This is a tale of two siloed clusters. The first cluster is an Apache Hadoop cluster. This is an island whose resources are completely isolated to Hadoop and its processes. The second cluster is the description I give to all resources that are not a part of the Hadoop cluster. I break them up this way because Hadoop manages its own resources with Apache YARN (Yet Another Resource Negotiator). Which is nice for Hadoop, but all too often those resources are underutilized when there are no big data workloads in the queue. And then when a big data job comes in, those resources are stretched to the limit, and they are likely in need of more resources. That can be tough when you are on an island.
Hadoop was meant to tear down walls — albeit, data silo walls — but walls, nonetheless. What has happened is that while tearing some walls down, other types of walls have gone up in their place.
Another technology, Apache Mesos, is also meant to tear down walls — but Mesos has often been positioned to manage the “second cluster,” which are all of those other, non-Hadoop workloads.
This is where the story really starts, with these two silos of Mesos and YARN. They are often pitted against each other, as if they were incompatible. It turns out they work together, and therein lies my tale.
Brief explanation of Mesos and YARN
The primary difference between Mesos and YARN is around their design priorities and how they approach scheduling work. Mesos was built to be a scalable global resource manager for the entire data center. It was designed at UC Berkeley in 2007 and hardened in production at companies like Twitter and Airbnb. YARN was created out of the necessity to scale Hadoop. Prior to YARN, resource management was embedded in Hadoop MapReduce V1, and it had to be removed in order to help MapReduce scale. The MapReduce 1 JobTracker wouldn’t practically scale beyond a couple thousand machines. The creation of YARN was essential to the next iteration of Hadoop’s lifecycle, primarily around scaling.
Mesos scheduling
Mesos determines which resources are available, and it makes offers back to an application scheduler (the application scheduler and its executor is called a “framework”). Those offers can be accepted or rejected by the framework. This model is considered a non-monolithic model because it is a “two-level” scheduler, where scheduling algorithms are pluggable. Mesos allows an infinite number of schedule algorithms to be developed, each with its own strategy for which offers to accept or decline, and can accommodate thousands of these schedulers running multi-tenant on the same cluster.
The two-level scheduling model of Mesos allows each framework to decide which algorithms it wants to use for scheduling the jobs that it needs to run. Mesos plays the arbiter, allocating resources across multiple schedulers, resolving conflicts, and making sure resources are fairly distributed based on business strategy. Offers come in, and the framework can then execute a task that consumes those offered resources. Or the framework has the option to decline the offer and wait for another offer to come in. This model is very similar to how multiple apps all run simultaneously on a laptop or smartphone, in that they spawn new threads or request more memory as they need it, and the operating system arbitrates among all of the requests. One of the nice things about this model is that it is based on years of operating system and distributed systems research and is very scalable. This is a model that Google and Twitter have proven at scale.
YARN scheduling
Now, let’s look at what happens over on the YARN side. When a job request comes into the YARN resource manager, YARN evaluates all the resources available, and it places the job. It’s the one making the decision where jobs should go; thus, it is modeled in a monolithic way. It is important to reiterate that YARN was created as a necessity for the evolutionary step of the MapReduce framework. YARN took the resource-management model out of the MapReduce 1 JobTracker, generalized it, and moved it into its own separate ResourceManager component, largely motivated by the need to scale Hadoop jobs.
YARN is optimized for scheduling Hadoop jobs, which are historically (and still typically) batch jobs with long run times. This means that YARN was not designed for long-running services, nor for short-lived interactive queries (like small and fast Spark jobs), and while it’s possible to have it schedule other kinds of workloads, this is not an ideal model. The resource demands, execution model, and architectural demands of MapReduce are very different from those of long-running services, such as web servers or SOA applications, or real-time workloads like those of Spark or Storm. Also, YARN was designed for stateless batch jobs that can be restarted easily if they fail. It does not handle running stateful services like distributed file systems or databases. While YARN’s monolithic scheduler could theoretically evolve to handle different types of workloads (by merging new algorithms upstream into the scheduling code), this is not a lightweight model to support a growing number of current and future scheduling algorithms.
Is it YARN vs Mesos?
When comparing YARN and Mesos, it is important to understand the general scaling capabilities and why someone might choose one technology over the other. While some might argue that YARN and Mesos are competing for the same space, they really are not. The people who put these models in place had different intentions from the start, and that’s OK. There is nothing explicitly wrong with either model, but each approach will yield different long-term results. I believe this is the key between when to use one, the other, or both. Mesos was built at the same time as Google’s Omega. Ben Hindman and the Berkeley AMPlab team worked closely with the team at Google designing Omega so that they both could learn from the lessons of Google’s Borg and build a better non-monolithic scheduler.
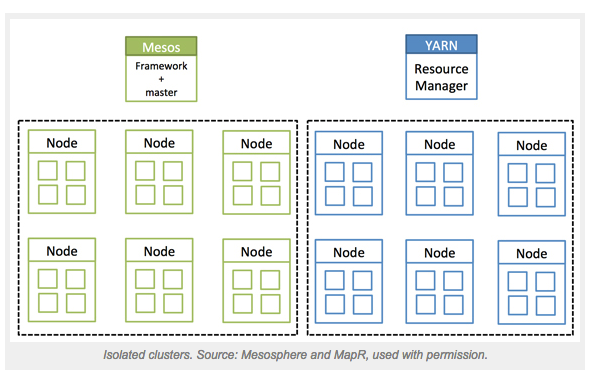
When you evaluate how to manage your data center as a whole, you’ve got Mesos on one side that can manage all the resources in your data center, and on the other, you have YARN, which can safely manage Hadoop jobs, but is not capable of managing your entire data center. Data center operators tend to solve for these two use cases by partitioning their clusters into Hadoop and non-Hadoop worlds.
Using Mesos and YARN in the same data center, to benefit from both resource managers, currently requires that you create two static partitions. Using both would mean that certain resources would be dedicated to Hadoop for YARN to manage and Mesos would get the rest. It might be over simplifying it, but that is effectively what we are talking about here. Fundamentally, this is the issue we want to avoid.
Introducing project Myriad
This leads us to the question: can we make YARN and Mesos work together? Can we make them work harmoniously for the benefit of the enterprise and the data center? The answer is yes. A few well-known companies — eBay, MapR, and Mesosphere — collaborated on a project called Myriad.
This open source software project is both a Mesos framework and a YARN scheduler that enables Mesos to manage YARN resource requests. When a job comes into YARN, it will schedule it via the Myriad Scheduler, which will match the request to incoming Mesos resource offers. Mesos, in turn, will pass it on to the Mesos worker nodes. The Mesos nodes will then communicate the request to a Myriad executor which is running the YARN node manager. Myriad launches YARN node managers on Mesos resources, which then communicate to the YARN resource manager what resources are available to them. YARN can then consume the resources as it sees fit. Myriad provides a seamless bridge from the pool of resources available in Mesos to the YARN tasks that want those resources.
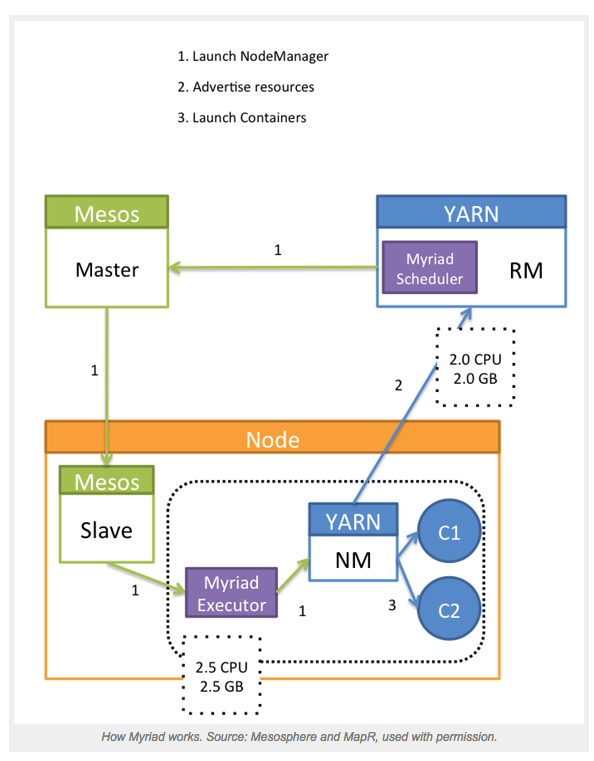
The beauty of this approach is that not only does it allow you to elastically run YARN workloads on a shared cluster, but it actually makes YARN more dynamic and elastic than it was originally designed to be. This approach also makes it easy for a data center operations team to expand resources given to YARN (or, take them away as the case might be) without ever having to reconfigure the YARN cluster. It becomes very easy to dynamically control your entire data center. This model also provides an easy way to run and manage multiple YARN implementations, even different versions of YARN on the same cluster.
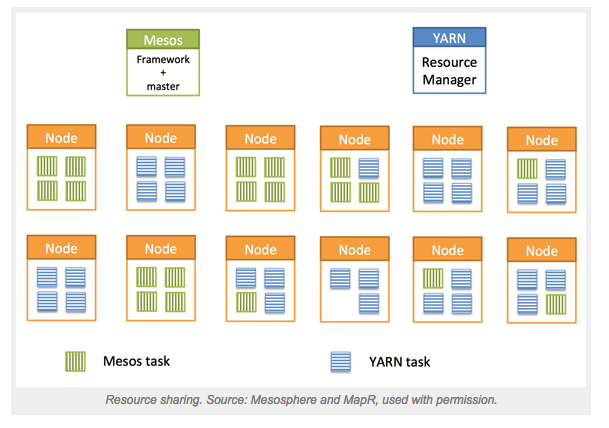
Myriad blends the best of both the YARN and Mesos worlds. By utilizing Myriad, Mesos and YARN can collaborate, and you can achieve an as-it-happens business. Data analytics can be performed in-place on the same hardware that runs your production services. No longer will you face the resource constraints (and low utilization) caused by static partitions. Resources can be elastically reconfigured to meet the demands of the business as it happens.
Final thoughts
To make sure people understand where I am coming from here, I feel that both Mesos and YARN are very good at what they were built to achieve, yet both have room for improvement. Both resource managers can improve in the area of security; security support is paramount to enterprise adoption.
Mesos needs an end-to-end security architecture, and I personally would not draw the line at Kerberos for security support, as my personal experience with it is not what I would call “fun.” The other area for improvement in Mesos — which can be extremely complicated to get right — is what I will characterize as resource revocation and preemption. Imagine the use case where all resources in a business are allocated and then the need arises to have the single most important “thing” that your business depends on run — even if this task only requires minutes of time to complete, you are out of luck if the resources are not available. Resource preemption and/or revocation could solve that problem. There are currently ways around this in Mesos today, but I look forward to the work the Mesos committers are doing to solve this problem with Dynamic Reservations and Optimistic (Revocable) Resources Offers.
Myriad is an enabling technology that can be used to take advantage of leveraging all of the resources in a data center or cloud as a single pool of resources. Myriad enables businesses to tear down the walls between isolated clusters, just as Hadoop enabled businesses to tear down the walls between data silos. With Myriad, developers will be able to focus on the data and applications on which the business depends, while operations will be able to manage compute resources for maximum agility. This opens the door to being able to focus on data instead of constantly worrying about infrastructure. With Myriad, the constraints on the storage network and coordination between compute and data access are the last-mile concern to achieve full flexibility, agility, and scale.
- Project Myriad is hosted on GitHub and is available for download.
There’s documentation there that provides more in-depth explanations of how it works. You’ll even see some nice diagrams. Go out, explore, and give it a try.
Editor’s Note: This post was originally published on O’Reilly Radar here.
| Reference: | Mesos and YARN: A tale of two clusters from our JCG partner Jim Scott at the Mapr blog. |
