For most typical Spring/Hibernate enterprise applications, the application performance depends almost entirely on the performance of it’s persistence layer.
This post will go over how to confirm that we are in presence of a ‘database-bound’ application, and then walk through 7 frequently used ‘quick-win’ tips that can help improve application performance.
How to confirm that an application is ‘database-bound’
To confirm that an application is ‘database-bound’, start by doing a typical run in some development environment, using VisualVM for monitoring. VisualVM is a Java profiler shipped with the JDK and launchable via the command line by calling jvisualvm.
After launching Visual VM, try the following steps:
- double click on your running application
- Select Sampler
- click on
Settingscheckbox - Choose
Profile only packages, and type in the following packages:your.application.packages.*org.hibernate.*org.springframework.*your.database.driver.package, for exampleoracle.*- Click
Sample CPU
The CPU profiling of a typical ‘database-bound’ application should look something like this:
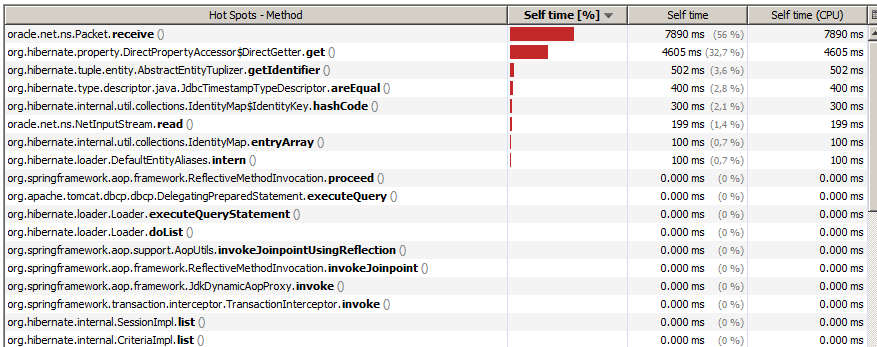
We can see that the client Java process spends 56% of it’s time waiting for the database to return results over the network.
This is a good sign that the queries on the database are what’s keeping the application slow. The 32.7% in Hibernate reflection calls is normal and nothing much can be done about it.
First step for tuning – obtaining a baseline run
The first step to do tuning is to define a baseline run for the program. We need to identify a set of functionally valid input data that makes the program go through a typical execution similar to the production run.
The main difference is that the baseline run should run in a much shorter period of time, as a guideline an execution time of around 5 to 10 minutes is a good target.
What makes a good baseline?
A good baseline should have the following characteristics:
- it’s functionally correct
- the input data is similar to production in it’s variety
- it completes in a short amount of time
- optimizations in the baseline run can be extrapolated to a full run
Getting a good baseline is solving half of the problem.
What makes a bad baseline?
For example, in a batch run for processing call data records in a telecommunications system, taking the first 10 000 records could be the wrong approach.
The reason being, the first 10 000 might be mostly voice calls, but the unknown performance problem is in the processing of SMS traffic. Taking the first records of a large run would lead us to a bad baseline, from which wrong conclusions would be taken.
Collecting SQL logs and query timings
The SQL queries executed with their execution time can be collected using for example log4jdbc. See this blog post for how to collect SQL queries using log4jdbc – Spring/Hibernate improved SQL logging with log4jdbc.
The query execution time is measured from the Java client side, and it includes the network round-trip to the database. The SQL query logs look like this:
16 avr. 2014 11:13:48 | SQL_QUERY /* insert your.package.YourEntity */ insert into YOUR_TABLE (...) values (...) {executed in 13 msec}The prepared statements themselves are also a good source of information – they allow to easily identify frequent query types. They can be logged by following this blog post – Why and where is Hibernate doing this SQL query?
What metrics can be extracted from SQL logs
The SQL logs can give the answer these questions:
- What are slowest queries being executed?
- What are the most frequent queries?
- What is the amount of time spent generating primary keys?
- Is there some data that could benefit from caching ?
How to parse the SQL logs
Probably the only viable option for large log volumes is to use command line tools. This approach has the advantage of being very flexible.
At the expense of writing a small script or command, we can extract mostly any metric needed. Any command line tool will work as long as you are comfortable with it.
If you are used to the Unix command line, bash might be a good option. Bash can be used also in Windows workstations, using for example Cygwin, or Git that includes a bash command line.
Frequently applied Quick-Wins
The quick-wins bellow identify common performance problems in Spring/Hibernate applications, and their corresponding solutions.
Quick-win Tip 1 – Reduce primary key generation overhead
In processes that are ‘insert-intensive’, the choice of a primary key generation strategy can matter a lot. One common way to generate id’s is to use database sequences, usually one per table to avoid contention between inserts on different tables.
The problem is that if 50 records are inserted, we want to avoid that 50 network round-trips are made to the database in order to obtain 50 id’s, leaving the Java process hanging most of the time.
How does Hibernate usually handle this?
Hibernate provides new optimized ID generators that avoid this problem. Namely for sequences, a HiLo id generator is used by default. This is how the HiLo sequence generator it works:
- call a sequence once and get 1000 (the High value)
- calculate 50 id’s like this:
- 1000 * 50 + 0 = 50000
- 1000 * 50 + 1 = 50001
- …
- 1000 * 50 + 49 = 50049, Low value (50) reached
- call sequence for new High value 1001 … etc …
So from a single sequence call, 50 keys where generated, reducing the overhead caused my inumerous network round-trips.
These new optimized key generators are on by default in Hibernate 4, and can even be turned off if needed by setting hibernate.id.new_generator_mappings to false.
Why can primary key generation still be a problem?
The problem is, if you declared the key generation strategy as AUTO, the optimized generators are still off, and your application will end up with a huge amount of sequence calls.
In order to make sure the new optimized generators are on, make sure to use the SEQUENCE strategy instead of AUTO:
@Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "your_key_generator") private Long id;
With this simple change, an improvement in the range of 10%-20% can be measured in ‘insert-intensive’ applications, with basically no code changes.
Quick-win Tip 2 – Use JDBC batch inserts/updates
For batch programs, JDBC drivers usually provide an optimization for reducing network round-trips named ‘JDBC batch inserts/updates’. When these are used, inserts/updates are queued at the driver level before being sent to the database.
When a threshold is reached, then the whole batch of queued statements is sent to the database in one go. This prevents the driver from sending the statements one by one, which would waist multiple network round-trips.
This is the entity manager factory configuration needed to active batch inserts/updates:
<prop key="hibernate.jdbc.batch_size">100</prop> <prop key="hibernate.order_inserts">true</prop> <prop key="hibernate.order_updates">true</prop>
Setting only the JDBC batch size won’t work. This is because the JDBC driver will batch the inserts only when receiving insert/updates for the exact same table.
If an insert to a new table is received, then the JDBC driver will first flush the batched statements on the previous table, before starting to batch statements on the new table.
A similar functionality is implicitly used if using Spring Batch. This optimization can easily buy you 30% to 40% to ‘insert intensive’ programs, without changing a single line of code.
Quick-win Tip 3 – Periodically flush and clear the Hibernate session
When adding/modifying data in the database, Hibernate keeps in the session a version of the entities already persisted, just in case they are modified again before the session is closed.
But many times we can safely discard entities once the corresponding inserts where done in the database. This releases memory in the Java client process, preventing performance problems caused by long running Hibernate sessions.
Such long-running sessions should be avoided as much as possible, but if by some reason they are needed, this is how to contain memory consumption:
entityManager.flush(); entityManager.clear();
The flush will trigger the inserts from new entities to be sent to the database. The clear releases the new entities from the session.
Quick-win Tip 4 – Reduce Hibernate dirty-checking overhead
Hibernate uses internally a mechanism to keep track of modified entities called dirty-checking. This mechanism is not based on the equals and hashcode methods of the entity classes.
Hibernate does it’s most to keep the performance cost of dirty-checking to a minimum, and to dirty-check only when it needs to, but the mechanism does have a cost, which is more noticeable in tables with a large number of columns.
Before applying any optimization, the most important is to measure the cost of dirty-checking using VisualVM.
How to avoid dirty-checking?
In Spring business methods that we know are read-only, dirty-checking can be turned off like this:
@Transactional(readOnly=true)
public void someBusinessMethod() {
....
}An alternative to avoid dirty-checking is to use the Hibernate Stateless Session, which is detailed in the documentation.
Quick-win Tip 5 – Search for ‘bad’ query plans
Check the queries in the slowest queries list to see if they have good query plans. The most usual ‘bad’ query plans are:
- Full table scans: they happen when the table is being fully scanned due to usually a missing index or outdated table statistics.
- Full cartesian joins: This means that the full cartesian product of several tables is being computed. Check for missing join conditions, or if this can be avoided by splitting a step into several.
Quick-win Tip 6 – check for wrong commit intervals
If you are doing batch processing, the commit interval can make a large difference in the performance results, as in 10 to 100 times faster.
Confirm that the commit interval is the one expected (usually around 100-1000 for Spring Batch jobs). It happens often that this parameter is not correctly configured.
Quick-win Tip 7 – Use the second-level and query caches
If some data is identified as being eligible for caching, then have a look at this blog post for how to setup the Hibernate caching: Pitfalls of the Hibernate Second-Level / Query Caches
Conclusions
To solve application performance problems, the most important action to take is to collect some metrics that allow to find what the current bottleneck is.
Without some metrics it is often not possible to guess in useful time what the correct problem cause is.
Also, many but not all of the typical performance pitfalls of a ‘database-driven’ application can be avoided in the first place by using the Spring Batch framework.
| Reference: | Performance Tuning of Spring/Hibernate Applications from our JCG partner Aleksey Novik at the The JHades Blog blog. |

Very interesting article and tons of useful information! I like the idea of filtering profiler stats in visualvm based on packages and I must also check out log4jdbc.
I thought you may also find javamelody (https://code.google.com/p/javamelody) useful as it integrates nicely with Spring/Hibernate. It provides statistics on HTTP requests, Spring beans, SQL, Cache, Quartz. Here’s a post I wrote earlier on how to use javamelody with Spring/Hibernate/Postrgres: http://kaviddiss.com/2014/04/13/analyzing-and-optimizing-sql-queries-in-postgresql/.