Overview
In the rapid changing software world of today, companies and individuals have come up with many methods in order to minimize the time to market gap, i.e the time it takes for your idea to materialize in production. Specially in the very competitive world of mobile and web applications. The success of many companies and individuals have a temporal dimension: they happen to be the first to create an application that solves a specific problem or addresses a particular issue. Tapping into this value stream early is important. As a result, most companies do not pay attention to a product’s build lifecycle — this is usually the last thing if ever to worry about, and your build process is manual and prone to errors.
We want our Operations team to be able to deploy correct and tested code in a manner that is automated and not stressful. It almost seems like we have the predisposition that things will go terribly wrong in production resulting in a constant stand-by, which is why you get the silly rules like ‘avoid Friday pushes…’ or ‘avoid end of day pushes…’, among others.
However, there is a down side to this: while it is important to beat the market and be innovative, it is also equally important to do this with a process that allows you to have a reliable product release, to be responsive to production issues, and manage the lifecycle of the product in an agile fashion. As important as it is to get your name out there, it’s also important to avoid building a bad reputation. You don’t want to lose the few users that tried your application.
Continuous Delivery has its roots in the lean movement. Central to this philosophy is to make the interstitial stages of software delivery as fast as possible and remove waste at every step of the way. An example of such waste is having manual processes. Essentially, any process that is to be repeated, should be automated and carried out by a computer, no exceptions. With that in mind, what we need to build is a deployment pipeline.
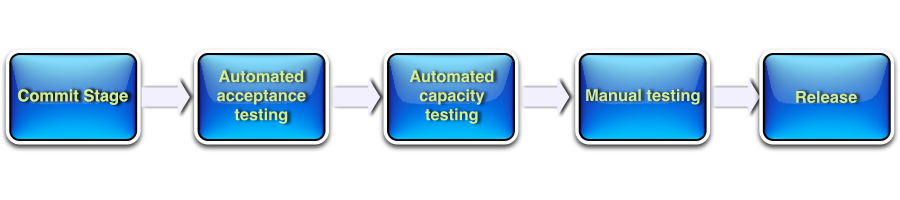
Deployment pipelines will contain different steps, according to what you are trying to build and what makes sense for your team, but in general it will look like the diagram above. By automating this deployment pipeline we address the anti-patterns of manual software releases. Basically, after an Operations (preferably DevOps team) has architected the deployment pipeline, the only human intervention remaining would be the manual testing or some exploratory testing; everything else would be triggered by the push of the deploy button, including the business acceptance tests.
Benefits
1. No stale documentation needed. Let the scripts and code documentation be the all the documentation needed for the development pipeline. If you need to create richer documentation such as design graphs and UML class diagrams, create these in increments. Add documentation to the definition of ‘done’ for each task instead of leaving everything to the last minute.
2. No intermediate human errors, automate everything. The resulting process is repeatable, reliable, and predictable.
3. Easy auditing and versioning. You can enable logging at every step. In addition, Continuous Integration advocates that all configuration be stored and applied from version control.
4. Quicker deployments since there is no human interaction involved. Quicker deployments mean reduced cycle time and tighter feedback loop. Releasing frequently will take the stress away from releases.
5. All systems (development, staging, QA, and production) are deployed by the same scripts. So your process gets tested a lot. This also has the added benefit of bridging the enormous gap between the development, testing, and operations silos.
Challenges
Creating similar development and production-like environments can be difficult and costly. If you work in a cloud environment such as Amazon EC2, Heroku, Google App Engine, PHP Cloud, to new a few, these companies must provide suitable APIs or scripts that you can plug into your deployment pipeline. The same applies if you are bound to an outside IT environment that does not have support for Continuous Delivery. Building quality into the software lifecycle is very important, even if this means spending a few weeks/months architecting the delivery mechanism.
In addition, aligning different teams with different priorities and resources will be difficult, especially when they have different/conflicting goals. Continuous Delivery promotes building cross-functional teams; as a result, QA, development, DBAs, and DevOps must come together to build this process in unison.
Conclusion
So, how can we make the deployment process on production release date a bit less stressful? Well, if you can avoid the following ceremony: sending a long chain of emails orchestrating the entire team, database administrators updating unfamiliar tables, operations engineers deploying unfamiliar code, having different testing and production environments added to the mix, and trying to find that document you jotted down all of the release notes; maybe it wouldn’t by that stressful.
In software, there is opportunity cost to not delivering software, and Continuous Delivery can help facilitate rapid, frequent, quality releases.
Before we finish, I’ll leave you with the principles of software delivery:
- Create repeatable, reliable release process -> Continuous Improvement.
- Automate everything.
- Keep everything in version control.
- Build quality in from the beginning.
- ‘Done’ = ‘Released’.
- All team is responsible for delivery
In later posts, I will spending more time talking about how to implement this process in more detail.
Resources
- Humble, Jez and Farley David. Continuous Delivery: A Reliable Software Releases through Build, Test, and Deployment Automation. Addison Wesley. 2011
Reference: Notes on Continuous Delivery from our JCG partner Luis Atencio at the Luisatencio.net blog.
