A question raises spontaneously: why Eventual Consistency? Isn’t ACID enough? Let’s try to understand the need for Eventual Consistency guarantees when we talk about Distributed Computing on large scale, and of course Data is involved.
With the advent of Internet and Cloud services, Databases and more in general Data Storage technologies have undergone a radical change: scaling out systems over replicated nodes, instead of scaling up computational resources on a single node, or very few ones. The paradigm shift was needed to accomodate the growing volume of transactions and scale. A brand new paradigm induced new design techniques summarized by the claims of the CAP Theorem.
Hereafter, a picture tries to summarize the concept said above. In particular, transactions and scale growth are depicted making use of database technologies.
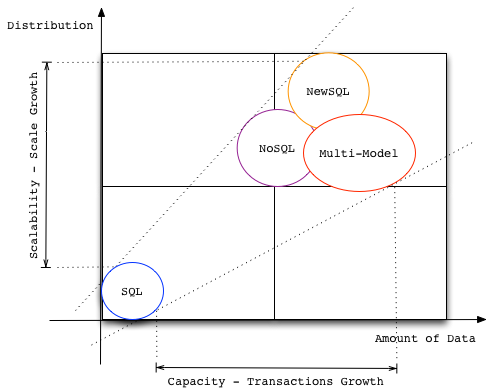
Now, let’s go through a few main concepts.
About Consistency in Distributed Systems
In a broad sense, Consistency among replicas in distributed systems can be intended as Weak or Strong.
Weak Consistency – Replicas misalignment is tolerated
Normally, it is not guaranteed that at any time replicas in a distributed system are aligned: for some reason, inconsistency windows can be experienced, and have to be tolerated.
Weak Consistency can be further classified in Eventual and Strong-Eventual.
Eventual
Replicas in a distributed system will eventually be consistent, if updates stop. Conflicts like stale read or concurrent writes can happen, as summarized below.
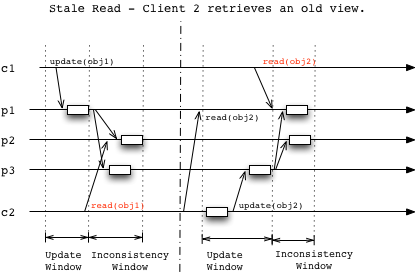
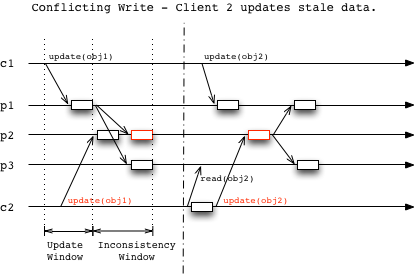
Strong-Eventual
A guarantee that can be achieved in case Conflict-free Replicated Data Types (CRDT) are used. According to such guarantee, conflicts cannot happen, the replicas will be eventually consistent.
Strong Consistency – Replicas misalignment is considered like a failure
At any time, replicas are consistent this means: no matter on which replica the status is read, the outcome will be the same as it was read by any other replica.
About CAP Theorem
CAP is an acronym for Consistency, Availability and Partitioning. The CAP Theorem states that in a Distributed System, on a large scale network, it is impossible to meet the three properties, a trade-off is needed. This impossibility result comes from unavoidable network partitioning: once partitioned, participants of a distributed system get isolated and are not able to communicate anymore, this circumstance heavily impacts the replication mechanisms. In case of network partitioning, if strong consistency is enforced, very long times can be spent in syncing the replicas up, strongly impacting the services availability; on the other hand, if the availability wants to be preserved (isolated replicas still continue serving according to their own state), consistency has to be relaxed to an eventual consistency (as soon as the network connectivity will be restored, the sync up will be done).
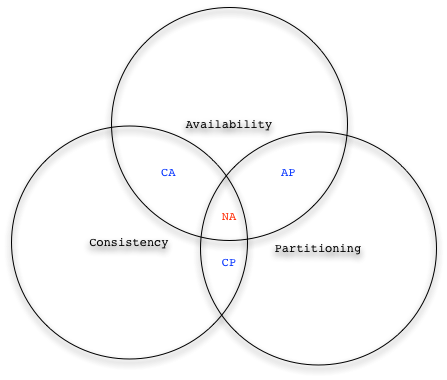
ACID Vs BASE
ACID is an acronym for Atomicity, Consistency, Isolation and Durability. It is a set of properties that are normally desired in transactional contextes. On the other hand, BASE is an acronym for Basically Available, Soft state and Eventual consistent. It is a set of properties often respected in distributed systems that preserve Availability in case of Network Partitioning, and prefer to resolve conflicts as soon as network connectivity is restored.
As clear, transactions as well as transactionality have to be rethought in distributed: BASE is the guarantee offered by NoSQL technologies able to scale over multiple regions; instead, ACID is the guarantee offered by traditional SQL databases able to scale up on a single machine, but struggle to scale out in active-active configurations (the time spent for 2 phase commit operations heavily impact the performances and so the scalability).
Demystifying Eventual Consistency
Eventual Consistency does not mean lack of transactionality, neither lack of consistency, it only means: the overall Distributed System will converge to a coordinated and consistent global state in a non-predictable time frame. In other words: after an update and in case of no successive updates, at a certain point in time, the system will converge to a consistent state, but since the network is supposed to be asynchronous and partition-prone no one can tell or predict how much time the convergence will take.
From a local perspective (one or a quorum of nodes in a region), transactions are to be intended as always, almost in the traditional sense; the scenario changes when the consistency is observed from the global state perspective (set of replicated nodes over regions): a global snapshot can likely spot slight inconsistencies among the nodes, due to many causes like drift in the propagation delay, partitioning, etc.
Systems in the regime of Eventual Consistency suffer of conflicts: every time concurrent modifications of not synced data happen, a conflict raises up. Such conflicts can be managed applying the concept of vector clocks and time machines: each data has a story in time, and progressive versions, the easiest way to solve a conflict consists in spotting the time frame where the conflict happened, and so undo the changes up to the stable version and reapply the updates in order – an intrinsic concept of state machine is sketched by this approach.
Eventually, all reads among the replicas will provide the same output, the point: it is impossible a-priori to establish the time when all replicas will be aligned. Such guarantee may be not acceptable in business-critical contexts where each transaction equates to money; but, on the average case of Internet and Cloud Services, eventual consistency can be tolerated in favor of Availability and Resistance to Network Partitioning. A good example of Eventual Consistent Data Store is the DNS, a scalable and fully distributed directory service at the backbone of today’s Internet. How the DNS works: from central registries the data is propagated among the recursive resolvers, and then stub resolvers, but on the path towards the final client service many levels of caching are passed through.
Thoughts
According to the proposed picture, SQL is a rock-solid piece of technology that has served for many years now; modern volumes of data, mostly considering Internet and Cloud services, create some difficulties to SQL: relational databases have not been designed to scale out, so propagating ACID transactions over a multitude of distributed machines requires a trade-off, strongly impacting the Availability of the overall systems (i.e. long stop-the-world times to align the replicas synchronously).
NoSQL technologies born around 2010 to accomodate modern design paradigms and to overcome the said SQL limitations. At the foundation of most of the NoSQL databases there is the concept of Eventual Consistency, intended as a made trade-off to ensure a better global Availability. Such technological supports have demonstrated their helpfulness in building most of the online e-Commerce services out there, even guaranteeing only Eventual Consistency – yep, Eventual Consistency is not Evil.
Emerging technologies like NewSQL addressed the consistency concern, and tried to come up with a modern design of SQL databases able to scale on geographic regions, without trading-off either Availability, or Consistency. First deploy of these technological supports, like Google Spanner, confirms that it is possible to propagate ACID-like transactions on the scale without heavily impacting Availability – replication latency stays low using consensus protocols like Paxos/Raft.
An Answer
Concluding, and answering the initial question: Eventual Consistency is a successful trade-off in ultra-large-scale systems design, vastly applied in the Industry whenever a scale out on geographical regions is needed. Recent technologies propose stronger Consistency guarantees on distributed Relational Data, and this is the case of NewSQL databases.
Anyway, for systems that not necessarily need strong consistency, eventual consistency can be considered as a win-win trade-off to scale out a system with confidence: of course, a mindset shift and dedicated design have to be applied in order to successfully adopt such scalable paradigm.
| Reference: | Pills of Eventual Consistency from our JCG partner Paolo Maresca at the TheTechSolo blog. |
