Haven’t we all been wondering:
How can I do this? I have these data in Excel and I want to group / sort / assign / combine …
While you could probably pull up a Visual Basic script doing the work or export the data to Java or any other procedural language of choice, why not just use SQL?
The use-case: Counting neighboring colours in a stadium choreography
This might not be an everyday use-case for many of you, but for our office friends at FanPictor, it is. They’re creating software to draw a fan choreography directly into a stadium. Here’s the use-case on a high level:
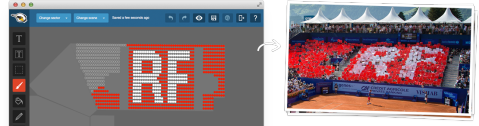
It’s immediately clear what this fun software does, right?
- You submit a choreography suggestion
- The event organisers choose the best submission
- The event organisers export the choreography as an Excel file
- The Excel file is fed into a print shop, printing red/red, red/white, white/red, white/white panels (or any other colours)
- The event helpers distribute the coloured panels on the appropriate seat
- The fans get all excited
Having a look at the Excel spreadsheet
So this is what the Excel spreadsheet looks like:
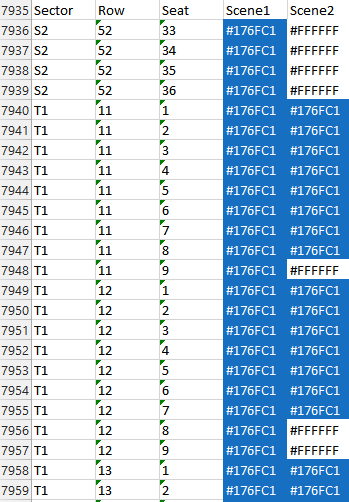
Now, distributing these panels is silly, repetitive work. From experience, our friends at FanPictor wanted to have something along the lines of this, instead:
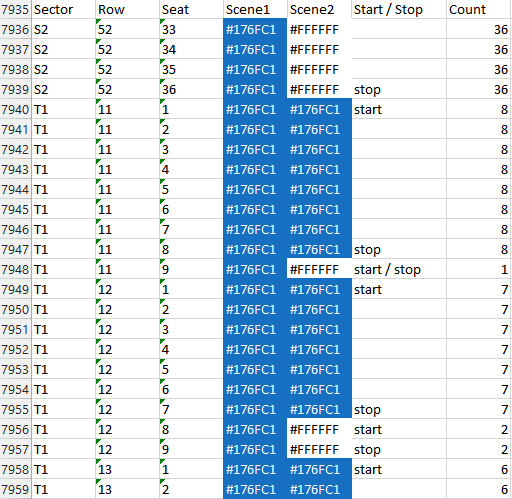
Notice that there are instructions associated with each panel to indicate:
- … whether a consecutive row of identical panels starts or stops
- … how many identical panels there are in such a row
“consecutive” means that within a stadium sector and row, there are adjacent seats with the same (Scene1, Scene2) tuple.
How do we solve this problem?
We solve this problem with SQL of course – and with a decent database, that supports window functions, e.g. PostgreSQL, or any commercial database of your choice! (you won’t be finding this sort of feature in MySQL).
Here’s the query:
with data
as (
select
d.*,
row(sektor, row, scene1, scene2) block
from d
)
select
sektor,
row,
seat,
scene1,
scene2,
case
when lag (block) over(o) is distinct from block
and lead(block) over(o) is distinct from block
then 'start / stop'
when lag (block) over(o) is distinct from block
then 'start'
when lead(block) over(o) is distinct from block
then 'stop'
else ''
end start_stop,
count(*) over(
partition by sektor, row, scene1, scene2
) cnt
from data
window o as (
order by sektor, row, seat
)
order by sektor, row, seat;That’s it! Not too hard, is it?
Let’s go through a couple of details. We’re using quite a few awesome SQL standard / PostgreSQL concepts, which deserve to be explained:
Row value constructor
The ROW() value constructor is a very powerful feature that can be used to combine several columns (or rows) into a single ROW / RECORD type:
row(sektor, row, scene1, scene2) block
This type can then be used for row value comparisons, saving you a lot of time comparing column by column.
The DISTINCT predicate
lag (block) over(o) is distinct from block
The result of the above window function is compared with the previously constructed ROW by using the DISTINCT predicate, which is a great way of comparing things “null-safely” in SQL. Remember that SQL NULLs are some of the hardest things in SQL to get right.
Window functions
Window functions are a very awesome concept. Without any GROUP BY clause, you can calculate aggregate functions, window functions, ranking functions etc. in the context of a current row while you’re projecting the SELECT clause. For instance:
count(*) over( partition by sektor, row, scene1, scene2 ) cnt
The above window function counts all rows that are in the same partition (“group”) as the current row, given the partition criteria. In other words, all the seats that have the same (scene1, scene2) colouring and that are located in the same (sector, row).
The other window functions are lead and lag, which return a value from a previous or subsequent row, given a specific ordering:
lag (block) over(o), lead(block) over(o) -- ... window o as ( order by sektor, row, seat )
Note also the use of the SQL standard WINDOW clause, which is supported only by PostgreSQL and Sybase SQL Anywhere.
In the above snippet, lag() returns the block value of the previous row given the ordering o, whereas lead() would return the next row’s value for block – or NULL, in case of which we’re glad that we used the DISTINCT predicate, before.
Note that you can also optionally supply an additional numeric parameter, to indicate that you want to access the second, third, fifth, or eighth, row backwards or forward.
SQL is your most powerful and underestimated tool
At Data Geekery, we always say that
SQL is a device whose mystery is only exceeded by its power
If you’ve been following our blog, you may have noticed that we try to evangelise SQL as a great first-class citizen for Java developers. Most of the above features are supported by jOOQ, and translated to your native SQL dialect, if they’re not available.
So, if you haven’t already, listen to Peter Kopfler who was so thrilled after our recent jOOQ/SQL talks in Vienna that he’s now all into studying standards and using PostgreSQL:
Mind bending talk by @lukaseder about @JavaOOQ at tonight's @jsugtu. My new resolution: Install PostgreSQL and study SQL standard at once.
— Peter Kofler (@codecopkofler) April 7, 2014
Further reading
There was SQL before window functions and SQL after window functions
| Reference: | How can I do This? – With SQL of Course! from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |
