In this post, I want to describe how to use JSoup in Android. JSoup is a Java library that helps us to extract and manipulate HTML file. There are some situations when we want to parse and extract some information from and HTML page instead of render it. In this case we can use JSoup that has a set of powerful API very easy to use and integrate in our Android projects. In this post we will discuss how to setup and Android project that uses JSoup and how to extract some information.
JSoup introduction
As said JSoup is a Java library providing a set of API to extract and manipulate HTML files. There are several methods to read and parse an HTML page; in our case we want to retrieve it from a remote server and then we have to provide an URL. If we want to parse the page as DOM,we have:
Document doc = Jsoup.connect(URL).get();
where doc is an instance of Document class that holds the document retrieved. Now we have our document and we are free to extract information. We can retrieve the title or other information using the HTML tags.
For example if we want to get all the tag named meta, we have:
Elements metaElems = doc.select("meta");where select is the method to use when we want to get tags using CSS-query. For example, if we want to retrieve the attribute value from a tag we have:
String name = metaElem.attr("name");where name is the attribute name. Moreover, we can select all the elements in an HTML page that have a specific CSS class value. For example in this website there are some elements that has a CSS class equals to ‘ topic’, so we have:
Elements topicList = doc.select("h2.topic");where we select just the h2 tag having a class named topic.
If you want to have more information follow this link.
Setup the project and integrate JSoup
The first thing, we have to do is creating a standard Android project that contains a simple Activity, I will assume you are using Android Studio to do it. Once your project is ready, we have to add the JSoup dependency. So open build.gradle file and in the dependency section add:
compile 'org.jsoup:jsoup:1.7.3'
so we have:
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
compile 'com.android.support:appcompat-v7:19.+'
compile 'org.jsoup:jsoup:1.7.3'
}Now we are ready to use JSoup API.
Creating the App
Once we know some basic information about JSoup API, we can start coding our app. At the end we will obtain:
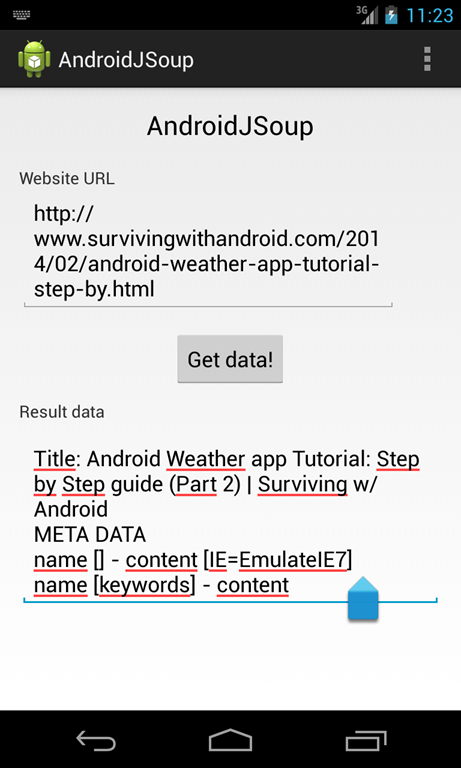
The first thing to have in mind is that we are calling a remote website, so we can’t use our JSoup API in the main thread otherwise we could have ANR problems, so in this example we will use an AsyncTask.
As you can see the layout is very simple: we have an EditText to insert the URL, a button to lunch the HTML parsing and another EditText to show the results. In the main activity we have:
@Override
protected void onCreate(Bundle savedInstanceState) {
...
final EditText edtUrl = (EditText) findViewById(R.id.edtURL);
Button btnGo = (Button) findViewById(R.id.btnGo);
respText = (EditText) findViewById(R.id.edtResp);
btnGo.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
String siteUrl = edtUrl.getText().toString();
( new ParseURL() ).execute(new String[]{siteUrl});
}
});
}where ParseURL is the class in charge of parsing the HTML file using JSoup. Now in this class, we have:
private class ParseURL extends AsyncTask<String, Void, String> {
@Override
protected String doInBackground(String... strings) {
StringBuffer buffer = new StringBuffer();
try {
Log.d("JSwa", "Connecting to ["+strings[0]+"]");
Document doc = Jsoup.connect(strings[0]).get();
Log.d("JSwa", "Connected to ["+strings[0]+"]");
// Get document (HTML page) title
String title = doc.title();
Log.d("JSwA", "Title ["+title+"]");
buffer.append("Title: " + title + "\r\n");
// Get meta info
Elements metaElems = doc.select("meta");
buffer.append("META DATA\r\n");
for (Element metaElem : metaElems) {
String name = metaElem.attr("name");
String content = metaElem.attr("content");
buffer.append("name ["+name+"] - content ["+content+"] \r\n");
}
Elements topicList = doc.select("h2.topic");
buffer.append("Topic list\r\n");
for (Element topic : topicList) {
String data = topic.text();
buffer.append("Data ["+data+"] \r\n");
}
}
catch(Throwable t) {
t.printStackTrace();
}
return buffer.toString();
}
...
@Override
protected void onPostExecute(String s) {
super.onPostExecute(s);
respText.setText(s);
}Analyzing this class at line 8 we connect to the remote url and get the DOM representation of the HTML page. Then at line 11 we retrieve the page title. Using the information about JSoup introduced above, we start selecting the meta tags using select method (line 16). We know there are several meta tags so we iterate over them and retrieve name and content attribute (line 19-20). In the last part we select all the HTML tags having a class equals to topic and iterate over it extracting the text content.
JSoup and Volley
In the example above we used AsyncTask to do the work in background, but if you prefer you can use volley too. In this case we will parse the document not using an URL but a String containing the doc retrieved:
StringRequest req = new StringRequest(Request.Method.GET, url,
new Response.Listener<String>() {
@Override
public void onResponse(String data) {
Document doc = Jsoup.parse(data);
....
}
},
new Response.ErrorListener() {
@Override
public void onErrorResponse(VolleyError volleyError) {
// Handle error
}
}
);| Reference: | Parsing HTML in Android with Jsoup from our JCG partner Francesco Azzola at the Surviving w/ Android blog. |
