Introduction
In my previous post I described how application-level transactions offer a suitable concurrency control mechanism for long conversations.
All entities are loaded within the context of a Hibernate Session, acting as a transactional write-behind cache.
A Hibernate persistence context can hold one and only one reference of a given entity. The first level cache guarantees session-level repeatable reads.
If the conversation spans over multiple requests we can have application-level repeatable reads. Long conversations are inherently stateful so we can opt for detached objects or long persistence contexts. But application-level repeatable reads require an application-level concurrency control strategy such as optimistic locking.
The catch
But this behavior may prove unexpected at times.
If your Hibernate Session has already loaded a given entity then any successive entity query (JPQL/HQL) is going to return the very same object reference (disregarding the current loaded database snapshot):
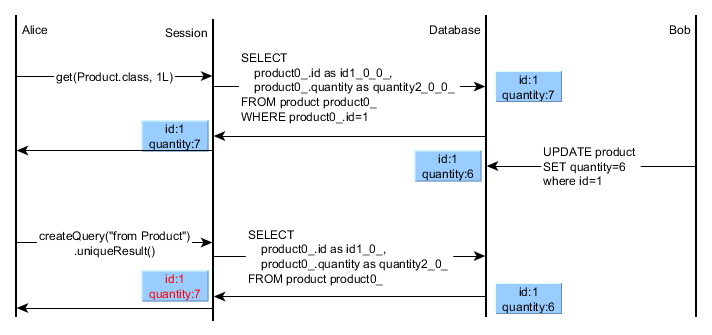
In this example we can see that the first level cache prevents overwriting an already loaded entity. To prove this behavior, I came up with the following test case:
final ExecutorService executorService = Executors.newSingleThreadExecutor();
doInTransaction(new TransactionCallable<Void>() {
@Override
public Void execute(Session session) {
Product product = new Product();
product.setId(1L);
product.setQuantity(7L);
session.persist(product);
return null;
}
});
doInTransaction(new TransactionCallable<Void>() {
@Override
public Void execute(Session session) {
final Product product = (Product) session.get(Product.class, 1L);
try {
executorService.submit(new Callable<Void>() {
@Override
public Void call() throws Exception {
return doInTransaction(new TransactionCallable<Void>() {
@Override
public Void execute(Session _session) {
Product otherThreadProduct = (Product) _session.get(Product.class, 1L);
assertNotSame(product, otherThreadProduct);
otherThreadProduct.setQuantity(6L);
return null;
}
});
}
}).get();
Product reloadedProduct = (Product) session.createQuery("from Product").uniqueResult();
assertEquals(7L, reloadedProduct.getQuantity());
assertEquals(6L, ((Number) session.createSQLQuery("select quantity from Product where id = :id").setParameter("id", product.getId()).uniqueResult()).longValue());
} catch (Exception e) {
fail(e.getMessage());
}
return null;
}
});This test case clearly illustrates the differences between entity queries and SQL projections. While SQL query projections always load the latest database state, entity query results are managed by the first level cache, ensuring session-level repeatable reads.
Workaround 1: If your use case demands reloading the latest database entity state then you can simply refresh the entity in question.
Workaround 2: If you want an entity to be disassociated from the Hibernate first level cache you can easily evict it, so the next entity query can use the latest database entity value.
Beyond prejudice
Hibernate is a means, not a goal. A data access layer requires both reads and writes and neither plain-old JDBC nor Hibernate are one-size-fits-all solutions. A data knowledge stack is much more appropriate for getting the most of your data read queries and write DML statements.
While native SQL remains the de facto relational data reading technique, Hibernate excels in writing data. Hibernate is a persistence framework and you should never forget that. Loading entities makes sense if you plan on propagating changes back to the database. You don’t need to load entities for displaying read-only views, an SQL projection being a much better alternative in this case.
Session-level repeatable reads prevent lost updates in concurrent writes scenarios, so there’s a good reason why entities don’t get refreshed automatically. Maybe we’ve chosen to manually flush dirty properties and an automated entity refresh might overwrite synchronized pending changes.
Designing the data access patterns is not a trivial task to do and a solid integration testing foundation is worth investing in. To avoid any unknown behaviors, I strongly advise you to validate all automatically generated SQL statements to prove their effectiveness and efficiency.
- Code available on GitHub.
| Reference: | Hibernate application-level repeatable reads from our JCG partner Vlad Mihalcea at the Vlad Mihalcea’s Blog blog. |

What DB are you using and what’s the serialization level of the transaction? From what I can see you should be starting a transaction with the initial read, then in another transaction you update the value and commit. For the next hibernate and SQL read you should see the same value unless the serialization has been lowers to Read Committed from Repeatable Read.