In this post we are going to discuss building a real time solution for credit card fraud detection.
There are 2 phases to Real Time Fraud detection. The first phase involves analysis and forensics on historical data to build the machine learning model which can be used in production to make predictions on live events.
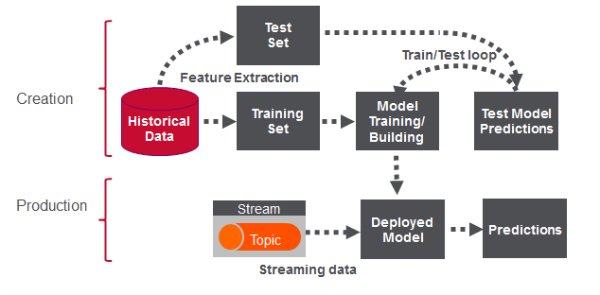
Building the Model
Classification
Classification is a family of supervised machine learning algorithms that identify which category an item belongs to (for example whether a transaction is fraud or not fraud), based on labeled examples of known items (for example transactions known to be fraud or not). Classification takes a set of data with known labels and pre-determined features and learns how to label new records based on that information. Features are the “if questions” that you ask. The label is the answer to those questions. In the example below, if it walks, swims, and quacks like a duck, then the label is “duck”.

Let’s go through an example of car insurance fraud:
- What are we trying to predict?
- This is the Label: The Amount of Fraud
- What are the “if questions” or properties that you can use to predict ?
- These are the Features, to build a classifier model, you extract the features of interest that most contribute to the classification.
- In this simple example we will use the the claimed amount.
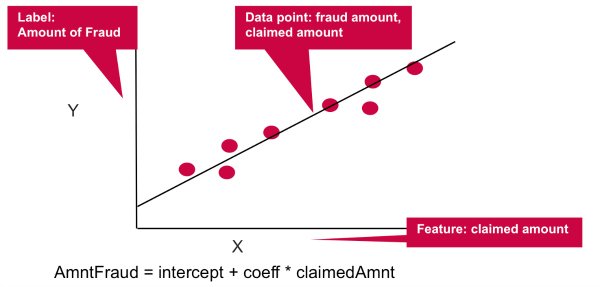
Linear regression models the relationship between the Y “Label” and the X “Feature”, in this case the relationship between the amount of fraud and the claimed amount. The coefficient measures the impact of the feature, the claimed amount, on the label, the fraud amount.
Multiple linear regression models the relationship between two or more “Features” and a response “Label”. For example if we wanted to model the relationship between the amount of fraud and the the age of the claimant, the claimed amount, and the severity of the accident, the multiple linear regression function would look like this:
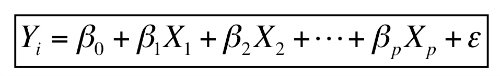
AmntFraud = intercept+ coeff1 * age + coeff2 * claimedAmnt + coeff3 * severity + error.
The coefficients measure the impact on the fraud amount of each of the features.
Let’s take credit card fraud as another example:
- Example Features: transaction amount, type of merchant, distance from and time since last transaction .
- Example Label: Probability of Fraud
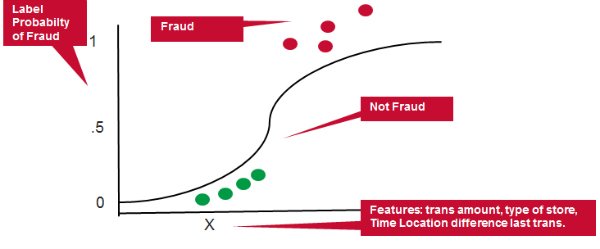
Logistic regression measures the relationship between the Y “Label” and the X “Features” by estimating probabilities using a logistic function. The model predicts a probability which is used to predict the label class.
- Classification: identifies which category (eg fraud or not fraud)
- Linear Regression: predicts a value (eg amount of fraud)
- Logistic Regression: predicts a probability (eg probability of fraud)
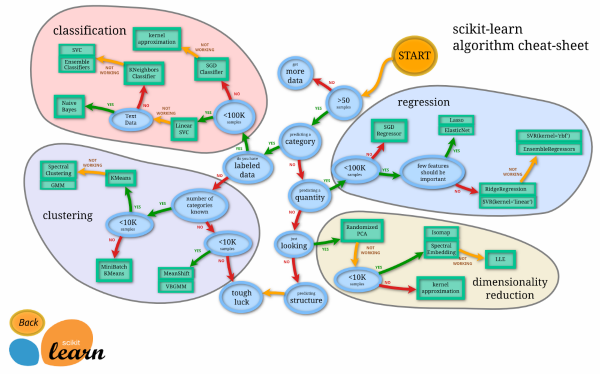
Linear and Logistic Regression are just a couple of algorithms used in machine learning, there are many more as shown in this cheat sheet.
Feature Engineering
Feature engineering is the process of transforming raw data into inputs for a machine learning algorithm. Feature engineering is extremely dependent on the type of use case and potential data sources.
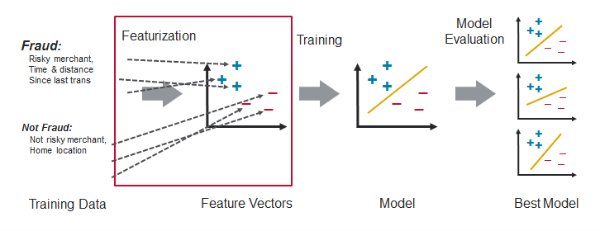
(reference Learning Spark)
Looking more in depth at the credit card fraud example for feature engineering, our goal is to distinguish normal card usage from fraudulent card usage.
- Goal: we are looking for someone using the card other than the cardholder
- Strategy: we want to design features to measure the differences between recent and historical activities.
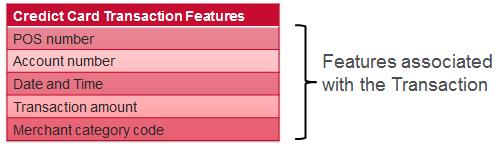
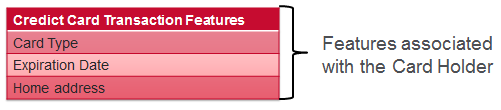
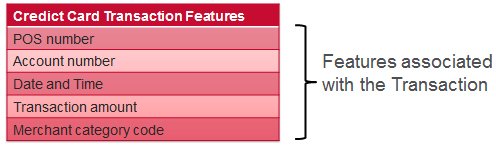
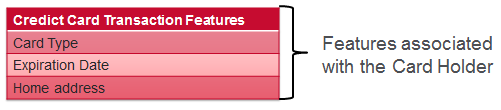
For a credit card transaction we have features associated with the transaction, features associated with the card holder, and features derived from transaction history. Some examples of each are shown below:

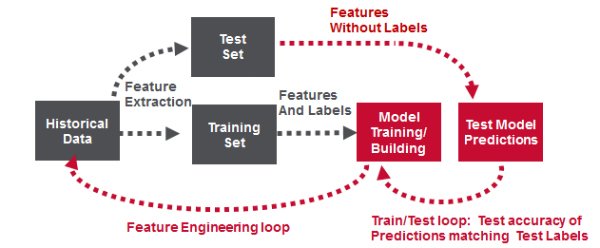
Model Building Workflow
A typical supervised machine learning workflow has the following steps:
- Feature engineering to transform historical data into feature and label inputs for a machine learning algorithm.
- Split the data into two parts, one for building the model and one for testing the model.
- Build the model with the training features and labels
- Test the model with the test features to get predictions. Compare the test predictions to the test labels.
- Loop until satisfied with the model accuracy:
- Adjust the model fitting parameters, and repeat tests.
- Adjust the features and/or machine learning algorithm and repeat tests.
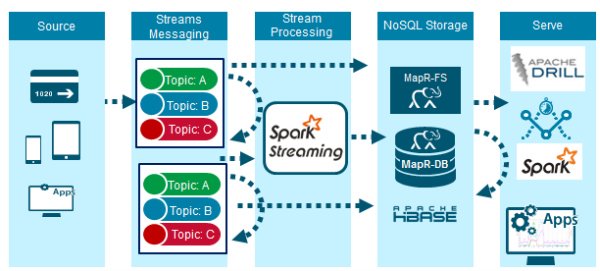
Read Time Fraud Detection Solution in Production
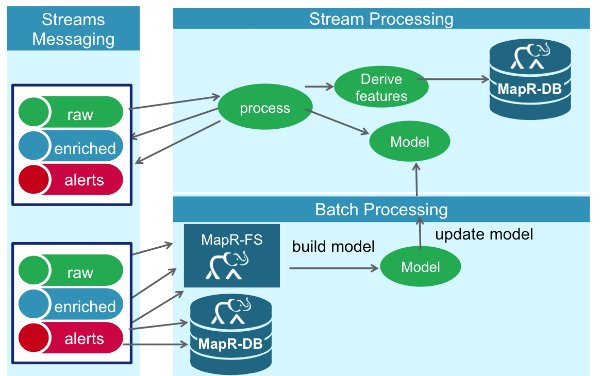
The figure below shows the high level architecture of a real time fraud detection solution, which is capable of high performance at scale. Credit card transaction events are delivered through the MapR Streams messaging system, which supports the Kafka .09 API. The events are processed and checked for Fraud by Spark Streaming using Spark Machine Learning with the deployed model. MapR-FS, which supports the posix NFS API and HDFS API, is used for storing event data. MapR-DB a NoSql database which supports the HBase API, is used for storing and providing fast access to credit card holder profile data.
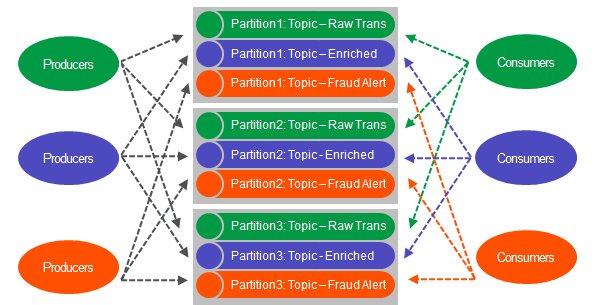
Streaming Data Ingestion
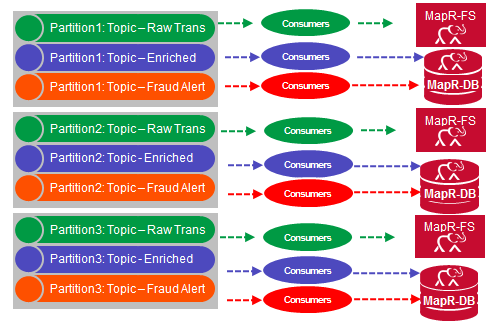
MapR Streams is a new distributed messaging system which enables producers and consumers to exchange events in real time via the Apache Kafka 0.9 API. MapR Streams topics are logical collections of messages which organize events into categories. In this solution there are 3 categories:
- Raw Trans: raw credit card transaction events.
- Enriched: credit card transaction events enriched with card holder features, which were predicted to be not fraud.
- Fraud Alert: credit card transaction events enriched with card holder features which were predicted to be fraud.
Topics are partitioned, spreading the load for parallel messaging across multiple servers, which provides for faster throughput and scalability.
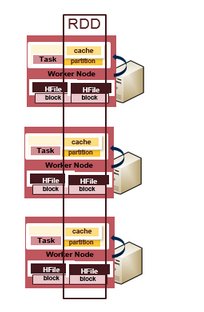
Real-time Fraud Prediction Using Spark Streaming
Spark Streaming lets you use the same Spark APIs for streaming and batch processing, meaning that well modularized Spark functions written for the offline machine learning can be re-used for the real time machine learning.
The data flow for the real time fraud detection using Spark Streaming is as follows:

1) Raw events come into Spark Streaming as DStreams, which internally is a sequence of RDDs. RDDs are like a Java Collection, except that the data elements contained in RDDs are partitioned across a cluster. RDD operations are performed in parallel on the data cached in memory, making the iterative algorithms often used in machine learning much faster for processing lots of data.
2) The credit card transaction data is parsed to get the features associated with the transaction.
3) Card holder features and profile history are read from MapR-DB using the account number as the row key.
4) Some derived features are re-calculated with the latest transaction data.

5) Features are run with the model algorithm to produce fraud prediction scores.
6) Non fraud events enriched with derived features are published to the enriched topic. Fraud events with derived features are published to the fraud topic.
Storage of Credit Card Events
Messages are not deleted from Topics when read, and topics can have multiple different consumers, this allows processing of the same messages by different consumers for different purposes.
In this solution, MapR Streams consumers read and store all raw events, enriched events, and alarms to MapR-FS for future analysis, model training and updating. MapR Streams consumers read enriched events and Alerts to update the Card holder features in MapR-DB. Alerts events are also used to update Dashboards in real time.
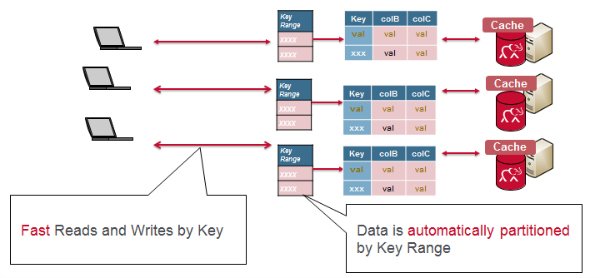
Rapid Reads and Writes with MapR-DB
With MapR-DB (HBase API), a table is automatically partitioned across a cluster by key range, and each server is the source for a subset of a table. Grouping the data by key range provides for really fast read and writes by row key.
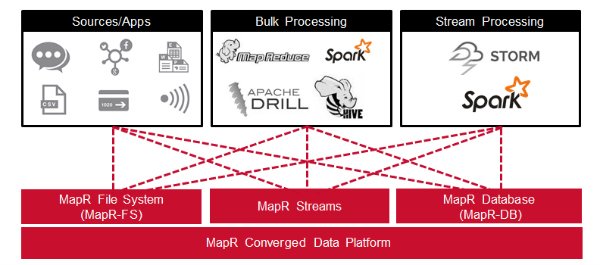
All of the components of the use case architecture we just discussed can run on the same cluster with the MapR Converged Data Platform. There are several advantages of having MapR Streams on the same cluster as all the other components. For example, maintaining only one cluster means less infrastructure to provision, manage, and monitor. Likewise, having producers and consumers on the same cluster means fewer delays related to copying and moving data between clusters, and between applications.
Summary
In this blog post, you learned how the MapR Converged Data Platform integrates Hadoop and Spark with real-time database capabilities, global event streaming, and scalable enterprise storage.![]()
| Reference: | Real Time Credit Card Fraud Detection with Apache Spark and Event Streaming from our JCG partner Carol McDonald at the Mapr blog. |
