97% of Logged Errors are Caused by 10 Unique Errors
It’s 2016 and one thing hasn’t changed in 30 years. Dev and Ops teams still rely on log files to troubleshoot application issues. For some unknown reason we trust log files implicitly because we think the truth is hidden within them. If you just grep hard enough, or write the perfect regex query, the answer will magically present itself in front of you.
Yep, tools like Splunk, ELK and Sumologic have made it faster to search logs but all these tools suffer from one thing – operational noise. Operational noise is the silent killer of IT and your business today. It’s the reason why application issues go undetected and take days to resolve.
New Post: We Crunched 1 Billion Java Logged Errors – Here’s What Causes 97% of Them https://t.co/fFht52vkp1 pic.twitter.com/ddHdrTRCjA
— OverOps (@overopshq) May 24, 2016
Log Reality
Here’s a dose of reality, you will only log what you think will break an application, and you’re constrained by how much you can log without incurring unnecessary overhead on your application. This is why debugging through logging doesn’t work in production and why most application issues go undetected.
Let’s assume you do manage to find all the relevant log events, that’s not the end of the story. The data you need isn’t usually not in there, and leaves you adding additional logging statements, creating a new build, testing, deploying and hoping the error happens again. Ouch.
Time for Some Analysis
At Takipi we capture and analyze every error or exception that is thrown by Java applications in production. Using some cheeky data science this is what I found from analyzing over 1,000 applications monitored by Takipi.
High-level aggregate findings:
- Avg. Java application will throw 9.2 million errors/month
- Avg. Java application generates about 2.7TB of storage/month
- Avg. Java application contains 53 unique errors/month
- Top 10 Java Errors by Frequency were
- NullPointerException
- NumberFormatException
- IllegalArgumentException
- RuntimeException
- IllegalStateException
- NoSuchMethodException
- ClassCastException
- Exception
- ParseException
- InvocationTargetException
So there you have it, the pesky NullPointerException is to blame for all thats broken in log files. Ironically, checking for null was the first feedback I got in my first code review back in 2004 when I was a java developer.
Right, here are some numbers from a randomly selected enterprise production application over the past 30 days:
- 25 JVMs
- 29,965,285 errors
- ~8.7TB of storage
- 353 unique errors
- Top Java errors by frequency were:
- NumberFormatException
- NoSuchMethodException
- Custom Exception
- StringIndexOutOfBoundsException
- IndexOutOfBoundsException
- IllegalArgumentException
- IllegalStateException
- RuntimeException
- Custom Exception
- Custom Exception
Time for Trouble (shooting)
So, you work in development or operations and you’ve been asked to troubleshoot the above application which generates a million errors a day, what do you do? Well, let’s zoom in on when the application had an issue right?
Let’s pick, say a 15 minute period. However, that’s still 10,416 errors you’ll be looking at for those 15 minutes. You now see this problem called operational noise? This is why humans struggle to detect and troubleshoot applications today…and it’s not going to get any easier.
What if we Just Fixed 10 Errors?
Now, let’s say we fixed 10 errors in the above application. What percent reduction do you think these 10 errors would have on the error count, storage and operational noise that this application generates every month?
1%, 5%, 10%, 25%, 50%?
How about 97.3%. Yes, you read that. Fixing just 10 errors in this application would reduce the error count, storage and operational noise by 97.3%.
The top 10 errors in this application by frequency are responsible for 29,170,210 errors out of the total 29,965,285 errors thrown over the past 30 days.
Take the Crap Out of Your App
The vast majority of application log files contain duplicated crap which you’re paying to manage every single day in your IT environment.
You pay for:
- Disk storage to host log files on servers
- Log management software licenses to parse, transmit, index and store this data over your network
- Servers to run your log management software
- Humans to analyze and manage this operational noise
The easiest way to solve operational noise is to fix application errors versus ignore them. Not only will this dramatically improve the operational insight of your teams, you’ll help them detect more issues and troubleshoot much faster because they’ll actually see the things that hurt your applications and business.
The Solution
If you want to identify and fix the top 10 errors in your application, download Takipi for free, stick it on a few production JVMs, wait a few hours, sort the errors captured by frequency and in one-click Takipi will show you the exact source code, object and variable values that caused each of them. Your developers in a few hours should be able to make the needed fixes and Bob will be your uncle.
The next time you do a code deployment in production Takipi will instantly notify you of new errors which were introduced and you can repeat this process. Here’s two ways we use Takipi at Takipi to detect new errors in our SaaS platform:
Slack Real-time Notifications which inform our team of every new error introduced in production as soon as it’s thrown, and a one-click link to the exact root cause (source code, objects & variable values that caused the error).
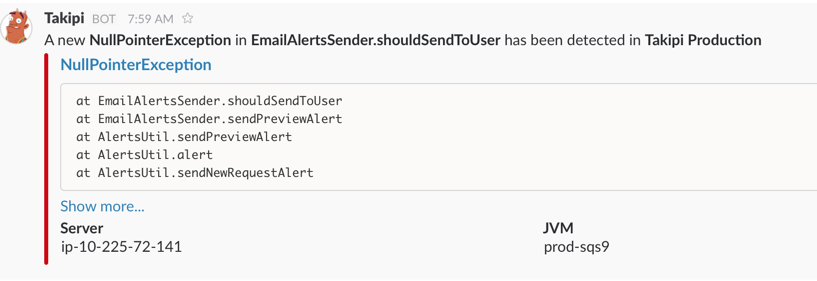
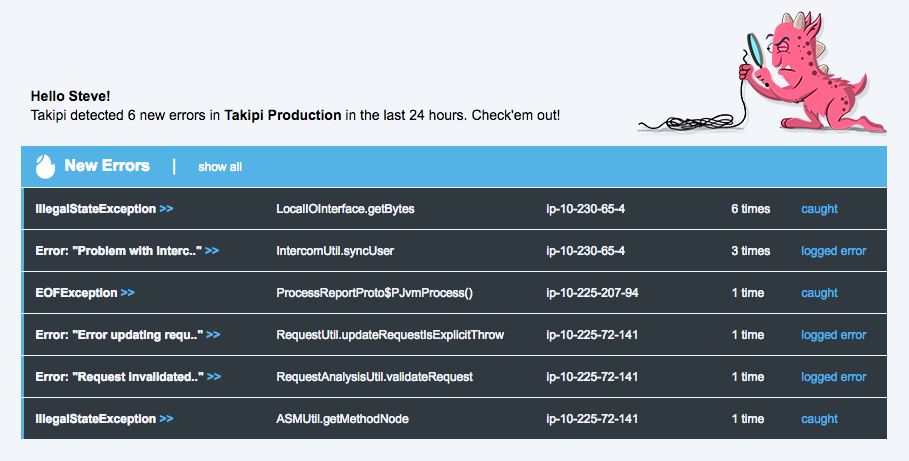
Email Deployment Digest Report showing the top 5 new errors introduced with direct links to the exact root cause.
Final Thoughts
We see time and time again that the top few logged errors in production are pulling away most of the time and logging resources. The damage these top few events cause, each happening millions of times, is disproportionate to the time and effort it takes to solve them.
Later this week we’re publishing the top 10 exception types that cause these errors. Stay tuned.
| Reference: | We Crunched 1 Billion Java Logged Errors – Here’s What Causes 97% of Them from our JCG partner Steve Burton at the Takipi blog. |
