1 Introduction
In a previous post, we built a basic example of an aggregation pipeline. Maybe you want to take a look at Data aggregation with Spring Data MongoDB and Spring Boot if you need more detail about how to create the project and configure the application. In this post, we will focus on learning a use case where it makes sense to group a portion of the result in a nested object.
Our test data is a collection of football players, with data about the league they belong to and how many goals they scored. The document would be like this:
@Document
public class ScorerResults {
@Id
private final String player;
private final String country;
private final String league;
private final int goals;
public ScorerResults(String player, String country, String league, int goals) {
this.player = player;
this.country = country;
this.league = league;
this.goals = goals;
}
//Getters and setters
}It may be interesting to know how many goals were scored in each league. Also, who was the league’s top goalscorer. During the following section, we are going to implement our first simple example without using nested objects.
You can find the source code of all these examples at my Github repository.
2 Basic example
We can use the following class to store each league’s result:
public class ScorerNotNestedStats {
private String league;
private int totalGoals;
private String topPlayer;
private String topCountry;
private int topGoals;
//Getters and setters
}In order to retrieve the top scorers, we will first need to sort the documents by scored goals and then group them by league. In the repository, these two phases of the pipeline are implemented in the following methods:
private SortOperation buildSortOpertation() {
return sort(Sort.Direction.DESC, "goals");
}
private GroupOperation buildGroupOperation() {
return group("league")
.first("league").as("league")
.sum("goals").as("totalGoals")
.first("player").as("topPlayer")
.first("goals").as("topGoals")
.first("country").as("topCountry");
}That should do it. Let’s aggregate the results using Spring’s mongoTemplate:
public List<ScorerNotNestedStats> aggregateNotNested() {
SortOperation sortOperation = buildSortOpertation();
GroupOperation groupOperation = buildGroupOperation();
return mongoTemplate.aggregate(Aggregation.newAggregation(
sortOperation,
groupOperation
), ScorerResults.class, ScorerNotNestedStats.class).getMappedResults();
}If we retrieve the stats of the spanish league, we get the following result:
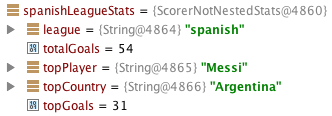
Although this is fair enough, I don’t feel comfortable with all top scorer’s information scattered throughout the result class. I think it would make much more sense if we could encapsulate all scorer’s data into a nested object. Fortunately, we can do that directly during the aggregation.
3 Nesting the result
Spring Data’s nested method is designed to create sub-documents during the projection phase. This will allow us to create the top goalscorer class as a property of the output result class:
ProjectionOperation projectionOperation = project("totalGoals")
.and("league").as("league")
.and("topScorer").nested(
bind("name", "topPlayer").and("goals", "topGoals").and("country", "topCountry")
);In the line above, a nested document called topScorer is emitted by the nested method, which will contain all the data about the current league’s top goalscorer. Its properties are mapped to the output class using the bind method (topPlayer, topGoals and topCountry).
MongoTemplate’s invocation reuses our previous sort and group operations, and then adds the projection operation:
return mongoTemplate.aggregate(Aggregation.newAggregation( sortOperation, groupOperation, projectionOperation ), ScorerResults.class, ScorerStats.class).getMappedResults();
Executing this query will result in a much more compact result, having all top goalscorer’s related data wrapped in its own class:

4 Conclusion
Spring Data MongoDB nested method is very useful for creating well structured output results from our aggregation queries. Doing this step during the aggregation helps us avoid having java code to post-process the result.
I’m publishing my new posts on Google plus and Twitter. Follow me if you want to be updated with new content.
| Reference: | Data Aggregation Spring Data MongoDB: Nested results from our JCG partner Xavier Padro at the Xavier Padró’s Blog blog. |
