Introduction
Over the years, Grid Dynamics has had many projects related to NoSQL, particularly Apache Cassandra. In this post, we want to discuss a project which brought exciting challenges to us, and questions we tried to answer in that project remain relevant today, as well.
Digital marketing and online ads were popular in 2012, and a demand for them has only increased. Real-time bidding (RTB) is an integral part of the domain area. RTB supposes that an ad is placed (bought and sold) via real-time auction of digital ads. If the bid is won, the buyer’s ad is instantly displayed on the publisher’s site. RTB requires a low-latency response from server side (<100ms), otherwise the bid is lost. One of our clients, a US media company, was interested in real-time bidding and user tracking (i.e. the analysis of website visitors’ behavior and their preferences).
Initially, the client’s infrastructure for processing RTB requests included installations of Kyoto Cabinet. On the image below (Picture 1), you can see a source for RTB and third-party requests. All the requests were sent to real-time applications which performed lookup and update requests in the database. Kyoto Cabinet kept the whole dataset in memory, and custom add-ons provided functionality for retention management and persistence.
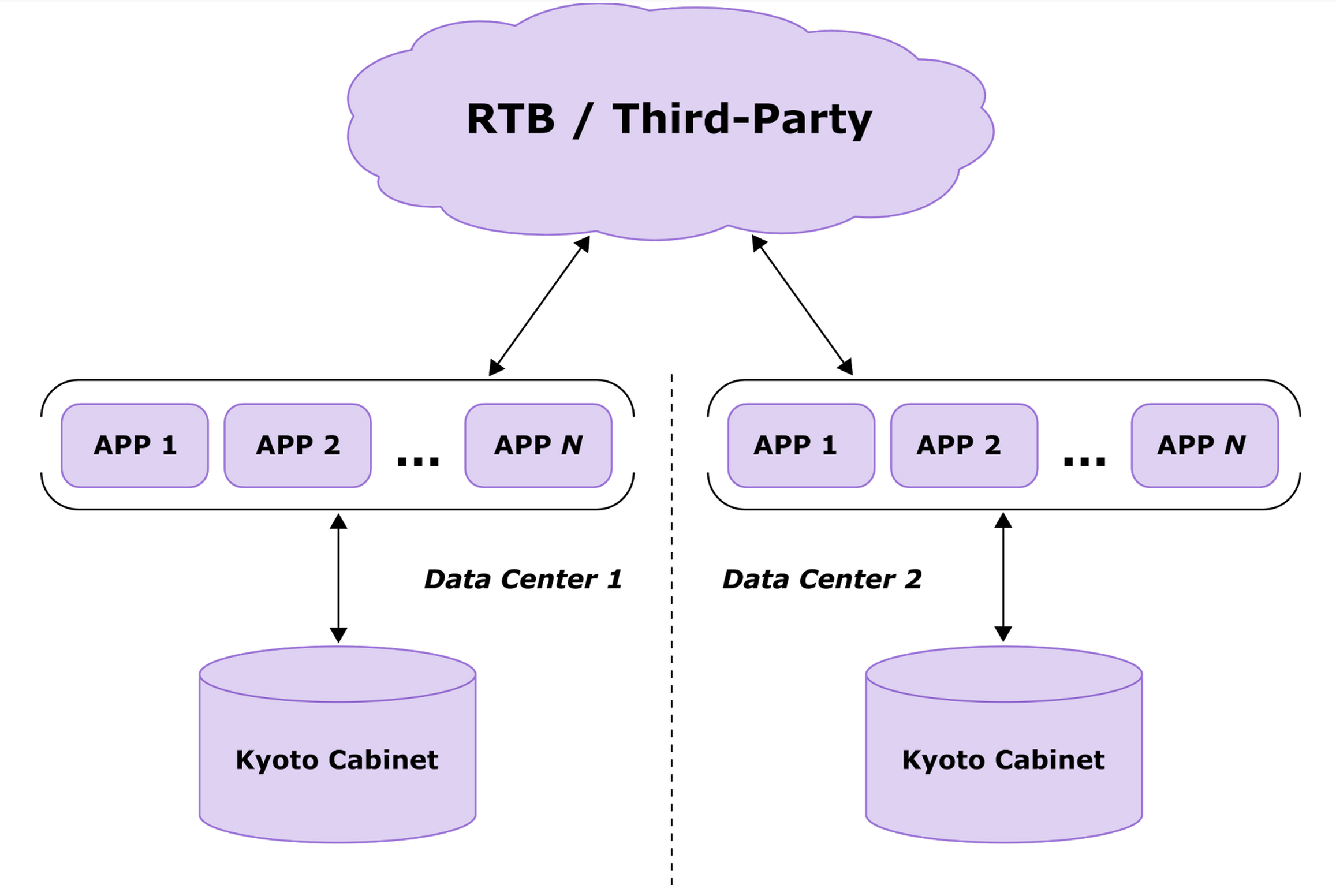
The aforesaid architecture was good enough from latency perspective, but nevertheless, it had several disadvantages:
- Scalability. The architecture supposed only vertical scaling of servers with installations of Kyoto Cabinet. At that time, the servers were equipped with about 50GB memory each. It was clear to everybody that increasing memory amount would solve the problem long term.
- Robustness. The only installation of Kyoto Cabinet might cause very serious consequences in case of a failure.
- Cross-datacenter replication. The architecture did not have automatic synchronization between data centers. Manual synchronization was a real headache because it required a lot of additional operations.
Our task was to create a new architecture for the system which would not have the aforesaid drawbacks and, at the same time, would allow us to achieve good results in response latency. In other words, we were in need of a data store which would allow us to keep user profiles as well as to perform lookups and updates on them, and all the operations were to be performed within a certain time interval. The architecture was supposed to be built around such a data store.
Requirements
The new architecture was intended to solve all these problems. The requirements for the new architecture were as follows:
- persistency (no data should be lost in case of power outage in one or both data centers)
- high availability (there should be no single point of failure)
- scalability (database volume should be relatively easy to increase by adding more nodes)
- cross-datacenter replication (data should be synchronized between both data centers)
- TTL for data (outdated user profiles should be automatically evicted)
- data volume (about 1 billion homogeneous records with multiple attributes, where one record is ~400 bytes)
- throughput (5000 random reads + 5000 random writes per second for each data center)
- latency of responses (3ms on average, processing time should not exceed 10 ms for 99% of requests)
Also we had some limitations which were related to the infrastructure. One of the limitations was the ability to install a maximum of eight servers per database in each datacenter. At the same time we could select certain server hardware, such as memory amount, storage type, and size. One of the additional requirements from the client was to use replication factor TWO which was acceptable due to the statistical nature of data. This could reduce the hardware cost.
We examined several possible solutions that could meet our requirements and finally opted for Cassandra. The new architecture with Cassandra became a much more elegant solution. It was just a Cassandra cluster synchronized between two data centers. But a question about its hardware specifications still remained unanswered. Initially we had two options:
- SDDs but less memory (less than the entire dataset)
- HDDs and more memory (sufficient for keeping the whole dataset)
Actually, there was one more option which implied using hard drives and less memory, but this configuration did not provide the read latency acceptable for our requirements as random read from an HDD takes about 8ms even for 10K RPM hard drives. As a result, it was rejected from the very beginning.
Thus, we had two configurations. After some tuning (the tuning itself will be discussed in the next section) they both satisfied our needs. Each of them had its own advantages and disadvantages. One of the main drawbacks of the SSD configuration was its cost. Enterprise-level SDDs were rather expensive at that time. Besides, some data center providers surcharged for maintaining servers with SSDs.
The approach with HDDs meant reading data from disk cache. Most disadvantages of the configuration were related to the cache, for example, the problem of cold start. It was caused by the fact that the cache was cleaned after system reboot. As a result, reading uncached data from HDD brought about additional timeouts. The timeouts, in fact, were requests which got no response within 10ms. Besides, disk cache could be accidentally cleaned as a result of copying a large amount of data from a Cassandra server while it was up. The last issue was related to the memory size rather than to the cache. Increasing data amount for a single node was quite difficult. It was possible to add an additional HDD or several HDDs, but memory size for a single machine was limited and not very large.
Finally, we managed to resolve most of the aforesaid issues of the HDD configuration. The cold start problem was resolved by reading data with cat utility and redirecting its output to /dev/null on startup. The issue related to disk cache cleaning went away after patching rsync which was used for creating backups. But the problem with memory limitations remained and caused some troubles later.
In the end, the client selected the HDD + RAM configuration. Each node was equipped with 96GB memory and 8 HDDs in RAID 5+0.
Tuning Cassandra
A version of Cassandra we started with was 1.1.4. Further on, in the process of development we tried out different versions. Finally, we decided upon version 1.2.2 which was approved for production because it contained changes we had committed to Cassandra repository. For example, we added an improvement which allowed us to specify the populate_io_cache_on_flush option (which populates the disk cache on memtable flush and compaction) individually for each column family.
We had to test both remaining configurations to select a more preferable one. For our tests we used a Cassandra cluster that included 3 nodes with 64GB memory and 8 cores each. We started the testing with write operations. During the test, we wrote data into Cassandra at the speed of 7000 writes per second. The speed was selected in proportion to the cluster size and the required throughput (doubled for writes in order to take into account cross-datacenter replication overhead). This methodology was applied to all tests. It is worth mentioning that we used the following preferences:
- replication_factor=2
- write_consistency_level=TWO
- LeveledCompactionStrategy
LeveledCompactionStrategy (LCS) was used because the client’s workflow was supposed to have a lot of update operations. Another reason for using LCS was the decreasing overall dataset size and read latency. Test results were the same for the both configurations:
- Avg Latency: ~1ms
- Timeouts: 0.01%
- CPU usage: <5%
Both configurations satisfied our needs, though we did not spend time investigating timeouts nature at this stage. Timeouts will be discussed later. Presumably, most of the response time was taken by the network transfer. Also, we tried to increase the number of write queries per second and it yielded good results. There were no noticeable performance degradation.
After that we moved to the next step, i.e. testing read operations. We used the same cluster. All read requests were sent with read_consistency_level=ONE. The write speed was set to 3500 queries per second. There were about 40GB of data on each server with the single record size of about 400 bytes. Thus, the whole dataset fit the memory size. Test results were as follows:
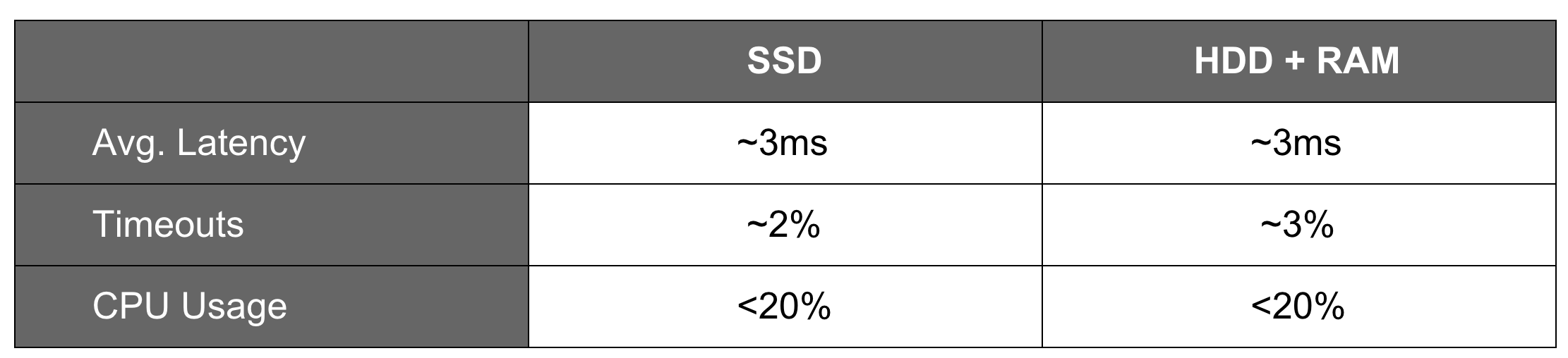
Looking at test results for both configurations, we found unsatisfactory percentage values of timeouts which were 2-3 times the required value (2-3% against 1%). Also, we were anxious about the high CPU load (about 20%). At this point, we came to a conclusion that there was something wrong with our configurations.
It was not a trivial task to find the root of the problem related to timeouts. Eventually, we modified the source code of Cassandra and made it return a single fixed value for all read requests (skipping any lookups from SSTables, memtables, etc.). After that, the same test on read operations was executed again. The result was perfect: GC activity and CPU usage were significantly reduced and there were almost no timeouts detected. We reverted our changes and tried to find an optimal configuration for GC. Having experimented with its options, we settled upon the following configuration:
- -XX:+UseParallelGC
- -XX:+UseParallelOldGC
- -XX:MaxTenuringThreshold=3
- -Xmn1500M
- -Xmx3500M
- -Xms3500M
We managed to reduce the influence of GC to performance of Cassandra. It is worth noting that the number of timeouts on read operations exceeded that on write operations because Cassandra created a lot of objects in heap in the course of reading, which in its turn caused intensive CPU usage. As for the latency, it was low enough and could be largely attributed to the time for data transfer. Executing the same test with more intensive reads showed that in contrast to write operations increasing the number of read operations significantly affected the number of timeouts. Presumably, this fact is related to the growing activity of GC.
It is a well-known fact that GC should be configured individually for each case. In this case, Concurrent Mark Sweep (CMS) was less effective than Parallel Old GC. It was also helpful to decrease the heap size to a relatively small value. The configuration described above is one that suited our needs, though it might have been not the best one. Also, we tried different versions of Java. Java 1.7 gave us some performance improvement against Java 1.6. The relative number of timeouts decreased. Another thing we tried was enabling/disabling row/key caching in Cassandra. Disabling caches slightly decreased GC activity.
The next option that produced surprising results was the number of threads in pools which processed read/write requests in Cassandra. Increasing this value from 32 to 128 made a significant difference in performance as our benchmark emulated multiple clients (up to 500 threads). Also, we tried out different versions of CentOS and various configurations of SELinux. After switching to a later 6.3 version, we found that Java futures returned control by timeout in a shorter period of time. Changes in configuration of SELinux made no effect on performance.
As soon as read performance issues were resolved, we performed tests in the mixed mode (reads + writes). Here we observed a situation which is described in the chart below (Picture 2). After each flush to SSTable Cassandra started to read data from disks, which in its turn caused increased timeouts on the client side. This problem was relevant for the HDD+RAM configuration because reading from SSD did not result in additional timeouts.
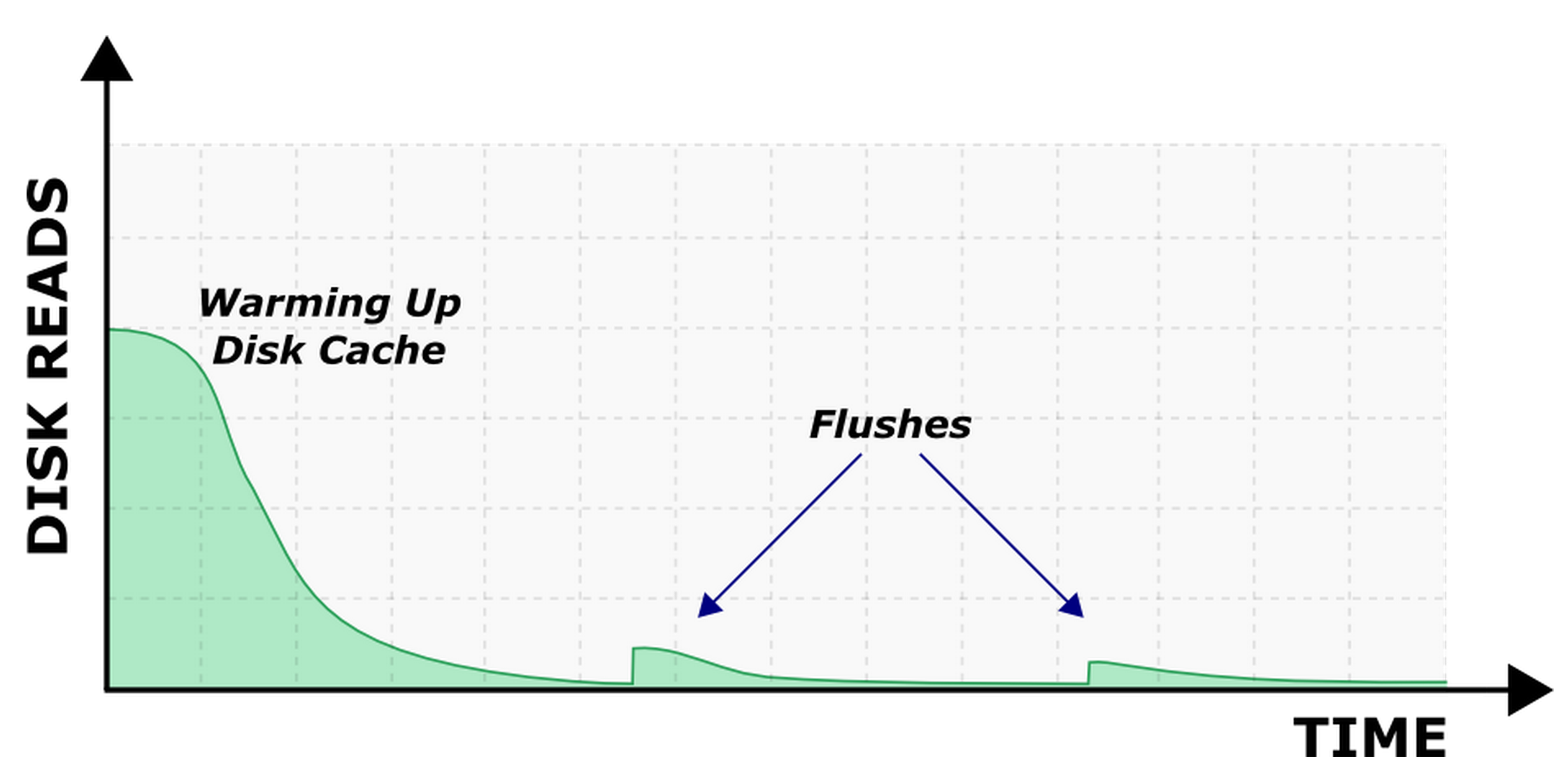
We tried to tinker around with Cassandra configuration options, namely, populate_io_cache_on_flush (which is described above). This option was turned off by default, meaning that filesystem cache was not populated with new SSTables. Therefore when the data from a new SSTable was accessed, it was read from HDD. Setting its value to true fixed the issue. The chart below (Picture 3) displays disk reads after the improvement.
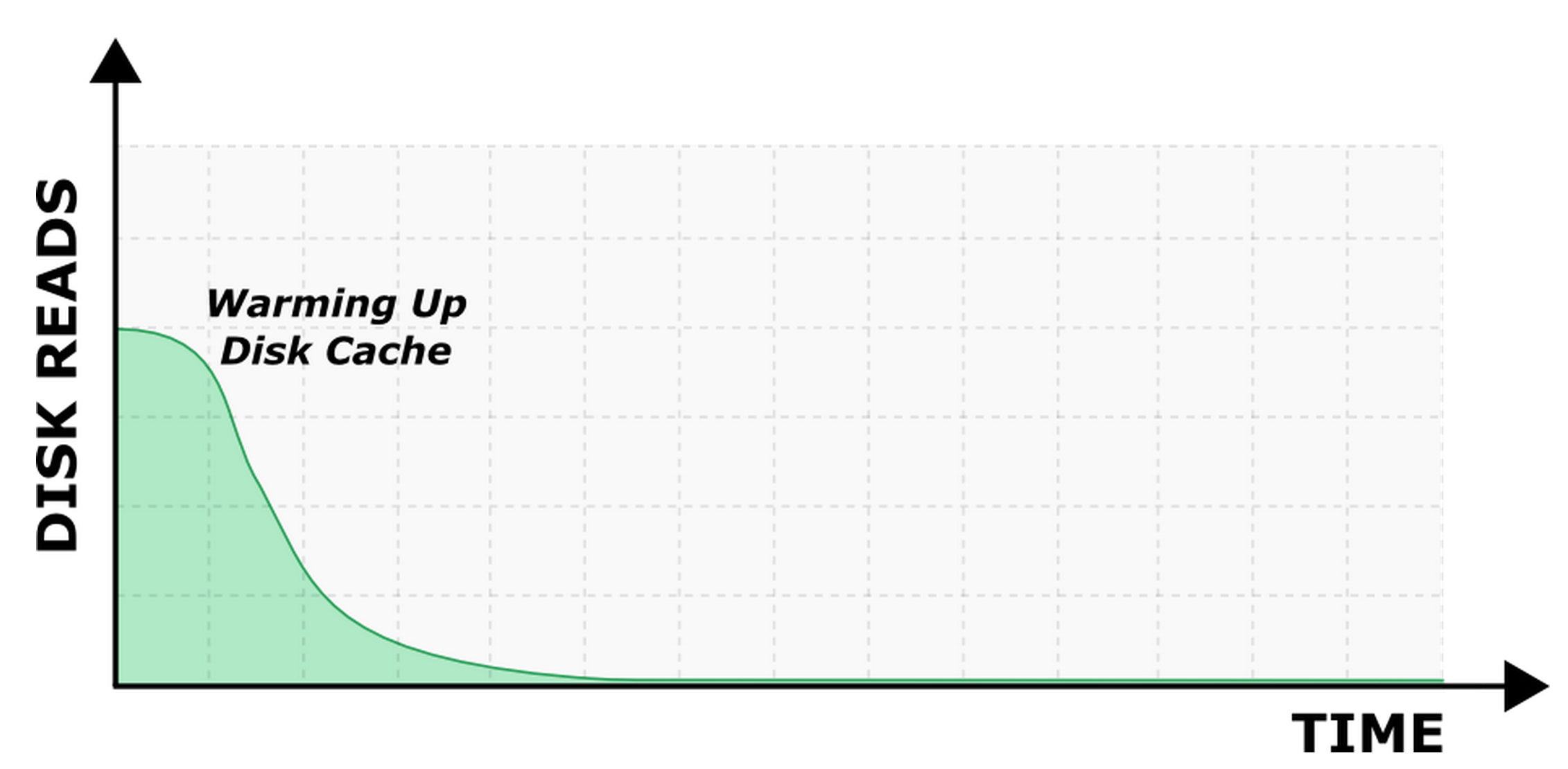
In other words, Cassandra stopped reading from disks after the whole dataset was cached in memory even in the mixed mode. It’s noteworthy that populate_io_cache_on_flush option is turned on by default in Cassandra starting from version 2.1, though it was excluded from the configuration file. The summary below (Table 2) describes the changes we tried and their impact.

Finally, after applying the changes described in this post, we achieved acceptable results for both SSD and HDD+RAM configurations. Much effort was also put into tuning a Cassandra client (we used Astyanax) to operate well with replication factor two and reliably return control on time in case of a timeout. We would also like to share some details about operations automation, monitoring, as well as ensuring proper work of the cross data center replication, but it is very difficult to cover all the aspects in a single post. As stated above, we had gone to production with HDD+RAM configuration and it worked reliably with no surprises, including Cassandra upgrade on the live cluster without downtime.
Conclusion
Cassandra was new to us when it was introduced into the project. We had to spend a lot of time exploring its features and configuration options. It allowed us to implement the required architecture and deliver the system on time. And at the same time we gained a great experience. We carried out significant work integrating Cassandra into our workflow. All our changes in Cassandra source code were contributed back to the community. Our digital marketing client benefited by having a more stable and scalable infrastructure with automated synchronization reducing the amount of time they had to maintain the systems.
About Grid Dynamics
Grid Dynamics is a leading provider of open, scalable, next-generation commerce technology solutions for Tier 1 retail. Grid Dynamics has in-depth expertise in commerce technologies and wide involvement in the open source community. Great companies, partnered with Grid Dynamics, gain a sustainable business advantage by implementing and managing solutions in the areas of omnichannel platforms, product search and personalization, and continuous delivery. To learn more about Grid Dynamics, find us at www.griddynamics.com or by following us on Twitter @GridDynamics.
| Reference: | Apache Cassandra and Low-Latency Applications from our JCG partner Dmitry Yaraev at the Planet Cassandra blog. |
