The simplest Apache Lucene query, TermQuery, matches any document that contains the specified term, regardless of where the term occurs inside each document. Using BooleanQuery you can combine multiple TermQuerys, with full control over which terms are optional (SHOULD) and which are required (MUST) or required not to be present (MUST_NOT), but still the matching ignores the relative positions of each term inside the document.
Sometimes you do care about the positions of the terms, and for such cases Lucene has various so-called proximity queries.
The simplest proximity query is PhraseQuery, to match a specific sequence of tokens such as “Barack Obama”. Seen as a graph, a PhraseQuery is a simple linear chain:

By default the phrase must precisely match, but if you set a non-zero slop factor, a document can still match even when the tokens are not exactly in sequence, as long as the edit distance is within the specified slop. For example, “Barack Obama” with a slop factor of 1 will also match a document containing “Barack Hussein Obama” or “Barack H. Obama”. It looks like this graph:

Now there are multiple paths through the graph, including an any (*) transition to match an arbitrary token. (Note: while the graph cannot properly express it, this query would also match a document that had the tokens Barack and Obama on top of one another, at the same position, which is a little bit strange!)
In general, proximity queries are more costly on both CPU and IO resources, since they must load, decode and visit another dimension (positions) for each potential document hit. That said, for exact (no slop) matches, using common-grams, shingles and ngrams to index additional “proximity terms” in the index can provide enormous performance improvements in some cases, at the expense of an increase in index size.
MultiPhraseQuery is another proximity query. It generalizes PhraseQuery by allowing more than one token at each position, for example:
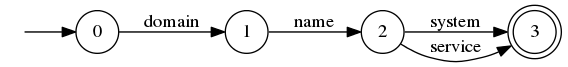
This matches any document containing either domain name system or domain name service. MultiPhraseQuery also accepts a slop factor to allow for non-precise matches.
Finally, span queries (e.g.SpanNearQuery, SpanFirstQuery) go even further, allowing you to build up a complex compound query based on positions where each clause matched. What makes them unique is that you can arbitrarily nest them. For example, you could first build a SpanNearQuery matching Barack Obama with slop=1, then another one matching George Bush, and then make another SpanNearQuery, containing both of those as sub-clauses, matching if they appear within 10 terms of one another.
Introducing TermAutomatonQuery
As of Lucene 4.10 there will be a new proximity query to further generalize on MultiPhraseQuery and the span queries: it allows you to directly build an arbitrary automaton expressing how the terms must occur in sequence, including any transitions to handle slop. Here’s an example:
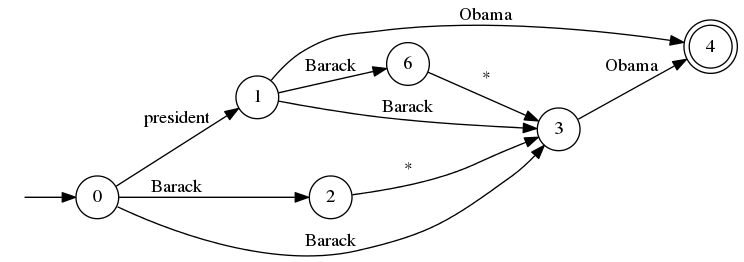
This is a very expert query, allowing you fine control over exactly what sequence of tokens constitutes a match. You build the automaton state-by-state and transition-by-transition, including explicitly adding any transitions (sorry, no QueryParser support yet, patches welcome!). Once that’s done, the query determinizes the automaton and then uses the same infrastructure (e.g.CompiledAutomaton) that queries like FuzzyQuery use for fast term matching, but applied to term positions instead of term bytes. The query is naively scored like a phrase query, which may not be ideal in some cases.
In addition to this new query there is also a simple utility class, TokenStreamToTermAutomatonQuery, that provides loss-less translation of any graph TokenStream into the equivalent TermAutomatonQuery. This is powerful because it means even arbitrary token stream graphs will be correctly represented at search time, preserving the PositionLengthAttribute that some tokenizers now set.
While this means you can finally correctly apply arbitrary token stream graph synonyms at query-time, because the index still does not store PositionLengthAttribute, index-time synonyms are still not fully correct. That said, it would be simple to build a TokenFilter that writes the position length into a payload, and then to extend the new TermAutomatonQuery to read from the payload and apply that length during matching (patches welcome!).
The query is likely quite slow, because it assumes every term is optional; in many cases it would be easy to determine required terms (e.g. Obama in the above example) and optimize such cases. In the case where the query was derived from a token stream, so that it has no cycles and does not use any transitions, it may be faster to enumerate all phrases accepted by the automaton (Lucene already has the getFiniteStrings API to do this for any automaton) and construct a boolean query from those phrase queries. This would match the same set of documents, also correctly preserving PositionLengthAttribute, but would assign different scores.
The code is very new and there are surely some exciting bugs! But it should be a nice start for any application that needs precise control over where terms occur inside documents.
| Reference: | A new proximity query for Lucene, using automatons from our JCG partner Michael Mc Candless at the Changing Bits blog. |
