What capabilities should you look for in a messaging system when you design the architecture for a streaming data project?
To answer that question, let’s start with a hypothetical IoT data aggregation example to illustrate specific business goals and the requirements they place on messaging technology and data architecture needed to meet those goals. The situation is a drilling operation with multiple locations, each of which has many pumps. Each pump, in turn, has multiple sensors taking measurements for a variety of parameters of interest, such as inlet and outlet flow rates, temperature, pressure, overall vibration, voltage and current for the motor and so on. This situation is depicted in Figure 1.
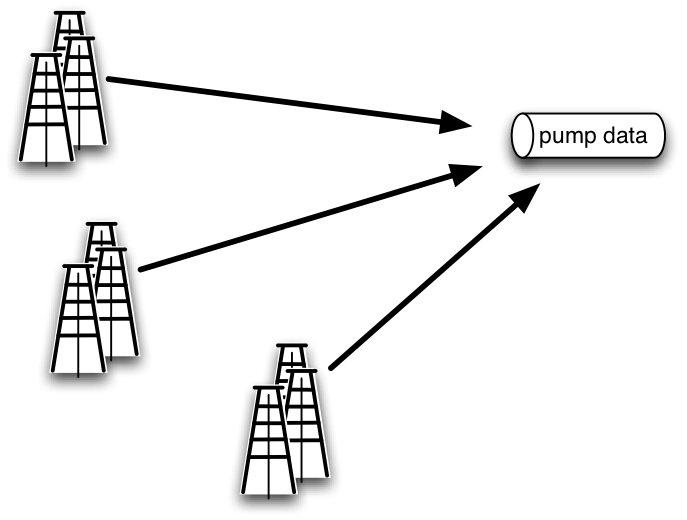
Figure 1: Streaming IoT data from multiple sensors on pumps at different drilling locations can be efficiently collected, aggregated and copied to a central processing center (or centers) using a messaging technology that supports multiple producers and consumers and has geo-distributed replication.
Among business goals for this drilling example are the need to monitor production rates, to maximize production efficiency, and to minimize downtime and costs due to destructive equipment failures. For these purposes, data must be aggregated from multiple locations and made available to more than one consumer. For example, one consumer may be an analytical application that updates a real-time dashboard for in-the-moment monitoring of pumps at a particular location. Other consumers may be doing anomaly detection to discover tell-tale patterns that precede failures as part of a predictive maintenance initiative. Some consumers may be reporting on production levels for pumps at all locations. These multiple consumers need to use the same streaming data in different ways, as shown in Figure 2.
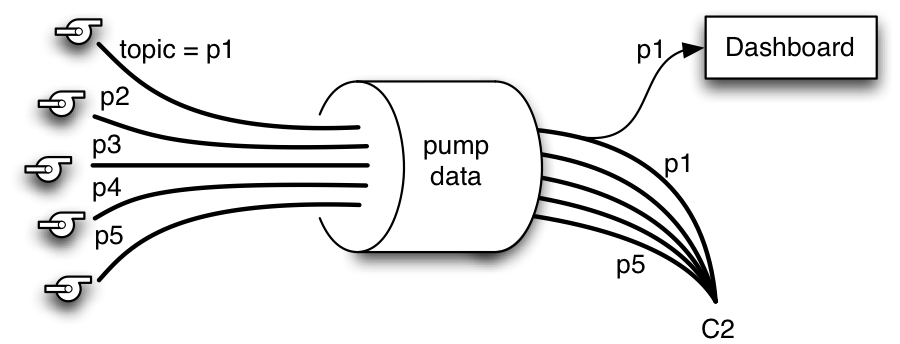
Figure 2: One way to design data flow is to assign all the sensor data for measurements related to different parameters from one pump to a single topic in the messaging system. That way you would have multiple topics, each with data from one pump. The messaging system depicted here is MapR Streams, which has the unique capability to collect many topics into a MapR platform object known as a stream, shown here as a large cylinder handling multiple topics. Policies such as replication, time-to-live and access are set at the stream level.
In this example, streaming sensor data from each pump can be followed independently, delivered from multiple sites to a central data center and made available right away to multiple consumers. The high rate of data production from sensors requires a messaging system that with high performance even at very large scale and low latency.
Those requirements are clear, but there are a few requirements that may not be quite so apparent at first glance. For example:
- It’s important for more than one consumer to be able to use the data but to be selective: not all consumers need all the data, and they should not have to read all the data.
- Business goals may require that the streaming technology can accommodate the possibility of different owners for data from particular pumps. That’s one situation in which effective access controls likely would be necessary.
- To take advantage of the flexibility provided by a micro-services approach, it’s generally important to strongly decouple the data producers from the data consumers, something the right message passing system can do.
It can be important for repeatability that data in the streaming layer be persisted for long periods. This persistence allows the original messages to be replayed for applications such as building models for anomaly detection and predictive maintenance or for auditing purposes. This style of persisting messages is different from an older habit of persisting them to files during development and then working from streaming data in production – the older approach could lead to unwanted surprises.
In contrast, the modern style of messaging makes it possible to use the original messages during development, even by replaying the log, without having to persist them to files. This approach makes deployment of new software more reliable and repeatable.
A similar example was presented in a presentation by MapR Chief Application Architect, Ted Dunning, at a recent Strata + Hadoop World conference in San Jose. In this talk, titled “Real Time Hadoop: What an Ideal Messaging System Should Bring to Hadoop”, Ted explored the characteristics of older message queue technologies with modern messaging systems such as Apache Kafka and MapR Streams, which uses the Kafka 0.9 API but is integrated into the MapR data platform. In addition, Ted discussed the trade-offs of the older and newer designs.
Older queue-style systems may include out-of-order acknowledgment capabilities but generally cannot also provide long-term persistence without a huge cost to performance. Out-of-order acknowledgment of messages allows flexible processing of messages and appears attractive at first, but it is at the heart of the performance limitations of older systems.
In contrast, modern Kafka-esque systems (Apache Kafka and MapR Streams) have a different approach that enables them to provide persistence and high performance, even at speed and scale. These technologies have strong ordering guarantees for messages, but consumers cannot do out-of-order acknowledgments.
Another key capability of ideal messaging technology is found in modern systems: to deliver data from multiple producers but provide strong isolation from multiple consumers. Data is ready to use right away or later. The consumer need not even be running at the time the data is delivered. New consumers also can be added at a later date. In this way these Kafka-esque technologies differ from some older queuing technologies that broadcast messages to all subscribers all the time.
Geo-distributed replication adds an extra layer to the advantages of a stream-based architecture. The ability to move messages efficiently from different locations to one or more data processing centers was included in the example shown in Figure 1 here. MapR Streams is particular well suited to use cases that send data from one location to another: replication occurs at the stream level for a collection of topics.
In his Strata presentation, Ted also described an IoT use case involving container shipping between multiple ports. This is a situation in which MapR Streams could be used to advantage to update clusters on board and on shore, at the current port and in advance of the ship’s next port-of-call. Also, because MapR’s messaging system is incorporated into the MapR converged data platform, there is no need to run a separate cluster for data event streaming as would be needed with Kafka. This convergence in the MapR platform provides the advantage of uniform data management, snapshots, and mirroring for files, tables and message streams, all under the same data security system.
| Key take-away:A messaging system with modern capabilities such as those of Apache Kafka or MapR Streams makes a better fit between data architecture and business structure. |
Kafka 0.9 sample code:
MapR Streams sample code:
| Reference: | Ideal Messaging Capabilities for Streaming Data from our JCG partner Ellen Friedman at the Mapr blog. |
