Introduction
At the beginning applications were simple and small due to simple requirements. With time requirements and needs grew and with them our applications became bigger and more complex. That resulted in monolithic servers developed and deployed as a single unit. Microservices are, in a way, return to basics with simple applications that are fulfilling today’s needs for complexity by working together through utilization of each others APIs.
What are monolithic servers?
 Microservices are best explained when compared with their opposite; monolithic servers. They are developed and deployed as a single unit. In case of Java, the end result is often a single WAR or JAR file. Same is true for C++, .Net, Scala and many other programming languages.
Microservices are best explained when compared with their opposite; monolithic servers. They are developed and deployed as a single unit. In case of Java, the end result is often a single WAR or JAR file. Same is true for C++, .Net, Scala and many other programming languages.
Most of the short history of software development is marked by continuous increment in sizes of applications we develop. As time passes we’re adding more and more to our applications continuously increasing their complexity and size and decreasing our development, testing and deployment speed.
With time we started dividing our applications into layers: presentation layer, business layer, data access layer, etc. This separation is more logical than physical. While development got a bit easier we still needed to test and deploy everything every time there was a change or a release. It is not uncommon in enterprise environments to have applications that take hours to build and deploy. Testing, especially regression, tends to be a nightmare that in some cases lasts for months. As time passes, our ability to make changes that affect only one module is decreasing. The main objective of layers is to make them in a way that they can be easily replaced or upgraded. That promise was never really fulfilled. Replacing something in big monolithic applications is almost never easy and without risks.
Scaling such servers means scaling the entire application producing very unbalanced utilization of resources. If we need more resources we are forced to duplicate everything on a new server even if a bottleneck is one module.
What are microservices?
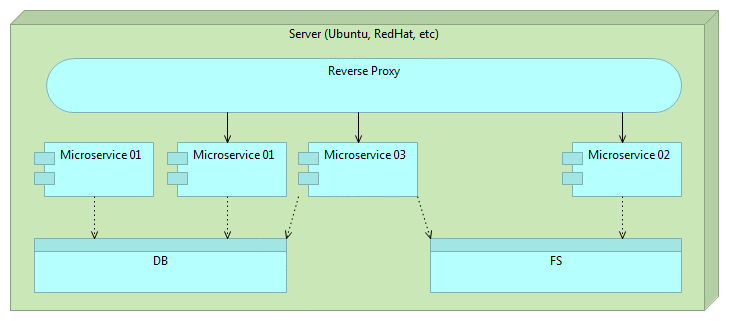
Microservices are an approach to architecture and development of a single application composed of small services. The key to understanding microservices is their independence. Each is developed, tested and deployed separately from each other. Each service runs as a separate process. The only relation between different microservices is data exchange accomplished through APIs they’re exposing. They inherit, in a way, the idea of small programs and pipes used in Unix/Linux. Most Linux programs are small and produce some output. That output can be passed as input to other programs. When chained, those programs can perform very complex operations. It is complexity born from combination of many simple units.
Key aspects of microservices are:
- They do one thing or are responsible for one functionality.
- Each microservice can be built by any set of tools or languages since each is independent from others.
- They are truly loosely coupled since each microservice is physically separated from others.
- Relative independence between different teams developing different microservices (assuming that APIs they expose are defined in advance).
- Easier testing and continuous delivery or deployment
One of the problems with microservices is the decision when to use them. At the beginning, while application is still small, problems that microservices are trying to solve do not exist. However, once the application grows and the case for microservices can be made, the cost of switching to a different architecture style might be too big. Experienced teams might use microservices from the very start knowing that technical debt they might have to pay later will be more expensive than working with microservices from the very beginning. Often, as it was the case with Netflix, eBay and Amazon, monolithic applications start evolving towards microservices gradually. New modules are developed as microservices and integrated with the rest of the system. Once they prove their worth, parts of the existing monolithic application get refactored into microservices.
One of the things that often gets most critique from developers of enterprise applications is decentralization of data storage. While microservices can work (with few adjustments) using centralized data storage, option to decentralize that part as well should, at least, be explored. The option to store data related to some service in a separate (decentralized) storage and pack it all together in the same container is something that in many cases could be a better option than storing that data in a centralized database. We’re not proposing to always use decentralized storage but to have that option in account when designing microservices.
Disadvantages
Increased operational and deployment complexity
Major argument against microservices is increased operational and deployment complexity. This argument is true but thanks to relatively new tools it can be mitigated. Configuration Management (CM) tools can handle environment setups and deployments with relative ease. Utilization of containers with Docker greatly reduces deployment pains that microservices can cause. CM tools together with Docker allow us to deploy and scale microservices easily. An example can be found in the article Continuous Deployment: Implementation with Ansible and Docker.
In my opinion, increased deployment complexity argument usually does not take in account advances we saw during last years and is greatly exaggerated. That does not mean that part of the work is not shifted from development to DevOps. It definitely is. However, benefits are in many cases bigger than inconvenience that shift produces.
Remote process calls
Another counter argument is reduced performance produced by remote process calls. Internal calls through classes and methods are faster and this problem cannot be removed. How much that loss of performance affects a system depends from case to case. Important factor is how we split our system. If we take it towards the extreme with very small microservices (some propose that they should not have more than 10-100 LOC) this impact might be considerable. I like to create microservices organized around functionality like users, shopping cart, products, etc. This reduces the amount of remote process calls. Also, it’s important to note that if calls from one microservice to another are going through fast internal LAN, negative impact is relatively small.
Advantages
Following are only few advantages that microservices can bring. That does not mean that the same advantages do not exist in other types of architecture but that with microservices they might be a bit more prominent that with some other options.
Scaling
Scaling microservices is much easier than monolithic applications. While in the later case we duplicate the whole application to a new machine, with microservices we duplicate only those that need scaling. Not only that we can scale what needs to be scaled but we can distribute things better. We can, for example, put a service that has heavy utilization of CPU together with another one that uses a lot of RAM while moving a second CPU demanding service to a different hardware.
Innovation
Monolithic servers, once initial architecture is made, do not leave much space for innovation. Due to their nature, changing things takes time and experimentation is very risky since it potentially affects everything. One cannot, for example, change Apache Tomcat for NodeJS just because it would better suit one particular module.
I’m not suggesting that we should change programming language, server, persistence, etc for each module. However, monolithic servers tend to go to an opposite extreme where changes are risky if not unwelcome. With microservices we can choose what we think is the best solution for each service separately. One might use Apache Tomcat while the other would use NodeJS. One can be written in Java and the other in Scala. I’m not advocating that each service is different from the rest but that each can be made in a way that we think is best suited for the goal at hand. On top of that, changes and experiments are much easier to do. After all, whatever we do affects only one out of many microservices and not the system as a whole as long as the API is respected.
Size
Since microservices are small they are much easier to understand. There is much less code to go through in order to see what one microservice is doing. That in itself greatly simplifies development especially when newcomers join the project. On top of that, everything else tends to be much faster. IDEs work faster with a small project when compared to big ones used in monolithic applications. They start faster since there are no huge servers or a huge number of libraries to load.
Deployment, rollback and fault isolation
Deployment is much faster and easier. Deploying something small is always faster (if not easier) than deploying something big. In case we realized that there is a problem, that problem has potentially limited affect and can be rolled back much easier. Until we rollback, fault is isolated to a small part of the system. Continuous Delivery or Deployment can be done with speed and frequencies that would not be possible with big servers.
No need for long term commitment
One of the common problems with monolithic applications is commitment. We are often forced to choose from the start architecture and technologies that will last for a long time. After all, we’re building something big that should last for a long time. With microservices that need for a long-term commitment is not so big. Change the programming language in one microservice and if it turns out to be a good choice, apply it to others. If the experiment failed or is not optimum, there’s only one small part of the system that needs to be redone. Same applies to frameworks, libraries, servers, etc. We can even use different databases. If some lightweight NoSQL seems like the best fit for a particular microservice, why not use it and pack it inside the container?
Best practices
Most of the following best practices can be applied to services oriented architecture in general. However, with microservices they become even more important or beneficial.
Containers
Dealing with many microservices can easily become a very complex endeavor. Each can be written in a different programming language, can require a different (hopefully light) server or can use a different set of libraries. If each service is packed as a container most of those problems will go away. All we have to do is run the container with, for example, Docker and trust that everything needed is inside it.
Proxy microservices or API gateway
Big enterprise front-ends might need to invoke tens or even hundreds of HTTP requests (as is the case with Amazon.com). Requests often take more time to be invoked than to receive response data. Proxy microservices might help in that case. Their goal is to invoke different microservices and return an aggregated service. They should not contain any logic but simply group several responses together and respond with aggregated data to the consumer.
Reverse proxy
Never expose microservice API directly. If there isn’t some type of orchestration, dependency between the consumer and microservices becomes so big that it might remove freedom that microservices are supposed to give us. Lightweight servers like nginx and Apache Tomcat are very good at performing reverse proxy tasks and can easily be employed with very little overhead. Please consult Continuous Deployment: Implementation article for one possible way to use reverse proxy with Docker and few other tools.
Minimalist approach
Microservices should contain only packages, libraries and frameworks that they really need. The smaller they are, the better. This is quite in contrast with the approach used with monolithic applications. While previously we might have used JEE servers like JBoss that packed all the tools that we might or might not need, microservices work best with much more minimalistic solutions. Having hundreds of microservices with each of them having a full JBoss server becomes overkill. Apache Tomcat, for example, is a much better option. I tend to go for even smaller solutions with, for example, Spray as a very lightweight RESTful API server. Don’t pack what you don’t need.
Same approach should be applied to OS level as well. If we’re deploying microservices as Docker containers, CoreOS might be a better solution than, for example, Red Hat or Ubuntu. It’s free from things we do not need allowing us to better utilize resources.
Configuration management is a must
As the number of microservices grows, the need for Configuration Management (CM) increases. Deploying many microservices without tools like Puppet, Chef or Ansible (just to name few) quickly becomes a nightmare. Actually, not using CM tools for any but simplest solutions is a waste with or without microservices.
Cross functional teams
While there is no rule that dictates what kinds of teams are utilized, microservices are done best when the team working on one is multifunctional. A single team should be responsible for it from the start (design) until the finish (deployment and maintenance). They are too small to be handled from one team to another (architecture/design, development, testing, deployment and maintenance teams). Preference is to have a team that is in charge of the full lifecycle of a microservice. In many cases one team might be in charge of multiple microservices but multiple teams should not be in charge of one.
API versioning
Versioning should be applied to any API and this holds true for microservices as well. If some change will brake the API format, that change should be released as a separate version. In case of public APIs or microservices, we cannot be sure who is using them and, therefore, must maintain backward compatibility or, at least, give consumers enough time to adapt. There is a section on API versioning published in the REST API with JSON article.
Summary
Microservices are not an answer to all our problems. Nothing is. They are not the way all applications should be created. There is no single solution that fits all cases.
Microservices exist for a long time and recent years are seeing increase in their popularity. There are many factors that lead to this trend with scalability being probably the most important one. Emergence of new tools, especially Docker, are allowing us to see microservices in a new light and remove part of the problems their development and deployment was creating. Utilization of microservices by “big guys” like Amazon, NetFlix, eBay, and others, provides enough confidence that this architectural style is ready to be evaluated (if not used) by developers of enterprise applications.
| Reference: | Monolithic Servers vs Microservices from our JCG partner Viktor Farcic at the Technology conversations blog. |
