Before we start talking about the Hadoop Stack, let us take a step back and try to understand what led to the origins to the Hadoop.
Problem – With the prolification of the internet, the amount of data stored growing up. Lets take an example of a search engine (like Google), that needs to index the large of amount of data that is being generated. The search engine crawls and indexes the data. The index data is stored and retrieval from a single storage device. As the data generated grows, the search index data will keep on increasing.
As the number of queries to access data increase, the current file system I/O becomes inadequate to retrieve large amounts of data simuntaneously. Further, the model of one large single storage starts becoming a bottleneck. To overcome the problem, we move the file system from a single disk storage to a clustered file system. But as the amount of data keeps growing the underlying data that can go one one machine starts to become a bottleneck.
As data reaches TB’s, existing file system based solutions starts faltering. Data access, multiple writers, large file sizes soon become a problem in scaling up the system.
Solution – To overcome the problems, an distributed file system was concieved that provided solution to the above problems. The solution tackled the problem as
- When dealing with large files, I/O becomes a big bottleneck. So, we divide the files into small blocks and store in multiple machines. [Block Storage]
- When we need to read the file, the client sends a request to multiple machines, each machine sends a block of file which is then combined together to pierce the whole file.
- With the advent of block storage, the data access becomes distributed and leads to a faster retrieval/write
- As the data blocks are stored on multiple machines, it helps in removing single point of failure by having the same block on multiple machines. Meaning, if one machine goes, the client can request the block from another machine.
Now, any solution that implements file storage as blocks needs to have the following characteristics
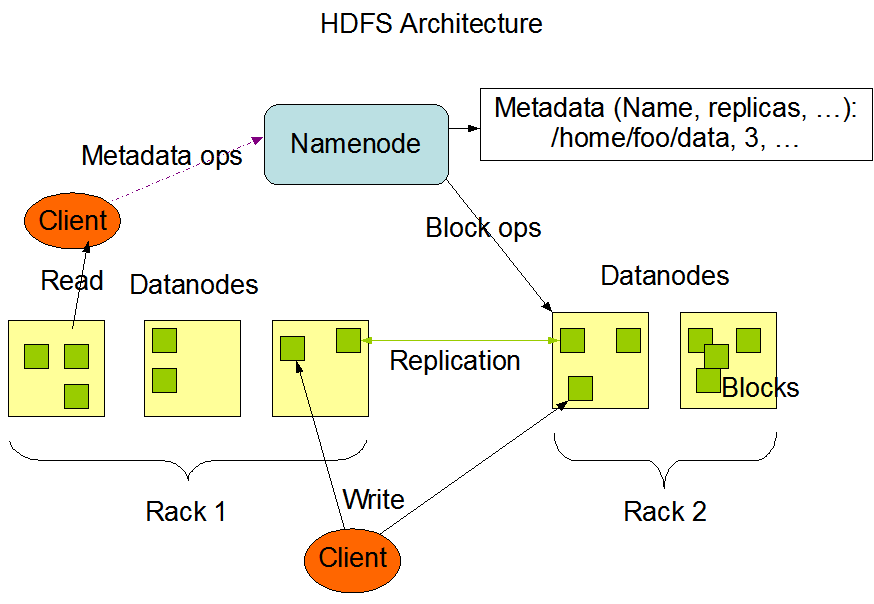
- Manage the meta data information – Since the file gets broken into multiple blocks, somebody needs to keep track of no of blocks and storage of these blocks on different machines [NameNode]
- Manage the stored blocks of data and fulfill the read/write requests [DataNodes]
So, in the context of Hadoop –The NameNode is the arbitrator and repository for all metadata. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode. All these component together form the Distributed File System called as HDFS (Hadoop Distributed File System).
Reference – http://hadoop.apache.org/common/docs/current/hdfs_design.html
HDFS has an inbuild redundancy and replication feature that makes sure that any failure of the machine can be dealt without any loss of data. The HDFS balances itself whenever a new data node is added to the cluster or any of the existing datanode fails.
In addition to the distributed file system called HDFS (Hadoop Distributed File System), there are 2 other core components
- Hadoop Common – are set of utilities that support the Hadoop subprojects. Hadoop Common includes FileSystem, RPC, and serialization libraries.
- Hadoop MapReduce – is a programming model and software framework for writing applications that rapidly process vast amounts of data in parallel on large clusters of compute nodes
So, effectively, when you start working with Hadoop, HDFS and Hadoop MapReduce are the first 2 things you encounter. I will cover MapReduce in subsequent posts.
Reference: HDFS for dummies from our JCG partner Munish K Gupta at the Tech Spot blog.
