Concurrency is not for the faint-hearted
We all know concurrency programming is difficult to get it right. That’s why threading tasks are followed by extensive design and code reviewing sessions.
You never assign concurrent issues to inexperienced developers. The problem space is carefully analysed, a design emerges and the solution is both documented and reviewed.
That’s how threading related tasks are usually addressed. You will naturally choose a higher level abstraction, since you don’t want to get tangled up in low level details. That’s why the java.util.concurrent is usually better (unless you build a High Frequency Trading system) than hand-made producer/consumer Java 1.2 style thread-safe structures.
Is database programming any different?
In a database system the data is spread across various structures (SQL tables or NoSQL collections) and multiple users may select/insert/update/delete whatever they choose to. From a concurrency point of view this is a very challenging task and it’s not just the database system developer’s problem. It’s our problem as well.
A typical RDBMS data layer requires you to master various technologies and your solution is only as strong as your team’s weakest spot.
A recipe for success
When it comes to database programming you shouldn’t ever remain untrained. Constantly learning is your best weapon, there’s no other way.
For this I came up with my own data knowledge stack:
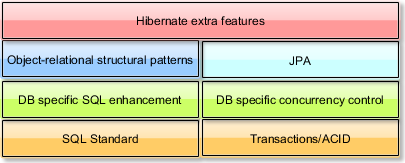
You should always master the bottom layers prior to advancing to upper ones.
So these are the golden rules for taming the data layer:
- The database manual was not only meant for Database AdministratorsIf you are doing any database related task than reading your current database manual is not optional. You should be familiar with both the SQL standard and your database specific traits. Break free from the SQL-92 mindset. Don’t let the portability fear make you reject highly effective database specific features. It’s more common to end-up with a sluggish database layer than to port an already running system to a new database solution.
- Fully read “Patterns of Enterprise Application Architecture“I’ll give you a great investment tip. You are 50$ away from understanding the core concepts of any available ORM tool. Martin Fowler‘s book is a must for any enterprise developer. The on-line pattern catalogue is a great teaser.
- Read your ORM documentationSome argue that their ORM tool is the root of all evil. Unless you spend your time and read all the available documentation, you are going to have a very hard time taming your ORM data layer. The object to relational mismatch has always been a really complex problem, yet it simplifies the CREATE/UPDATE/DELETE operations of complex object tree structures. The ORM’s optimistic locking feature is a great way of dealing with the “lost update” problem.
- Pick and mixJPA/Hibernate are not a substitute for SQL. You should get the best of JPA and SQL and combine them into one winning solution. Because SQL is unavoidable on any non-trivial application, it’s wise to invest some time (and maybe a license) for using a powerful querying framework. If you fear that database portability is holding you back from using proprietary database querying features than a JPA/JOOQ medley is a recipe for success.
A Hibernate Master class
I’ve been using Hibernate for almost a decade and I admit it wasn’t an easy journey. The StackOverflow Hibernate related questions are pouring on a daily basis.
That’s why I decided to come up with my own Hibernate material that I’ll share on this blog and my GitHub account, because if you are willing to spend your time to learn it you shouldn’t be charged for your effort. For those who want an intensive and personalized Hibernate Master class training, feel free to contact me. We’ll find a way to get you trained.
| Reference: | The data knowledge stack from our JCG partner Vlad Mihalcea at the Vlad Mihalcea’s Blog blog. |
