Streaming data can be used as a long-term auditable history when you choose a messaging system with persistence, but is this approach practical in terms of the cost of storing years of data at scale? The answer is “yes”, particularly because of the way topic partitions are handled in MapR Streams. Here’s how it works.
Streaming Data as a Long Term Re-Playable Log
Messaging technologies such as Apache Kafka and MapR Streams, which is compatible with the Kafka API, are disrupting big data architectures to make stream-based designs reach far beyond just real-time or near real-time projects. Because they can deliver low latency performance at large scale even with persistence, these modern messaging systems can decouple data producers from consumers or groups of consumers. That de-coupling opens the door to having consumers that are using data in a variety of ways, including as a re-playable log.
Messages arrive ready to be used immediately or to be consumed later, replaying the log of events. Consumers do not have to be running at the time messages arrive; they can come online later, making it easy to add new consumers. Both Kafka and MapR Streams support this behavior, but there are important technical differences that make a big difference in how they can be used. One such difference is in the way they handle topic partitions, and that, in turn, makes a difference in how feasible it is to keep message logs over long periods.
Background: A review of topic partitions
If you’re not familiar with Kafka or MapR Streams, a little background about topics and partitions will be helpful. Data in these messaging systems is assigned to topics – each topic is a flow of messages that is named for convenience – and consumers subscribe to one or more topics. To enhance performance, load balancing is achieved by dividing topics into sub-topic partitions, as shown in Figure 1. More specifically, each consumer in this case subscribes to one or more partitions. Note that this style of messaging is different from tools that broadcast messages to all consumers, providing message data on a use-it-when-it-arrives basis and also different from tools that are very careful about sending each message to exactly one consumer.
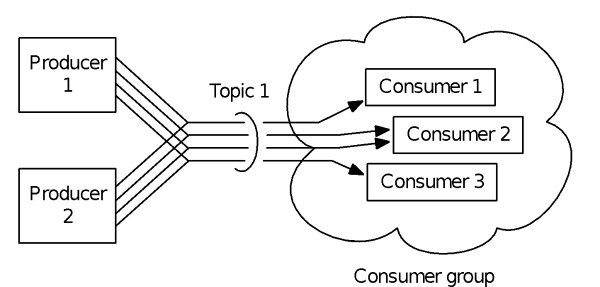
Figure 1: Each topic in Apache Kafka or MapR Streams can be divided into several partitions. This helps with load balancing. Consumers subscribe to one or more partitions. Kafka runs on a separate cluster from file storage or data processing and stores each replica of each topic partition on a single machine, thus incurring a size limit on topic partitions. MapR Streams, in contrast, is integrated into the MapR converged platform. With MapR, a topic partition is distributed across the entire cluster that also is shared with file storage and computation. See also Streaming Architecture, a book by Dunning and Friedman (O’Reilly) Chapter 4 “Apache Kafka” and Chapter 5 “MapR Streams”.
In the case of MapR Streams, there’s also a feature called a Stream that collects together many topics. This is primarily a management feature: streams have names in the overall file system namespace, and policies such as time-to-live, ACEs or geo-distributed replication are applied at the Stream level, which is particularly convenient as MapR Streams can also support a huge number of topics (100,000’s), far more than are feasible in Kafka. Although Kafka does not have the equivalent of a MapR Stream, you can set time-to-live per topic in Kafka, so you still have the option to use data and discard it or save it for varying periods of time, as you can with MapR Streams. But if you set the time-to-live to years or even to infinity, is this a practical option with large amounts of data?
Advantage: Each topic partition in a MapR Stream is distributed across the cluster
The way that topic partitions are distributed is different with Apache Kafka as compared to MapR. Here’s why that matters: At a recent Apache Flink meetup in London, during a discussion that followed a presentation by Flink co-founder Stephen Ewan, the practicality of saving multiple years worth of message event data in an auditable log was questioned. Audience members seemed quite sure that such a long time-to-live just isn’t feasible. That’s when I realized that many people were unaware that having a better fundamental architecture underneath the topics could allow storage of a several year’s worth of data. MapR Streams has just such an architecture.
MapR’s Ted Dunning, another speaker at the event, explained that when you examine the cost and feasibility it’s important to know that MapR Streams messaging is integrated into the main cluster, rather than running on a separate cluster as in the case of Kafka. And with MapR, each partition is not restricted to a single machine – MapR topic partitions are distributed across the cluster. In contrast, Kafka runs on a separate cluster. With Kafka, each topic partition is restricted to a single machine in the Kafka cluster. This difference is made possible because MapR Streams is not just a port of Apache Kafka. Instead, it is a complete reimplementation built as part of the MapR platform.
A related issue with topic balancing was described by Will Ochandarena, Director of Product Management at MapR, in a report on the recent Kafka Summit. A frequently mentioned pain point with using Kafka is “…for multiple “heavy” partitions to be placed on the same node, resulting in hot spotting and storage imbalances.”
Will went on to explain the difference in how this works with MapR Streams. “Rather than pin partitions to a single node, MapR Streams splits partitions into smaller linked objects, called “partitionlets”, that are spread among the nodes in the cluster. As data is written to the cluster, the active partitionlets (those handling new data) are dynamically balanced according to load, minimizing hotspotting.”
So it’s not a question of whether or not both systems have durable messages – they do – and whether the time-to-live is configurable in both systems. But with MapR Streams messaging, it’s entirely reasonable to save message data for long periods of time for those use cases in which a long-term history is desirable.
When is a long-term re-playable history is useful?
The idea of a stream-based architecture that readily supports long-term persistence in a re-playable stream as well as low-latency processing is new, so the use cases are just beginning to appear.
In the book Streaming Architecture my co-author Ted Dunning and I discuss a range of consumer categories including the long-term auditable log. Toward the end of the first chapter, we describe a hypothetical example in a medical setting where streaming data might be used in a variety of ways. Figure 2 shows three classes of users (consumers).
One path through this example is to deliver data from lab tests or diagnostic or therapeutic equipment through the messaging technology to a real-time or near real-time processing application. This type of low latency application is often the one that first attracts users to work with streaming data. Figure 2 shows this example in Group A consumers.
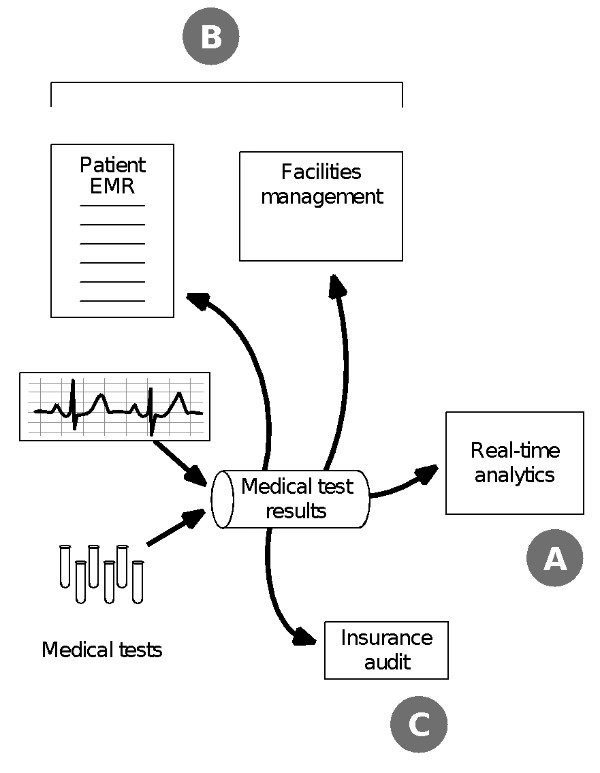
Figure 2: Stream-based architecture using Apache Kafka or MapR Streams style of messaging supports different categories of consumers. Type A consumers might use low latency processing tools to do analytics on streaming data from various lab tests; results might be displayed on a real-time dashboard or monitoring display. Type B consumers could extract a current-state view of a patient’s medical status or the performance of equipment for use in a database or search document. A final group, Type C, would use streaming event data as a re-playable log that serves as an auditable history, something of interest to insurance groups. See Chapter 1 of the book Streaming Architecture @Dunning and Friedman 2016.
Other consumers or groups of consumers can use the same stream of event data for purposes other than real-time applications. These include pulling updates of status into a database or fields of a searchable document (Group B in this figure). But the main focus of this article, Group C consumers, use the messages as an re-playable log that serves the function of a long-term auditable history. In the healthcare example depicted in the figure, this third type of consumer function might be for the purposes of an insurance audit.
You could apply this pattern of usage to other sectors. For example in a financial setting, the database might provide the status of an individual’s bank account while the re-playable log provides a transactional history of how that account balance came to be. In the case of streaming data from IoT sensors on industrial equipment, the re-playable history might serve as input data to train an anomaly detection model as part of a plan for predictive maintenance. The key idea is that with the right messaging system, the ability to store and analyze long-term histories becomes practical.
Resources and References
- For the report on Kafka Summit, see “Scaling with Kafka: Common Challenges Solved”.
- For more depth on using Apache Kafka, see Chapter 4 of Streaming Architecture or for a hands-on example, try the blog “Getting Started with Sample Programs for Kafka 0.9”.
- For more on MapR Streams, see Chapter 5 of Streaming Architecture and a hands-on tutorial “Getting Started with MapR Streams”.
- For free on demand training, see two courses on MapR Streams.
| Reference: | How Apache Kafka and MapR Streams Handle Topic Partitions from our JCG partner Ellen Friedman at the Mapr blog. |
