Introduction
When I started working on enterprise projects we were using J2EE and the pooling data source was provided by the application server.

Scaling up meant buying more powerful hardware to support the increasing request demand. The vertical scaling meant that for supporting more requests we would have to increase the connection pool size accordingly.
Horizontal scaling
Our recent architectures shifted from scaling up to scaling out. So instead of having one big machine hosting all our enterprise services, we now have a distributed service network.
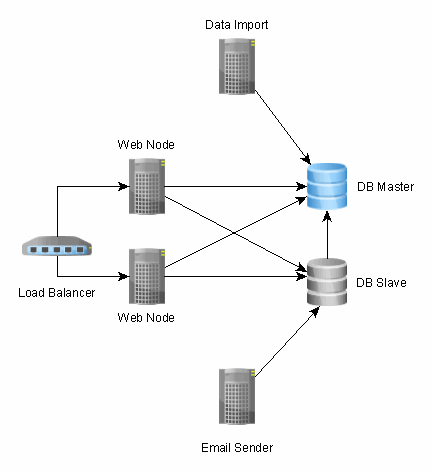
This has numerous advantages:
- Each JVM is tuned according to the hosted service intrinsic behaviour. Web nodes employ the concurrent low pause collector, while batch services use the throughput collector
- Deploying a batch service doesn’t affect the front services
- If one service goes down it won’t affect the rest
Database connection provisioning
But all those services end up calling the database and that’s always done through a database connection. A database server can offer only a limited number of concurrent connections, so connection provisioning is mandatory.
The current connection pooling solutions offer limited monitoring and failover support. This is what we’ve been struggling with lately and that’s why I decided to build Flexy Pool.
There’s a new guy in town
Flexy Pool is a data source proxy offering better monitoring and failover for the following connection pools:
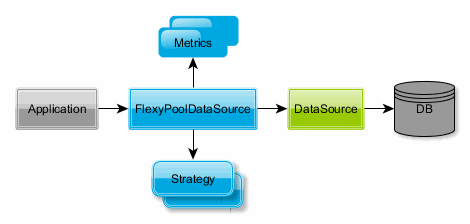
We concluded that sizing connection pools is not an upfront design decision. In large enterprise systems you need adaptability and monitoring is the first step to taking the right decisions.
Advance monitoring
| Name | Description |
|---|---|
| concurrentConnectionCount | This indicates how many connections are being used at once. |
| concurrentConnectionRequestCount | This indicates how many connection are being requested at once. |
| connectionAcquireMillis | A time histogram of the target data source connection acquire interval. |
| connectionLeaseMillis | The lease time is the duration between the moment a connection is acquired and the time it gets released. |
| maxPoolSizeHistogram | A histogram of the target pool size. |
| overallConnectionAcquireMillis | A time histogram of the total connection acquire interval. |
| overflowPoolSizeHistogram | A histogram of the pool size overflowing. |
| retryAttemptsHistogram | A histogram of the retry attempts number. |
Failover strategies
When all pooled connections are being used, a new connection acquire request will wait for a limited amount of time before giving up. This prevents system overloading but to avoid rejecting connection requests you have to properly configure the connection pool size. You will also have to consider traffic spikes and take into consideration all other services competing for the limited amount of database connections. The monitored data can provide you a better insight into connection usage so you’ll be better equipped when deciding the proper pools size.
Flexy Pool was design to be reactive, so it can better adapt to traffic spikes. For this it offers a configurable failover strategy mechanism.
A Strategy is a connection acquiring safety mechanisms, a resort that’s called when a connection is not successfully fetched from the target Connection Pool.
Flexy Pool comes with the following default strategies
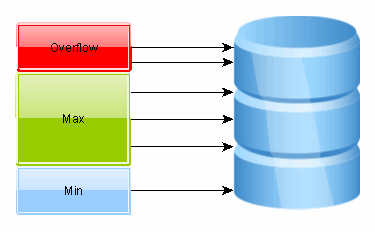
- Increment Pool On TimeoutThis strategy will increment the target connection pool maximum size on connection acquire timeout.The connection pool has a minimum size and on demand it can grow up to its maximum size. The overflow is a buffer of extra connections allowing the connection pool to grow beyond its initial maximum size. Whenever a connection acquire timeout is detected, the current request won’t fail if the pool hasn’t grown to its maximum overflow size.

- Retrying AttemptsThis strategy is useful for those connection pools lacking a connection acquiring retry mechanism
Stay tuned. My next article will demonstrate how Flexy Pool can assist you finding the right pool size.
| Reference: | Flexy Pool, reactive connection pooling from our JCG partner Vlad Mihalcea at the Vlad Mihalcea’s Blog blog. |

Suppose if a connection pool has reached its max size,let us say 100, then upon processing next request, the flexipool will automatically re-size the initial connection pool?
Flexy Pool can adjust the max size upon timeout. So you start with an initial max size of (let’s say) 50 and you give an extra overflow of 50. The final max size can be 100 and it can’t go beyond that limit, but you still have the retrying mechanism left. What’s nice about it, is that it tries to do its best to deal with timeouts, as long as it can increase the max size or has any retry attempts left. The overflow is meant to assist you when your current settings can’t keep up with the current connection… Read more »