeDeleted@ItemsToBeDeleted(items)) =>
val newItemsToBeDeleted = items.filterNot(_ == item)
newItemsToBeDeleted.size match {
case 0 => finishWorkWith(CensorResult(Right()))
case _ => stay using currentItemsToBeDeleted.copy(items = newItemsToBeDeleted)
}
}Our Kafka Consumer could forward every message to those actors and let them to discard/filter irrelevant items. However we don’t want to overwhelm our actors with redundant and inefficient work, so we’ll add a layer of abstraction that will let them discard the proper messages in a really efficient way.
final case class MsgEnvelope(partitionKey: String, payload: ItemDeleted)
class ItemDeletedBus extends EventBus with LookupClassification {
override type Event = MsgEnvelope
override type Classifier = String
override type Subscriber = ActorRef
override protected def mapSize(): Int = 128
override protected def publish(event: Event, subscriber: Subscriber): Unit = subscriber ! event.payload
override protected def classify(event: Event): Classifier = event.partitionKey
override protected def compareSubscribers(a: Subscriber, b: Subscriber): Int = a.compareTo(b)
}Akka Event Bus offers us subscription by partition that we’re missing in our Kafka High Level Consumer. From our Kafka Consumer we’ll publish every message into the bus:
itemDeletedBus.publish(MsgEnvelope(item.partitionKey, ItemDeleted(item)))
In the previous post we showed how to subscribe to messages using that partition key:
itemDeletedBus.subscribe(self, item.partitionKey)
LookupClassification will filter unwanted messages, so our actors won’t be overloaded.
Summary
Thanks to the flexibility that Kafka provides, we were able to design our system understanding different trade-offs. In the next posts we’ll see how to coordinate the outcome of those FSMs to provide a sync response to the client.
| Reference: | Publish Subscribe model in Kafka from our JCG partner Felipe Fernandez at the Crafted Software blog. |
