We have experimented with CaffeOnSpark on a 5 node MapR 5.1 cluster running Spark 1.5.2 and will share our experience, difficulties, and solutions on this blog post.
Deep Learning and Caffe
Deep learning is getting a lot of attention recently, with AlphaGo beating a top world player at a game that was thought so complicated as to be out of reach of computers just five years ago. Deep learning is not just beating humans at Go, but also at pretty much every Atari computer game.
But the fact is, deep learning is also useful for tasks with clear enterprise applications in the fields of image classification and speech recognition, AI chat bots and machine translation, just to name a few.
Caffe is a C++/CUDA deep learning framework originally developed by the Berkeley Vision and Learning Center (BVLC). It is especially well regarded for applications related to images. Caffe can leverage the power of CUDA-enabled GPUs such as any NVIDIA consumer GPU, meaning anybody with a gaming PC can run state-of-the-art deep learning for themselves. Cool!
What’s more, Caffe models are often made available publicly. We can thus try for ourselves the absolute state-of-the-art models trained on huge datasets by the leading researchers in the field. For example, Microsoft’s 2015 winning image classifier is available here.
The open source project can be found on GitHub and has a homepage with all the necessary instructions to get it working on Linux and MacOS X and even has a Windows distribution.
CaffeOnSpark
The major problem with Caffe and most consumer-level deep learning is that they can only work on a single computer, which is limited to at most four GPUs. For real enterprise applications, datasets can easily scale up to hundreds of GB of data, requiring days of computing on even the fastest possible single-node hardware.
Google, Baidu, and Microsoft have the resources to build dedicated deep learning clusters that give the deep learning algorithms a level of processing power that both accelerates training time as well as increases their model’s accuracy. Such compute monster clusters have become a necessary requisite for reaching the very best, human-level (or better) performance with deep learning models.
Yahoo, however, has taken a slightly different approach, by moving away from a dedicated deep learning cluster and combining Caffe with Spark. The ML Big Data team’s CaffeOnSpark software has allowed them to run the entire process of building and deploying a deep learning model onto a single cluster. This software has been released as open source late last year and is now available on GitHub.
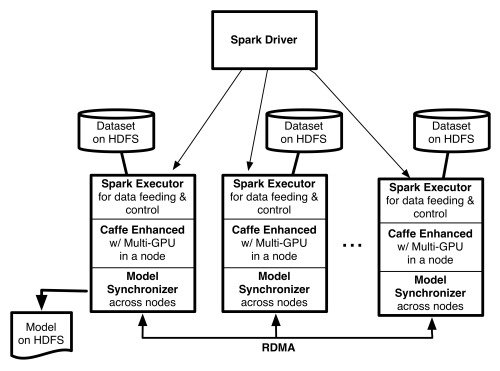
Running CaffeOnSpark on MapR
Our cluster was running MapR 5.1 on 5 nodes, deployed on AWS EC2 instances. Each node is a m4.4xlarge instance with 12 vcores and 30GB memory. The operating system chosen is Ubuntu 14.04. The version of Spark is the MapR-supplied version 1.5.2, slightly modified to account for the MapR high-performance C-native filesystem instead of HDFS.
First we installed Caffe on one of the nodes, to assure ourselves that the setup is indeed compatible with Caffe. The wiki page from their Github was an invaluable instruction manual that allowed reasonably straightforward installation. Our instance doesn’t have a GPU, but not installing CUDA would cause a compilation error when installing CaffeOnSpark, so we recommend to install the drivers anyway. We installed CUDA 7.5 version, the latest at the moment of this writing. All of the steps worked as-is. Installing PyCaffe is not necessary but it’s a good way to make sure the installation is really perfect.
We ran the compilation, ran the tests and also ran the example MNIST digits task.
For that example, from the Caffe folder, run data/mnist/get_mnisn.sh then examples/mnist/create_mnist.sh and finally example/mnist/train_lenet.sh.
You can test the installation of pycaffe by running make pycaffe and then go to the Caffe/python folder and open a Python shell and type. import caffe If everything imports, a few Matplotlib warnings notwithstanding, then the installation was perfect.
After confirming Caffe is installed properly, we got CaffeOnSpark, and compiled it following closely the instructions on the GitHub wiki page. Note: make sure that you also install maven and zip (sudo apt-get install zip maven -y) before starting the compilation, they are required! Thankfully, if you don’t have them and start compilation anyway, the error is easily understood and installing the missing bits and restarting the compilation results in a correct installation as well.
Copy the CaffeOnSpark folder to all the nodes. This is essential! The folder location must be the same everywhere. We ran everything as root, but this is probably not necessary.
The instructions mention:
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.0/lib64:/usr/local/mkl/lib/intel64/Obviously, we’ll need to update cuda-7.0 to cuda-7.5 and also remove the part to Intel’s MKL since we aren’t using it. We added this to .bashrc file.
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib:/usr/local/cuda-7.5/lib64In fact, we also added to our .bashrc:
export JAVA_HOME=/usr/lib/jvm/java-7-oracle/
export CUDA_HOME=/usr/local/cuda-7.5
export CAFFE_HOME=/root/caffe
export CAFFE_ON_SPARK=/root/CaffeOnSpark
export SPARK_HOME=/opt/mapr/spark/spark-1.5.2
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/libexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.5/lib64Running CaffeOnSpark
Standalone Mode
First we ran CaffeOnSpark on the MNIST example in standalone mode, following the instructions from the GitHub.
A successful run encouraged us to try it on YARN.
YARN Cluster Mode
We ran the instructions for YARN and could get it working soon, but with the caveat that each worker was using only one vcore.
The way that CaffeOnSpark works is that the cluster workers are used to train Caffe models in parallel and then the models are collected back using REDUCE; the models are averaged and new tasks are sent back to workers with updated parameters.
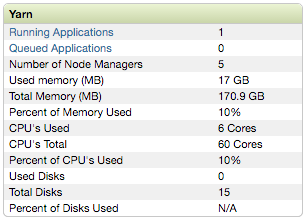
With only 5 executors, each with 1 vcore, plus 1 vcore for the driver, using the command line parameters suggested by the CaffeOnSpark instructions vastly underuse the CPU power of our cluster. In fact, each Caffe iteration was taking about 18 seconds.
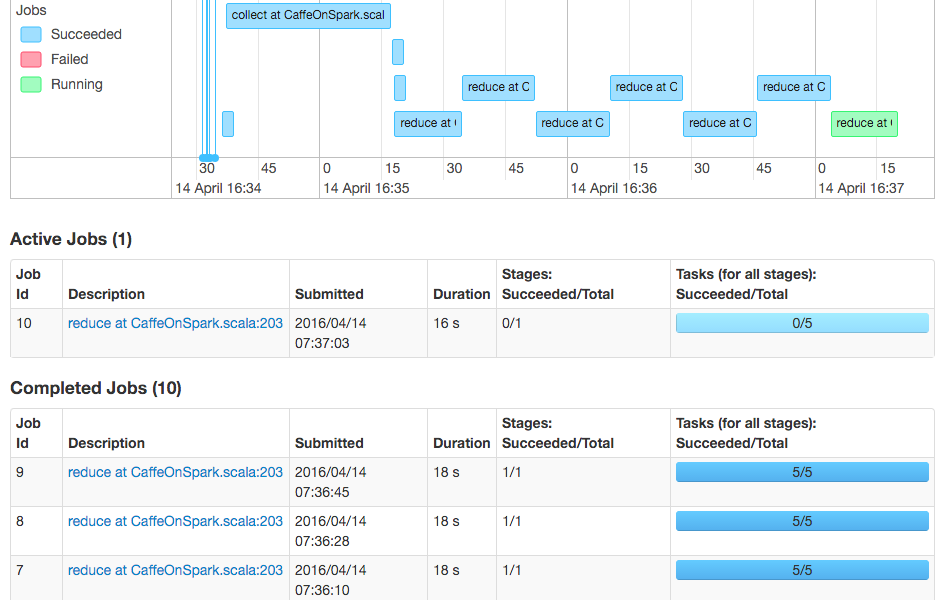
Dealing with Exceptions and Performance Tuning
We had random errors when trying to play with the –num-executors parameter; CaffeOnSpark would throw an exception due to the executors not being found in the correct number. We could get it to work sometimes if the –num-executors was set to five, the same as the number of workers, but it would also sometimes throw an exception, too.
This problem was solved using the following parameters:
--conf spark.scheduler.minRegisteredResourcesWaitingTime=30 --conf spark.scheduler.minRegisteredResourcesRatio=1.0
YARN in cluster mode submits the driver as a container and by the time the driver starts to execute, all the worker executors may not be ready and available, so that when CaffeOnSpark checks for the correct number of executors, it finds an unexpected count and throws an exception. By giving more time and requiring that all the registered resources be available, this error can be fixed.
With that error fixed, we were able to increase the number of cores using the following parameters:
--num-executors X --executor-cores Y
Where X is the number of executors and Y is the number of cores per executor. X * Y should be some number a bit lower than the total number of vcores available to YARN. In our case, we have 60 total vcores, so we played with various combinations of X and Y and found that X=25 and Y=2 produced the fastest iterations at 8s, and X=50 and Y=1 maxed out the CPU of the cluster but with slightly longer iterations at about 9s.
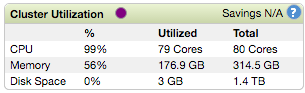
We know that in deep learning, more compute power is beneficial for both higher accuracy and faster training time. So we think that as the number of executors increases, the accuracy of the final models will be better, but that the training time, given our hardware and software and the architecture of CaffeOnSpark, limits each iteration to about 8s at best.
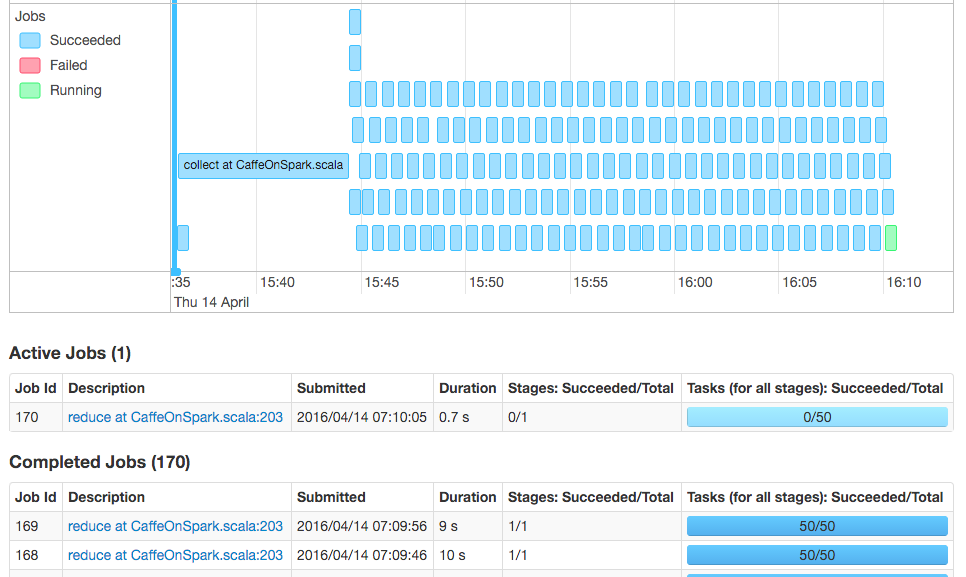
The tasks aren’t memory limited, and the cluster never uses more than 60% total memory. An IO bottleneck is also fairly unlikely since the MNIST dataset is so tiny, barely 60MB for the train set and 10MB for the test set. Finally, looking at the DAG from the Spark web UI shows that CPU accounts for > 95% of the time spend on each map job, so network or distribution inefficiency for this dataset probably aren’t bottlenecks either.
Another thing we have noticed is that the number of iterations before convergence goes up with the number of executors. It’s hard to draw any conclusion about this because the MNIST task is considered very easy at this point. Getting accuracy and loss metrics on a real dataset would be instructive on what exactly is going on here.
Conclusion
The MapR Spark implementation is a perfectly good target for running CaffeOnSpark. As a follow-up project, it would be worthwhile to test again on a cluster using EC2 instances that have GPUs and see the performance difference.
Yahoo’s reason for developing CaffeOnSpark in the first place, that of converging their deep learning operations onto a single cluster, makes tremendous sense. The MapR Converged Data Platform is the ideal platform for this project, giving you all the power of distributed Caffe on a cluster with enterprise-grade robustness, enabling you to take advantage of the MapR high performance file system.![]()
| Reference: | Distributed Deep Learning with Caffe Using a MapR Cluster from our JCG partner Mathieu Dumoulin at the Mapr blog. |
