Every now and then, I get questions around optimising Camel applications with the argument that Camel is slow. Camel is just the glue connecting disparate systems, the routing engine is all in-memory, and it doesn’t require any persistent state. So 99% of the cases, performance issues are due to bottlenecks in other systems, or having the application design done without performance considerations. If that is the case, there isn’t much you can achieve by tuning Camel further, and you have to go back to the drawing board.

But sometimes, it might be worth squeezing few more milliseconds from your Camel routes. Tuning every application is very specific and dependent on the technology and the use case. Here are some ideas for tuning Camel based systems, which may apply for you (or not).
Endpoint Tuning
Endpoints in Camel are the integration points with other systems and the way they are configured will have a huge impact on the performance of the system. Understanding how different endpoints work and tuning those should be the one of the first places to start with. Here are few examples:
- Messaging – If your Camel application is using messaging, the overall performance will be heavily dependent on the performance of the messaging system. There are too many factors to consider here, but main ones are:
- Message broker – the network and disk speed, combined with the broker topology will shape the broker performance. To give you an idea, with ActiveMQ, a relational database based persistent store will perform around 50% of a file based store, and using network of brokers to scale horizontally will cost another 30% of performance. It is amazing how one configuration change in ActiveMQ can have huge impact on the messaging system and then the Camel application . There is a must read ActiveMQ tuning guide by Red Hat with lot’s of details to consider and evaluate. Also a real life example from Chrisitan Posta showing how to speed up the broker 25x times in certain cases.
- Message client – if performance is a priority, there are also some hacks you can do on the ActiveMQ client side, such as: increasing TCP socketBufferSize and ioBufferSize, tuning the OpenWire protocol parameters, using message compression, batch acknowledgements with optimizeAcknowledge, asynchronous send with useAsyncSend, adjusting pre-fetch limit, etc. There are some nice slides again from Christina here and old but still very relevant video from Rob Davies about tuning ActiveMQ. All of these resources should give you enough ideas to experiment and improve the performance from messaging point of view.
-
Database writes – use batching whenever possible. You can use an aggregator to collect a number of entries before performing a batch operation to interact with the database (for example with the SQL component.
return new RouteBuilder() { public void configure() throws Exception { from("direct:start") .aggregate(header("PROD_TYPE"), new SQLStrategy()).completionSize(100).completionTimeout(1000) .to("sql:insert into products (price, description) values (#, #)?batch=true"); } }; - Working with templates – if you have to use a template component as part of the routing, try out the existing templating engines (FreeMarker, Velocity, SpringTeplate, Mustache, Chunk ) with a small test as the following one and measure which one performs better. There is a great presentation titled Performance optimisation for Camel by Christian Mueller with the source code supporting the findings. From those measurements we can see that FreeMarker performs better than Velocity and SprintTemplates in general.
- Using Web Services – whenever you have to use a web endpoint, the web container itself (has to be tuned separately. From Camel endpoint point of view, you can further optimise a little bit by skipping the unmarshalling if you don’t need Java objects, and using asynchronous processing.
- concurrentConsumers – there are a number of components (Seda, VM, JMS, RabbitMQ, Disruptor, AWS-SQS, etc) that support parallel consumption. Before using an endpoint, check the component documentation for thread pool or batch processing capabilities. To give you an idea, see how Amzon SQS processing can be improved through these options.
Data Type Choice
The type and the format of the data the is passing through Camel routes will also have performance implications. To demonstrate that let’s see few examples.
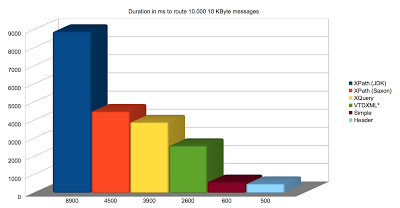
- Content based router, splitter, filter are examples of EIPs that perform some work based on the message content. And the type of the message affects the processing speed of these elements. Below is a chart from Christian Mueller’s presentation, visualising how Content Based Router is performing with different kinds of messages:

Content Based Routing based on different data types For example, if you have a large XML document in the Exchange, and based on it you perform content based routing, filtering, etc., that will affect the speed of the route. Instead you can extract some key information from the document and populate the Exchange headers for faster access and routing later.
- Marshaling/Unmarshaling – similarly to the templating engines, different data format covenrtors perform differently. To see some metrics check again Christian’s presentation, but also keep in mind that performance of the supported data formats may vary between different versions and platforms so measure it for your use case.
- Streaming – Camel streaming and stream caching are one of the underrated features that can be useful for dealing with large messages.
- Claim check EIP – if the application logic allows it, consider using claim check pattern to improve performance and reduce resource consumption.
Multithreading
Camel offers multithreading support in a number of places. Using those can improve the application performance too.
- Paralel processing EIPs – the following Camel EIP implementations support parallel processing – multicast, recipient list, splitter, delayer, wiretap, throttler, error handler. If you are going to enable parallel processing for those, it would be even better if you also provide a custom thread pool specifically tuned for your use case rather than relying on Camel’s default thread pool profile.
- Threads DSL
construct – some Camel endpoints (such as the File consumer) are single threaded by design and cannot be parallelized at endpoint level. In case of File consumer, a single thread picks a file at a time and processes it through the route until it reaches the end of the route and then the consumer thread picks the next file. This is when Camel Threads construct can be useful. As visualised below, File consumer thread can pick a file and pass it to a thread from the Threads construct for further processing. Then the File consumer can pick another file without waiting for the previous Exchange to complete processing fully.

Parallel File Consuming - Seda component – Seda is another way to achieve parallelism in Camel. The Seda component has in-memory list to accumulate incoming messages from the producer and concurrentConsumers to process those incoming request in parallel by multiple threads.
- Asynchronous Redelivery/Retry – if you are using an error handler with a redelivery policy as part of the routing process, you can configure it to be asynchronous and do the redeliveries in a separate thread. That will use a separate thread pool for the redelivery not block the main request processing thread while waiting. If you need long delayed redeliveries, it might be a better approach to use ActiveMQ broker redelivery (that is different from consumer redelivery BTW) where the redeliveries will be persisted on the message broker and not kept in Camel application memory. Another benefit of this mechanism is that the redeliveries will survive application restart and also play nicely when the application is clustered. I have described different retry patterns in Camel Design Patterns book.

Other Optimisations
There are few other tricks you can do to micro-tune Camel further.
- Logging configurations – hopefully you don’t have to log every message and its content on the production environment. But if you have to, consider using some asynchronous logger. On a high throughput system, ane option would be to log statistics and aggregated metrics through Camel Throughput logger. Throughput logger allows logging aggregated statistics on fixed intervals or based on the number of processed messages rather than per message bases. Another option would be to use the not so popular Camel Sampler EIP and log only sample messages every now and then.
- Disable JMX – by default, Camel JMX instrumentation is enabled which creates a lot of MBeans. This allows monitoring and management of Camel runtime, but also has some performance hit and requires more resources. I still remember the time when I had to fully turn off JMX in Camel in order to run it with 512MB heap on a free AWS account. As a minimum, consider whether you need any JMX enabled at all, and if so whether to use RoutesOnly, Default or Extended JMX profiles.
- Message Histroy – Camel implements the Message History EIP and runs it by default. While on development environmnet, it might be useful to see every endpoint a message has been too, but on the produciton environment you might consider to disable this feature.
- Original message – Every Camel route will make a copy of the original incoming message before any modifications to it. This pristine copy of the message is kept in case it is needed to be redelivered during error handling or with onCompletion construct. If you are not using these features, you can disable creating and storing the original state of every incoming message.
- Other customisations – Almost every feature in CamelContext can be customized. For example you can use lazyLoadTypeConverters for a faster application startup, or configure the shutdownStrategy for a quicker shutdown when there are inflight messages, or a use a custom UuidGenerator that performs faster, etc.
Application design
All of the previous tunings are micro optimizations compared to the application design and architecture. If your application is not designed for scalability and performance, sooner or later the small tuning hacks will hit their limit. The chances are, what you are doing has been done previously, and instead of reinventing the wheel or coming up with some clever designs, learn from the experience of others and use well known patterns, principles and practises. Use principles from SOA, Microservices architectures, resiliency principles, messaging best practises, etc. Some of those patterns such as Parallel Pipelines, CQRS, Load Leveling, Circuit Breaker are covered in Camel Design Patterns book and do help to improve the overall application design.
JVM
There are many articles about JVM tuning. Here I only want to mention the JVM configuration generation application by Red Hat. You can use it as long as you have a Red Hat account (which is free for developers anyway).
OS
You can squeeze the application only so much. In order to do proper high load processing, tuning the host system is a must too. To get an idea for the various OS level options, have a look at the following check list from the Jetty project.
In Conclusion
This article is here just to give you some ideas and show you the extend of the possible areas to consider when you have to improve the performance of a Camel application. Instead of looking for a magical recipe or go through a checklist, do small incremental changes supported by measurements until you get to a desired state. And rather than focusing on micro optimisations and hacks, have an holistic view of the system, get the design right, and start tuning from the host system, to JVM, CamelContext, routing elements, endpoints and the data itself.
Using well known patterns, principles and practises with focus on simple and scalable design is a good start. Good luck.
| Reference: | Performance Tuning Ideas for Apache Camel from our JCG partner Bilgin Ibryam at the OFBIZian blog. |

There is a typo here: Message Histroy