Organizations embracing big data are ready to put data to work, including looking for ways to effectively analyze data from a variety of sources in real time or near real time. To be able to do so at scale, and at speed, can make an organization free to react to life as it happens and to carry out adjustments that can improve business while opportunities still exist.
When will this be possible and practical in enterprise big data systems? The good news is that a combination of data service technologies plus data processing tools has emerged to make this possible and practical across a wide range of large-scale workloads and use cases.
What does a big data platform need to be able to do to support these goals? Some key requirements on the data services side become clear when we examine the major forces that have driven evolution of data storage over the past 10 years. During a recent presentation at the Strata + Hadoop World conference in San Jose, Ted Dunning touched on the significance of the changes in big data storage as the field has evolved, and explained what MapR has done in building a converged big data platform as part of this evolution.
- Compatibility and functionality: Unix-based systems
For years, Linux and Unix-based systems have provided a standard approach to compatibility combined with functionality that supports smooth operation across a variety of analytical projects. This idea is depicted in Figure 1.
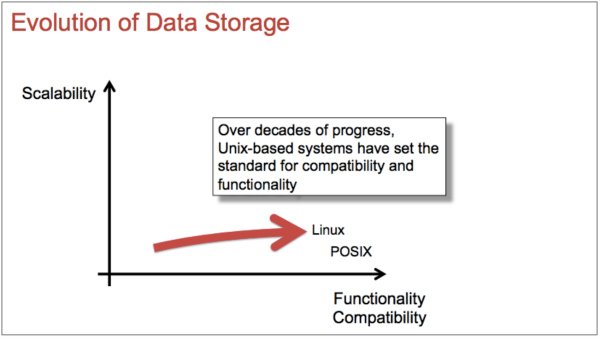
Figure 1: Functionality combined with compatibility are important requirements for data storage services. Unix-based systems, including Linux, are effective at providing this combination. (Illustration based on Strata conference presentation by Ted Dunning titled “Real-time Hadoop: What an ideal messaging system should bring to Hadoop,” used with permission.)
The need for change came, however, in response to the desire to use a much larger scale of data. This need for scalability was powered in substantial part by the growth of web activities and enterprises as well as a growing interest in using larger volumes of machine-derived data. Enter a great idea: Apache Hadoop-based distributed storage.
- Scalability: Hadoop brought scale but at the price of a loss of compatibility
Big data was not a practical resource for many organizations until an affordable approach made scalability feasible. The pressure to meet this need made it understandable that initial solutions would focus primarily on scale even if it meant impairing compatibility. That’s what happened with Hadoop: it opened the door to working with large volumes of data in an affordable way.
The scale of new big data projects had made them prohibitive with traditional systems, both in terms of performance and huge expense. In contrast, Hadoop worked as a storage framework that distributed files across commodity machines (and made cloud storage feasible as well) by making use of HDFS (the Hadoop distributed file system). It’s no wonder Hadoop kindled interest in developing a diverse ecosystem of big data tools for various aspects of data processing. New data services also appeared, including the NoSQL database known as Apache HBase.
However, while HDFS opened the way to scalability, it did so at the cost of compatibility and functionality. This trade-off is depicted in Figure 2.
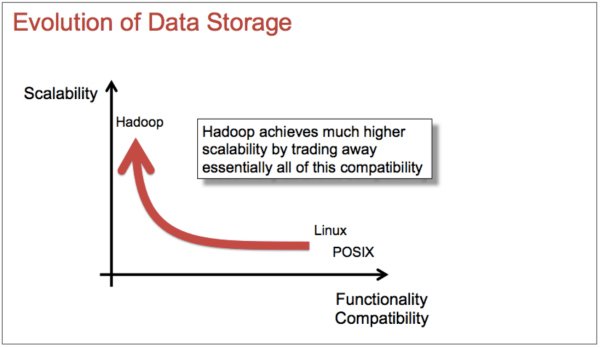
Figure 2: Compatibility and functionality suffered as Apache Hadoop made strides in solving the problem of scalability. (Illustration based on presentation by Ted Dunning titled “Real- time Hadoop: What an ideal messaging system should bring to Hadoop,” used with permission.)
The cost of this lack of compatibility is that whenever data in an HDFS-based Hadoop cluster needs to be processed by non-Hadoop programs, data has to be copied out of the HDFS system in order to be processed, and results then need to be copied back in. It’s as though there’s a wall around Hadoop separating it from everybody else. While Hadoop made it possible to collect and store data at scale, it requires “throwing the data over the wall.”
- Restore compatibility at scale: MapR-FS is compatible with Unix and Hadoop
And here’s where MapR came in: With their first public release in early 2011, MapR made an advance in big data storage options by restoring traditional compatibility along with the scalability of Hadoop. MapR was engineered from the ground up to be API compatible with Apache Hadoop but to also be compatible with legacy code including Unix-based systems.
This combination of scalability with compatibility was possible because MapR does not use HDFS. Instead, they engineered a real-time, fully read/write file system, MapR-FS, as the foundation of this Hadoop distribution. As a result, compatibility was restored to a highly scalable distributed system, and performance was also improved. These changes are illustrated in Figure 3.

Figure 3: Compatibility was restored to a highly scalable big data system with the development of the MapR Distribution of Apache Hadoop. (Illustration based on presentation by Ted Dunning titled “Real-time Hadoop: What an ideal messaging system should bring to Hadoop,” used with permission.)
The final stage is to continue to move the state of the art upwards and to the right in these diagrams by adding additional functionality.
- Add functionality combined with compatibility at scale: the MapR Converged Data Platform has integrated files, databases and streams
MapR initially added functionality to their data platform by developing an integrated NoSQL database called MapR-DB. The original version of MapR-DB was compatible with the Apache HBase API. Now, additional functionality has been added via a document-style NoSQL database using a JSON API also integrated into the MapR Platform.
Growing interest in streaming data underlined the need for an excellent message passing system. MapR rounded out their converged data platform by developing MapR Streams, a new high performance messaging system that uses the Apache Kafka 0.9 API. Today, read/write files, a multi-modal NoSQL database, and an integrated messaging system comprise the MapR Converged Data Platform. This combination of scalability, compatibility with legacy systems, and functionality are highlighted in Figure 4.
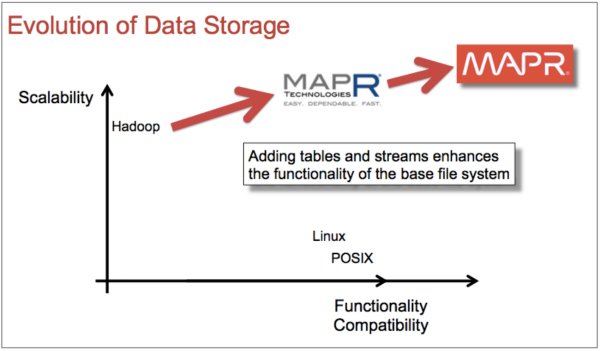
Figure 4: Functionality was added to highly scalable Hadoop-based storage in the form of the MapR Converged Data Platform: files, tables and streams all integrated into the platform. (Illustration based on presentation by Ted Dunning titled “Real-time Hadoop: What an ideal messaging system should bring to Hadoop,” used with permission.)
For more information about working with streaming data, read the book Streaming Architecture: New Designs Using Apache Kafka and MapR Streams by Ted Dunning and Ellen Friedman (O’Reilly, March 2016) available for free download from MapR.![]()
| Reference: | Evolution of Big Data Storage: How to Support Real-time Analytics at Scale from our JCG partner Ellen Friedman at the Mapr blog. |
