It’s not NoSQL versus RDBMS, it’s ACID + foreign keys versus eventual consistency
The Background
Coming from a diverse background and having dealt with a number of distributed systems, I routinely find myself in a situation where I need to explain why foreign keys managed by an acid compliant RDBMS (no matter how expensive or awesome), lead to a scaleability problem that can be extremely cost prohibitive to solve. I also want to clarify an important point before I begin, scaleability doesn’t equate to a binary yes or no answer, scaleability should always be expressed as an cost per unit of scale and I’ll illustrate why.
Let’s use a simplified model of a common web architecture.
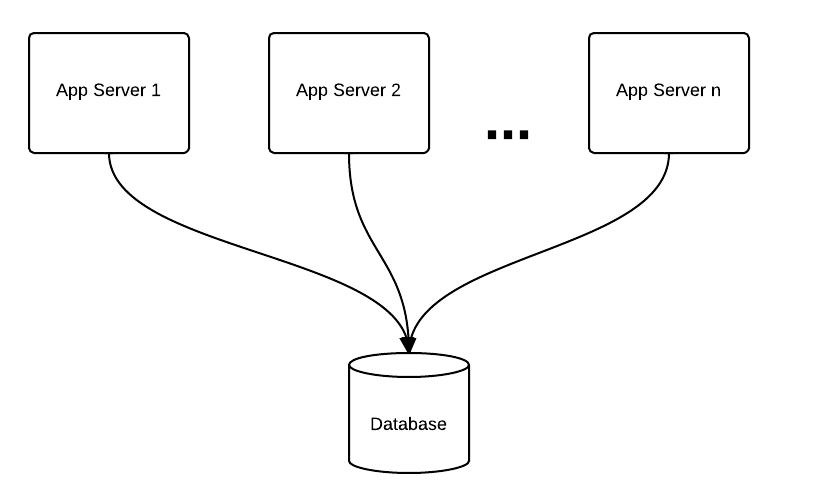
In this model, work is divided between application servers (computation) and database servers (storage). If we assume that a foreign key requires validation at the storage level, no matter how scaleable our application layer is, we’re going to run into a storage scaling problem. Note: Oracle RAC is this model…at the end of the day, no matter how many RAC nodes you add, you’re generally only scaling computation power, not storage.
To circumvent this problem, the logical step is to also distribute the storage. In this case, the model changes slightly and it begins to look something like this.
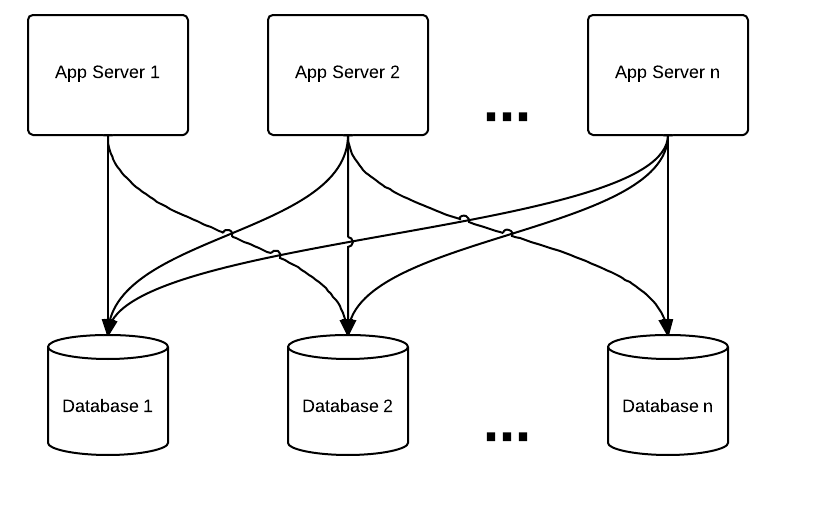
In this model, one used by distributed database solutions, (including high end acid compliant databases such as Oracle RAC or Exadata or IBM purescale), a information storage is distributed among nodes responsible for storage and the nodes don’t share a disk. In the database scaling community, this is a “shared nothing” architecture. To illustrate this a little further, the way most distributed database work in a shared nothing architecture is one of two ways, for each piece of data they either:
- Hash the key and use that hash to lookup the node with the data
- Use master nodes to maintain the node to data association
So, problem solved right? In theory, especially if I’m using a very fast/efficient hashing method, this should scale very well by simply adding more nodes at the appropriate layer.
The Problem
The problem has to do with foreign keys, ACID compliance, and the overhead they incur. Ironically, this overhead actually has a potentially serious negative impact on scaleability. Moreover, our reliance on this model and it’s level abstraction, often blinds us to bottlenecks and leads to mysterious phantom slowdowns and inconsistent performance.
Let’s first recap a couple of things (a more detailed background can be found here for those that care to read further.
- A foreign key is a relation in one table to a key in another table the MUST exist for an update or insert to be successful (it’s a little more complicated than that, but we’ll keep it simple)
- ACID compliance refers to a set of rules about what a transaction means, but in our context, it means that for update A, I must look up information B
Here’s the rub, even with a perfectly partitioned shared nothing architecture, if we need to maintain ACID compliance with foreign keys, we run into a particular problem. If the Key for update A is on one node, and the Key for update B is on a different node… we require a lookup across nodes of the cluster. The only way to avoid this problem… is to drop the foreign key and/or relax your ACID compliance. It’s true that perfect forward knowledge might allow us to design the data storage in such a way that this is not really a problem, but reality is otherwise.
So, at the end of the day, when folks are throwing their hats into the ring about how NoSQL is better than RDBMS, they’re really saying they want to use databases that are either:
- ACID compliant and they’ll eschew foreign keys
- Not ACID compliant
And I think we can see that, from a scaleability perspective, there are very good reasons to do this.
| Reference: | It’s not NoSQL versus RDBMS, it’s ACID + foreign keys versus eventual consistency from our JCG partner Mike Mainguy at the mike.mainguy blog. |

Havent seen this in mysql/pgsql, but it would be nice if we had an option to make foreign keys “soft” – so they are defined but not treated as explicit constraint.
The reason would be so that you can get an SQL dump of the schema without the application code, and still understand what the app actually does.
Obviously, this comment has little to do with scalability or ACID vs NoSQL, but as a developer, i have to think about my own creature comforts, such as easy to understand foreign codebase during my fist week on the job.. : )