Overview
Apache Hive is an integral part of Hadoop eco-system. Hive can be defined as a data warehouse like software which facilitates query and large data management on HDFS (Hadoop distributed file system). One must remember that Hive is not data warehouse software rather it provides some mechanism to manage data on distributed environment and query it by using an SQL-like language called HiveQL or HIVE Query Language. Hive scripts can be defined as a group of Hive commands bundled together to reduce the execution time. In this article I will discuss about the Hive scripts and its execution.
Introduction
HDFS or Hadoop Distributed File System provides a scalable and fault tolerant enabled data storage. HIVE provides a simple SQL like query language – HIVE QL. HIVE QL allows the traditional map reduce developers to plug-in their custom mappers and reducers to do more sophisticated analysis.
Limitation of HIVE
Latency for HIVE queries is usually very high because of the substantial overheads in job submission and scheduling. Hive does not offer real time queries and row level updates. It is best used for log analysis.
HIVE Data Units
Hive data is organized into following four categories:
- Databases: This consists of the namespaces which separates the tables and other data units to avoid name conflicts.
- Tables: These are homogeneous units of data having a common schema. A commonly used example could be of a page view table where each row can have the following columns :
- USERID
- IPADDRESS
- LAST ACCESSED
- PAGE URL
This example lists the record of the usage of a website or an application for individual users.
- Partitions: Partitions determine how the data is stored. Each table can have one or multiple partitions. Partitions also help users to efficiently identify the rows which satisfy a certain selection criteria.
- Buckets or Clusters: Data in each partition may be further subdivided into buckets or clusters or blocks. The data in the above example can be clustered based on the user id or on the ip address or on the page url column.
HIVE Data Types
Based on the need, HIVE supports primitive and complex data types as described below:
- Primitive types:
- INTEGERS
- TINY INT 1 byte integer
- SMALL INT 2 byte integer
- INT 4 byte integer
- BIGINT 8 byte integer
- BOOLEAN
- BOOLEAN TRUE or FALSE
- FLOATING POINT numbers
- FLOAT Single precision
- DOUBLE Double precision
- STRING type
- STRING Sequence of characters
- Complex Types: Complex types can be constructed using primitive data types and other composite types with the help of :
- Structs
- Maps or key value pairs
- Arrays – Indexed lists
- INTEGERS
HIVE Scripting
Similar to any other scripting language, HIVE scripts are used to execute a set of HIVE commands collectively. HIVE scripting helps us to reduce the time and effort invested in writing and executing the individual commands manually. HIVE scripting is supported in HIVE 0.10.0 or higher versions of HIVE. To write and execute a HIVE script, we need to install Cloudera distribution for Hadoop CDH4.
Writing HIVE SCRIPTS
First, open a terminal in your Cloudera CDH4 distribution and give the below command to create a Hive Script.
gedit sample.sql
Similar to any other query language, the Hive script file should be saved with .sql extension. This will enable the execution of the commands. Now open the file in Edit mode and write your Hive commands that will be executed using this script. In this sample script, we will do the following tasks sequentially (create, describe and then load the data into the table. And then retrieve the data from table).
Create a table ‘product’ in Hive
create table product_dtl ( product_id: int, product-name: string, product_price: float, product_category: string) rows format delimited fields terminated by ‘,’ ;
Here { product_id, product-name, product_price, product_category} are names of the columns in the ‘product_dtl’ table. “Fields terminated by ‘,’ ” indicates that the columns in the input file are separated by the ‘,’ delimiter. You can also use other delimiters as per your requirement. For example, we can consider the records in an input file separated by a new line (‘\n’) character.
Describe the Table
describe product_dtl;
Load the data into the Table
Now, let’s check the data loading part. Create an input file which contains the records that needs to be inserted into the table.
sudo gedit input.txt
Now let’s create few records in the input text file as shown in the figure below:
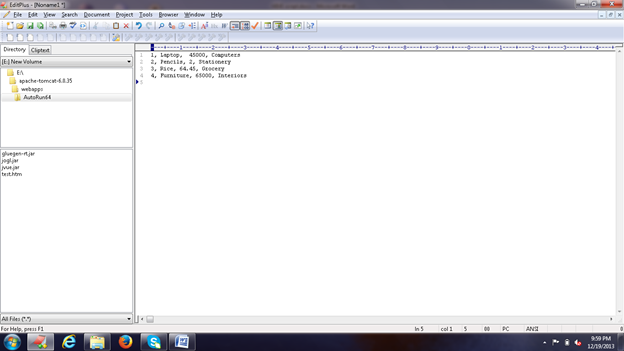
So, our input file will look like:
1, Laptop, 45000, Computers 2, Pencils, 2, Stationery 3, Rice, 64.45, Grocery 4, Furniture, 65000, Interiors
To load the data from this file we need to execute the following command:
load data local inpath ‘/home/cloudera/input.txt’ into table product_dtl;
Retrieving the Data: To retrieve the data we use the simple select statement as under:
select * from product_dtl;
The above command will execute and fetch all the records from the table ‘product’.
The script will look like the following image:
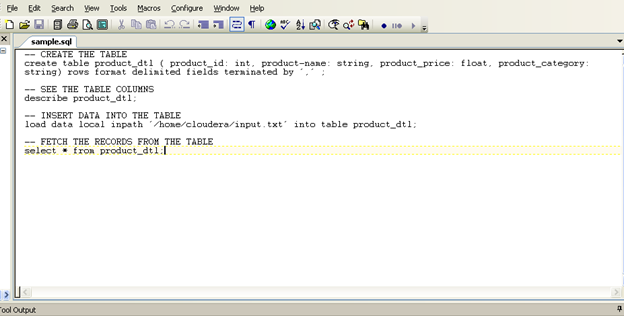
Save this sample.sql file and run the following command:
hive –f /home/cloudera/sample.sql
While executing the script, mention the entire path of the script location. Here the sample script is present in the current directory; I haven’t provided the complete path of the script.
The following image displays that all the commands were executed successfully.
The following output shows that the table is created and the data from our sample input file is stored in the database.
| 1 | Laptop | 45000 | Computers |
| 2 | Pencils | 2 | Stationery |
| 3 | Rice | 64.45 | Groceries |
| 4 | Furniture | 65000 |
Summary
Before concluding our discussion, we must keep a note of the following points
- Apache HIVE is an integral part of HDFS
- HIVE is an SQL like query language
- HIVE script is easy to understand and implement
- Hive supports both primitive data types and complex data types.
| Reference: | How to create your first HIVE script? from our JCG partner Kaushik Pal at the TechAlpine – The Technology world blog. |
