I am very pleased to be given the opportunity to guest blog on the MapR site, leveraging a blog which was published on the DataTorrent web site on Sep 9, 2015. MapR is one of our key strategic partners in the Hadoop and big data ecosystem. We share a lot of the same philosophies and guiding principles—like providing our customers and users with a true enterprise-grade product and a very fault-tolerant, highly-available system. We are also very pleased to be working with MapR on a series of business and partnership initiatives. We are looking forward to the Meetup coming up next week, sponsored and hosted by MapR at their office.
In this blog post, I would like to provide some detail on what Apache Apex is, and why it’s important.
Apache Hadoop has been around for over a decade. It has become the de facto big data platform, allowing enterprises to transform their business operations by turning big data into something useful, meaningful, and revenue-generating. Hadoop promised the enablement of big data without incurring the costs you would normally think such powerful processing systems would demand. This tremendous promise of transforming business operations continues to fuel high growth in the industry.
It all got started when Hadoop engineers at Yahoo! asked, “How can we build an efficient search indexing capability?” The ensuing iterations and some inspiration resulted in the MapReduce programming model. Although powerful, MapReduce wasn’t perfect. Mastering MapReduce required a steep learning curve. Migrating applications to MapReduce required an almost complete rewrite. Equally worrisome was the fact that MapReduce had a batch processing paradigm and “compute going to data” at its core, thus posing a deterrent to Hadoop realizing its true potential. Expectedly enough, MapReduce was an impediment that did little to bolster productization of big data. Not to be deterred, there were faster substitutes for MapReduce. Just like Hadoop, these models required deeper expertise, were tough to operate and difficult to master. As such, Hadoop disrupted the way big data needs were handled, but remained largely under-productized. A decade after Hadoop was started, only a small percentage of big data projects are in production. Data is growing rapidly and the ability to harness big data has become a decisive competitive advantage. MapReduce impedes this demand (actually more of a scramble) to transform into a data-driven business.
In hindsight, it is clear that in the early days, the subsequent success of Hadoop was not anticipated. If they had anticipated Hadoop’s success, the question would have been, “What can we do with massively distributed resources?” The answer to this question, which came about soon after, was YARN (Hadoop 2.0), the next generation Hadoop. For the first time, YARN brought the capability of exploring how distributed resources handling big data could perform “a lot of things,” thus going beyond the early MapReduce paradigm, and in a way beyond batch or even compute-going-to-data paradigms. YARN presented the capability to allow big data to not just become big in size, but broader in use cases. With its enabling capability as a Hadoop facilitator, YARN has pushed Hadoop towards realizing its true potential. The Hadoop predicament is similar to what cellphones would have been without the more popular features such as messaging and internet connectivity. In their early years, cell phones upset the landline market, but did not foster an immediate market furor until it transformed into the new-age “smartphone” with impressive features. YARN is most certainly the enabling factor for big data dreaming bigger and wider, and with it, Hadoop 2.0 is now a true de facto distributed operating system.
What’s needed is bleeding edge YARN-based platforms capable of radically realizing Hadoop’s potential
Now is the right time to not only productize big data, but to see how setting it in motion can ensure realization of greater business goals. A Herculean task, this demands platforms that are easy to deploy, require nothing beyond everyday IT expertise, and can effortlessly integrate with an existing IT infrastructure while ensuring ease of migration. The new age Hadoop platforms need to be designed with an approach to reduce time-to-market by shortening the application lifecycle, from building to launching, thus quickening the realization of revenue for businesses. They will also have to reduce time for developers to develop, DevOps to operationalize, and finally reduce time to insight for business. Platforms such as these will need to learn, adapt, and change to meet the burgeoning needs of the big data world.
Let’s take a look at the top precepts of building these platforms:
- Simplicity and Expertise
It is very hard to fully comprehend big data, but what can be done instead is keeping the platforms simple and free from requiring deep expertise, all the while promising easy migration. The focus should be on “use the current expertise to get more,” whether it means simple workflow, or a simple API. A simple API will do away with the need for extensive changes while interacting with the Hadoop ecosystem, thus making the platform viable and sufficient to address growing data needs. Big data must move away from “learn the expertise of a new paradigm and get a high salary.” Smart phones are not adding an excessive burden to learn something new, so why should big data? The motto must be “be open, have a simple API, and continue to retain its simplicity.” In simple terms, the platform must enable user-defined functions (UDF) to leverage full features. Better yet, business logic should only be user-defined functions, and nothing more. - Code Reuse
Code reuse is to not just reuse a code in a single streaming application, but to use it anywhere, whether it is a streaming or batch job. Platforms for big data should be able to deftly handle batch as well as streaming jobs while enabling users to use their codes as is. That is why the platforms should leverage the data-in-motion architecture that allows for a unification of stream and batch processing. A platform that handles unbounded data can easily handle unbounded data. Additionally, with the data-in-motion architecture, results are processed almost instantaneously, thus reducing time and the cost required for business continuity. - Operability
In big data, the cost of functional development is at the most 20% (I am being lenient), while the cost of operability is at least 80% of the entire cost. In my Yahoo! days, we spent more than 80% of the resources on operational tasks. This was true in Yahoo! Hadoop as well as Yahoo! Finance. An ideal platform should support operability natively, not to be slapped on later. Businesses should be able to only focus on business logic, as that is best understood by them, and nothing more. Operational tasks are not their core expertise, and should be “outsourced” to the platform, and therefore, operability must work with user-defined code. This will enable a platform to suit unique business needs. Forcing operational aspects in user code indirectly causes big data projects to fail. - Leverage Investments in Hadoop
Lastly, the new age big data platform should be such that it realizes the extent of investments made in big data, namely Hadoop. It is already de facto, it already exists. The core of the Hadoop ecosystem (HDFS, YARN) is maturing fast. A new platform should be YARN native. The platforms must natively leverage all the maturity of Hadoop, and YARN in particular. As YARN matures, it will continue to improve on uptime, fault tolerance, security, multi-tenancy, and so on. The support and development cost structure of a native YARN platform will be much lower as compared to platforms that run external to YARN, or were not natively built for YARN. More YARN native features will result in fewer clusters, translating to higher operability.
Apache Apex is the industry’s first ever YARN native engine that fulfills the disruptive promise of big data
Because big data is tough to envisage in its entirety, the platform must be such that it posits to become the basis for driving big data processing needs, in a batch paradigm, streaming paradigm, or both. Apache Apex is the industry’s only open-source, enterprise-grade engine capable of handling batch data as well as streaming data needs. Apache Apex is groomed to drive the highest value for businesses operating in highly data-intensive environments.
Here is why Apache Apex is a go-to solution for bringing big data projects to success:
- Simplicity and Expertise
The Apache Apex API is very simple. An application is a directed acyclic graph (DAG) of multiple operators. The operator developer only needs to implement a simple “process()” call. This API allows users to plug in any function (or UDF) for processing incoming events. The single-thread execution and application-level JAVA expertise are the top reasons why Apex enables big data teams to develop applications within weeks, and allows them to go live in as little as three months. Not only is Apex simple to deploy and customize, but the expertise required to leverage its full capabilities is easily available. - Code Reuse
Developers require minimal training to build big data applications on Apache Apex. What’s more, they do not require significant changes in their business logic; a minimal tweaking of their existing code suffices. A complete separation of functional specification from operational specification greatly enhances the reuse of existing code. Additionally, Apex enables defining reusable modules. It enables the same business logic to be used for stream as well as batch. Apex is a data-in-motion platform that allows for a unification of processing of never-ending streams of unbounded data (streaming job), or bounded data in files (batch job). Organizations can build applications to suit their business logic, and extend the applications across both batch as well as streaming jobs. Apache Apex architecture can handle reading from and writing to message buses, file systems, databases or any other sources. As long as these sources have client code that can be run within a JVM, the integration works seamlessly. - Operability
The ability to read from a file is necessary, but not a sufficient aspect of using a data-in-motion platform for batch processing. The other aspect is that it must meet the enterprise operability SLA requirement. Apex is built for enhanced operability, such that applications built on Apex need only worry about the business logic. For native fault tolerance, the Apex platform ensures that data is not lost, master (metadata) is backed up, and equally importantly, the application state is retained in HDFS (a persistent store). Businesses can choose other persistent stores with an HDFS interface if need be. With Apex, fault tolerance is native to Hadoop and does not require an additional system outside of Hadoop to hold state, nor any extra code for users to write. Apex applications can recover from Hadoop outages from their last-known state that persists in HDFS. It is easy to run two Apex applications of different versions in the same Hadoop cluster, or even change applications dynamically. It is easy to operate and upgrade applications. No new scheduling overhead exists once the application is running, unless the change in resources is asked by the application or by YARN. Apex has in-built data-in-motion constructs that enable data flow to be in million(s) of events/second on a single core. Apex is thus an easy-to-leverage, highly scalable platform that is built on the same security standards as Hadoop.
This figure shows an Apex application running in a multi-tenant Hadoop cluster:
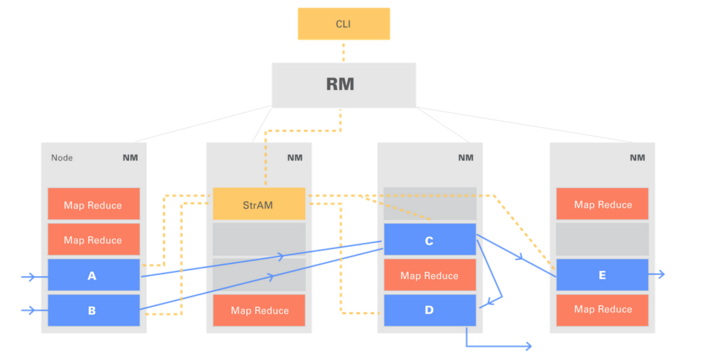
- Integration and Ease of Use
The Apex platform comes with support for web services and metrics. This enables ease of use and easy integration with current data pipeline components. DevOps teams can monitor data in action using existing systems and dashboards with minimal changes, thereby easily integrating with the current setup. With different connectors and the ease of adding more connectors, Apex easily integrates with an existing dataflow.
This figure shows the ease of integrating Apex with other sources/destinations:
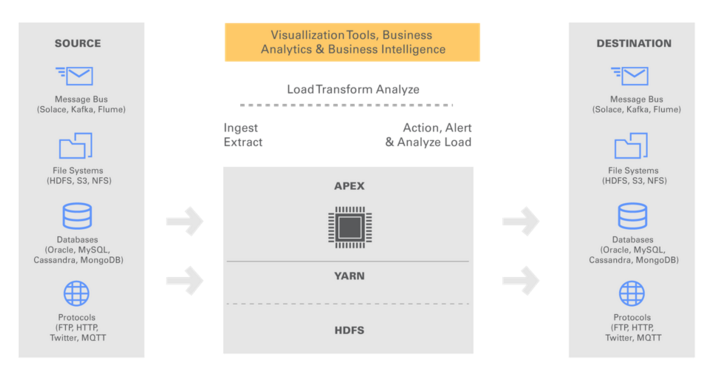
- Leverage Investments in Hadoop
Apex is a native YARN big data-in-motion platform with a vision of leveraging existing distributed operating systems, and not building another. Just like MapReduce, it does not have: Resource Scheduler and Management, Distributed File System, Security Setup, other common utilities available within a distributed operating system. Apex leverages all YARN features without an overlap with YARN, while using HDFS as the default persistent state store. All investments by enterprises in Hadoop in terms of expertise, hardware, and integration are leveraged. A rise in maturity of YARN will translate to a thoroughly mature platform capable of handling gigantic volumes of data, while ensuring the cost of operations never shoots out of the window.
This figure shows how Apex can be easily reused while leveraging investments in Hadoop:
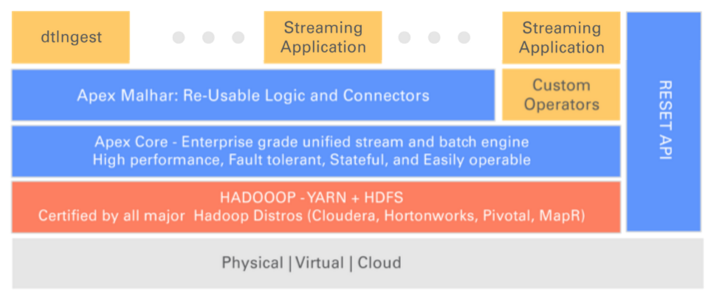
- Malhar
Apex comes with Malhar — a library of operators. These pre-built operators for data sources and destinations of popular message buses, file systems, and databases, enable organizations to experience accelerated development of business logic. This reduces the time-to-market significantly, allowing for greater success in developing and launching big data projects.
This figure shows different categories of operators in Malhar:
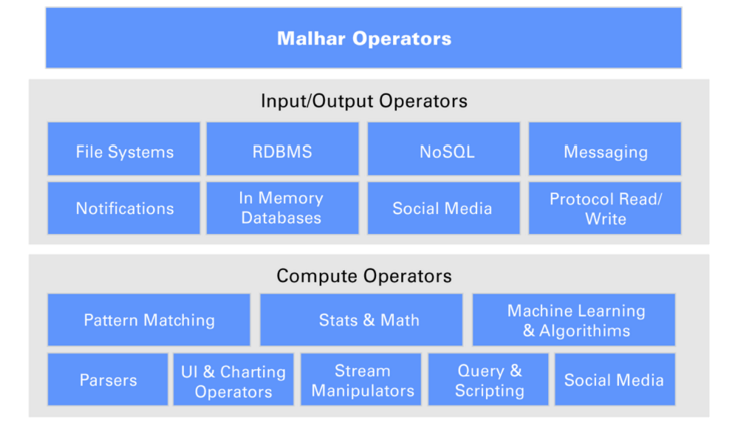
If you want to make a difference, become an Apex contributor. Join us in developing the industry’s only open source, enterprise-grade unified stream and batch platform! Apache Apex is a very open community, and we actively encourage participation as we plan to develop new functionality in an open, community-driven way:
- Apache Apex is incubating and its code is available in two gits, Apex-Core and Apex-Malhar. Join Apex community and do subscribe to our forum.
- Affiliations with Apache Apex include Apple, Barclays, CapitalOne, DataChief, E8security, General Electric, and Silver Spring Networks. We welcome everyone to join us on the path to develop the next generation ecosystem that will increase the success rate of big data projects.
- For updates, please join Apex Meetups.
| Reference: | Apache Apex: OSS Incubator Project for Batch and Stream Processing from our JCG partner Amol Kekre at the Mapr blog. |
