How to Build Applications on a NoSQL Document Database and Perform Analytics in Place
In this article we will explore what it means to have a converged data platform for building and delivering business applications. This sample application will be to create blog articles for a personal website.
The following picture illustrates the the flow of data and how the MapR-DB Rest application utilises the OJAI API to interact with the MapR-DB JSON tables. Then we will explore how to run ANSI SQL using Apache Drill 1.6 on the same MapR-DB JSON tables, without having to transform or move the data elsewhere.
Ingest anything in it’s natural form and use standard tools for in-place analytics.
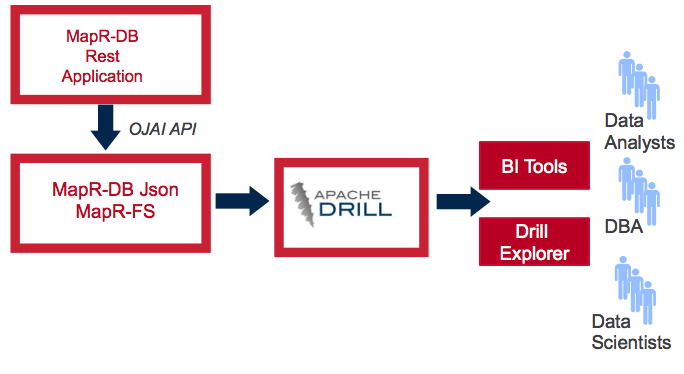
This MapR-DB REST Application contains the following components:
- A Main class that starts a Jetty Server and configures a REST Interface using JAX-RS
- Swagger to easily access the HTTP API
- An Angular JS Application that consumes this API
To get started you first need a MapR installation or sandbox running 5.1 and Apache Drill 1.6 with at least 8GB of RAM. If you have this already please skip to “Configuring the build environment” section.
Getting a MapR 5.1 Sandbox (if required)
Download the MapR 5.1 sandbox by following the instructions here http://maprdocs.mapr.com/51/index.html#SandboxHadoop/t_install_sandbox_vmware.html
This sandbox should have Internet access to complete the rest of the install.
Please make sure you increase the RAM from 6GB to 8GB on the VM before starting it. Apache Drill will require an additional 2GB of RAM.
After the installation and starting the sandbox you should see the following screen. Please note I use VM Fusion On Mac OSX
Logon to the cluster as mapr, please note the IP address of your Sandbox may vary from my example.
$ ssh mapr@192.168.185.248 The authenticity of host '192.168.185.248 (192.168.185.248)' can't be established. RSA key fingerprint is 6a:36:ea:47:74:e6:57:92:e0:12:c4:8f:ee:64:09:20. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.168.185.248' (RSA) to the list of known hosts. Password: mapr Welcome to your Mapr Demo virtual machine. [mapr@maprdemo ~]$ Password :- mapr
Configuring the build environment
To be able to build the MapR-DB Rest Application we first need to configure Maven.
These instructions will install Maven 3 on Centos so we can compile the OJAI application. Please alter accordingly for Ubuntu based distro’s
$ su - root
Password: mapr
# yum install git
# wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.3.9/binaries/apache-maven-3.3.9-bin.tar.gz
# tar xvf apache-maven-3.3.9-bin.tar.gz -C /usr/local
# cd /usr/local
# ln -s apache-maven-3.3.9/ maven
# vi /etc/profile.d/maven.sh
add the following lines.
export M2_HOME=/usr/local/maven
export PATH=${M2_HOME}/Log out of the sandbox and back in to pick up these changes. You should see the following.
$ ssh mapr@192.168.185.248 Password: mapr Last login: Thu Apr 7 23:58:05 2016 from 192.168.185.1 Welcome to your Mapr Demo virtual machine. [mapr@maprdemo ~]$ mvn -version Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-10T08:41:47-08:00) Maven home: /usr/local/maven Java version: 1.7.0_79, vendor: Oracle Corporation Java home: /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.79.x86_64/jre Default locale: en_GB, platform encoding: UTF-8 OS name: "linux", version: "2.6.32-573.el6.x86_64", arch: "amd64", family: "unix"
Downloading and compiling the MapR-DB Rest Application
The following instructions will first setup the directory structure in MapR-FS, download the MapR-DB Rest Application, compile it and finally launch it.
As user MapR
# cd /mapr/demo.mapr.com/ # chmod 777 apps # mkdir apps/blog # chmod 777 apps/blog # cd /home/mapr # git clone https://github.com/mapr-demos/maprdb-ojai-rest-sample.git # cd maprdb-ojai-rest-sample/ # mvn clean package
Finally start the program by typing the following command. Please note this will lock the console so you may need another console into the cluster for additional commands to be run.
# mvn exec:java -Dexec.mainClass="com.mapr.db.samples.rest.Main"
Please note sometimes port 8080 is already in use, this can be altered by changing the ports in the following file and then recompiling the app.
/home/mapr/maprdb-ojai-rest-sample/src/main/java/com/mapr/db/samples/rest/ Main.java
Explore the MapR-DB Rest Application
Please feel free to explore the MapR-DB Rest Application and create as many articles for your blog as you require for demonstration or testing purposes.
Once the server is started you can access the Swagger UI using the following URI:
- http://<ip_address>:8080/swagger
Or the Web applications
- http://<ip_address>:8080/app/#/
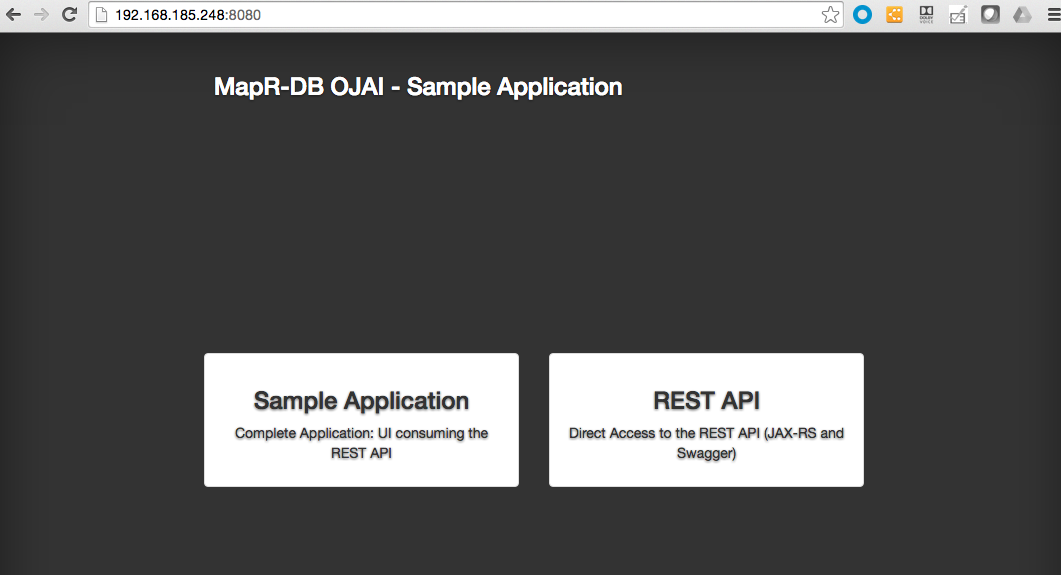
You can use the Web application to create a user and a blog post.
Then in the Swagger UI you can discover some interesting features:
- Create user from a predefined JSON Object
{"_id":"2","first_name":"Leon","last_name":"Clayton","age":"46"}{"title":"Article1","content":"Here is the content","author":{"name":"leon clayton","id":"1"}}- List users using a simple projection
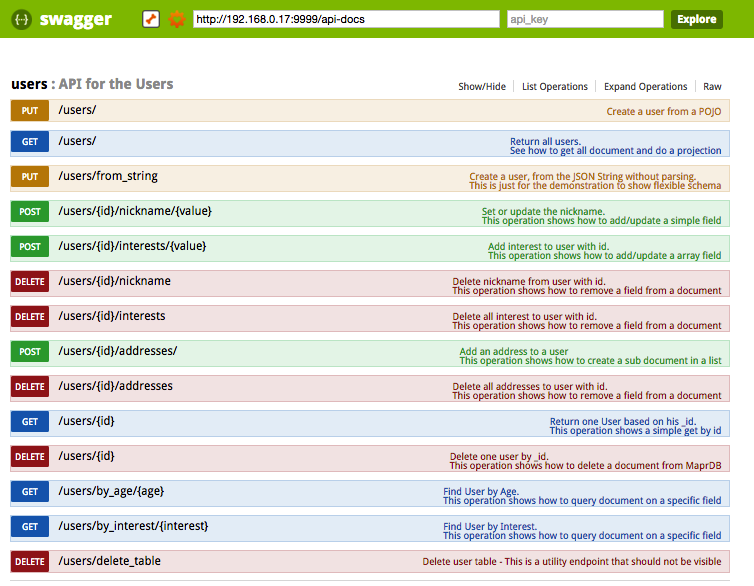
- Update user to add a nickname, add interests, and remove these attributes. You see here the flexible schema in action
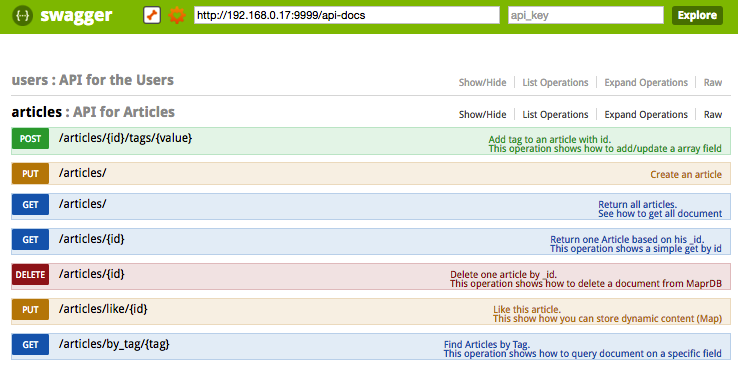
Similar features are exposed in the Articles REST API
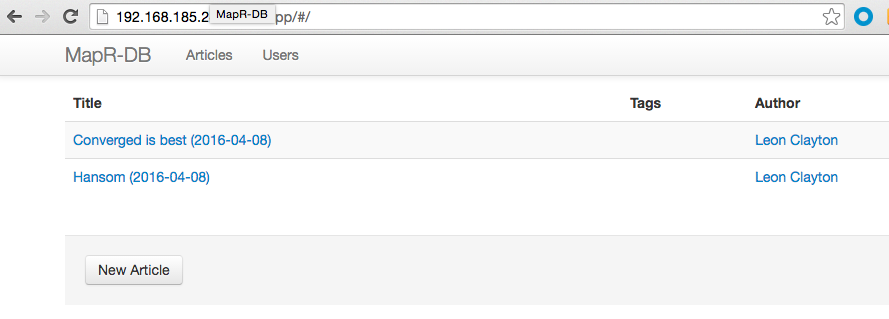
After you have created some users and posts we can now use Apache Drill to access the same MapR-DB JSON tables.
Installing Apache Drill
If you are using the MapR Sandbox you should already have Apache Drill installed, but if your installation does not have Apache Drill installed then please follow the instructions below.
As root we need to install Apache Drill 1.6 or higher. First clean and update the yum cache to make sure we get the latest package.
# su - root # yum clean all # yum makecache
Please make sure the following says Drill 1.6 or higher before continuing. This will download 300 MB so it may take some time.
# yum install mapr-drill Loaded plugins: fastestmirror, security Setting up Install Process Loading mirror speeds from cached hostfile * base: mirror.vorboss.net * epel: www.mirrorservice.org * extras: mirror.vorboss.net * updates: mirror.vorboss.net Resolving Dependencies --> Running transaction check ---> Package mapr-drill.noarch 0:1.6.0.201603302146-1 will be installed --> Finished Dependency Resolution
Get the new server to pick up Apache Drill
# /opt/mapr/server/configure.sh -R Configuring Hadoop-2.7.0 at /opt/mapr/hadoop/hadoop-2.7.0 Done configuring Hadoop Node setup configuration: cldb drill-bits fileserver hbasethrift hbinternal historyserver hivemetastore hiveserver2 hue nfs nodemanager oozie resourcemanager spark-historyserver webserver zookeeper Log can be found at: /opt/mapr/logs/configure.log setting CATALINA_OPTS="$CATALINA_OPTS -Xmx1024m" New Oozie WAR file with added 'Hadoop JARs, ExtJS library, JARs' at /opt/mapr/oozie/oozie-4.2.0/oozie-hadoop1.war New Oozie WAR file with added 'Hadoop JARs, ExtJS library, JARs' at /opt/mapr/oozie/oozie-4.2.0/oozie-hadoop2.war INFO: Oozie is ready to be started->
Analyzing the MapR-DB JSON tables using Apache Drill
Lets use the Apache Drill GUI to look at the tables the OJAI application has just created. Apache Drill can be driven by any BI tool via ODBC or JDBC connections. In the following example i have used the Drill’s web interface but you could easily use anything you want here.
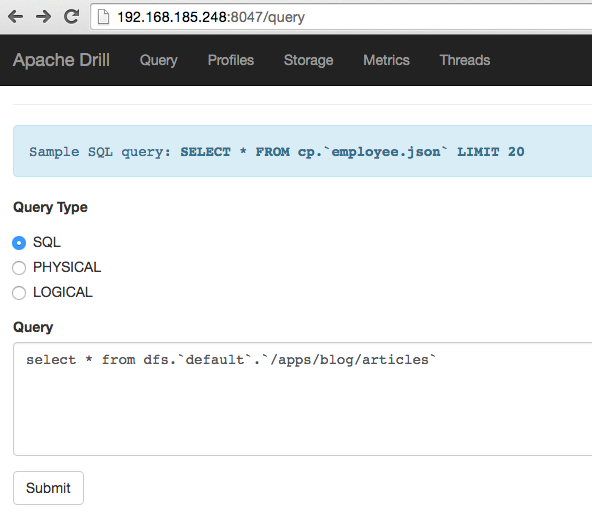
Goto port 8047 on the sandbox and you will see a query option. In the query type the following and press submit.
select * from dfs.`default`.`/apps/blog/articles`
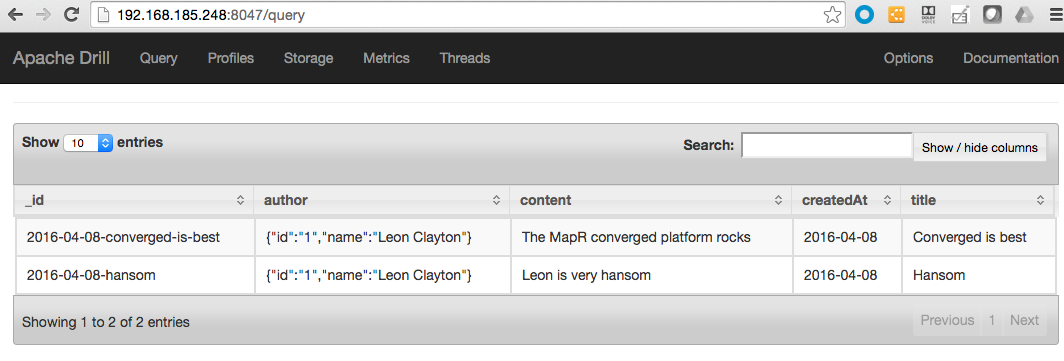
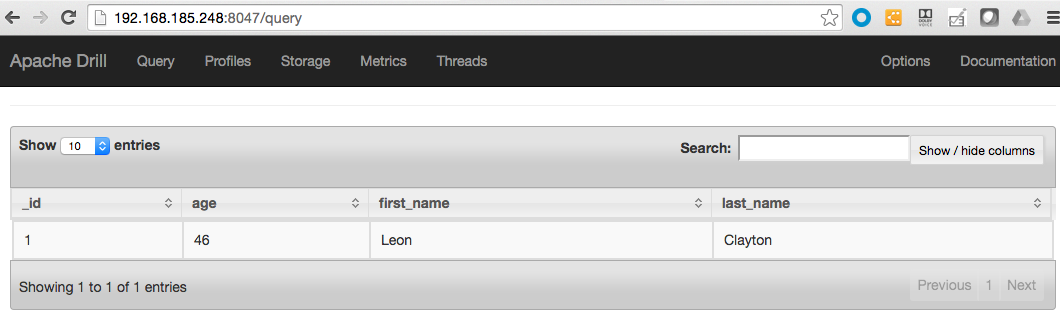
You will see the following results.
A second test is the following query
select * from dfs.`default`.`/apps/blog/users`
Here in this article we explored how to setup an application running on top of MapR-DB JSON Tables and how to query that data without having to move or transform the data from its original storage format. Since JSON is self describing, this enables others to be able to easily understand and query the data structures being used. This is a very powerful feature that can be leveraged to streamline application development and analytics. I hope you found this useful.
| Reference: | How to Build Applications on a NoSQL Document Database and Perform Analytics in Place from our JCG partner Chase Hooley at the Mapr blog. |
