In this post I am going to use the AWS MapReduce service (called ElasticMapReduce) by making use of the CLI for EMR.
The process of using EMR can be divided in three steps on a high level:
- set up and fill the S3 buckets
- create and run a EMR job
- get the results from the S3 bucket
Before you can start with these three high level steps there are some other things that have to be arranged:
- you will need to have an AWS account
- you will need to install an S3 client on your machine
- you will need to install EMR CLI on your machine
Well, for the account for AWS I simply assume it is there otherwise it is about time to get yourself one
As an S3 client I make use of s3cmd of which I described the installation here.
To install the EMR CLI (on a MacBook running Lion in my case) I followed the steps as described here. As the instruction says the CLI works with the Ruby version 1.8.7. and not the later versions. Since my MacOS comes with Ruby 1.9.3 by default it indeed didn’t work. But no panic, just get the latest version of the CLI here from the GitHub (I prefer that over downgrading the standard Ruby installation).
When the EMR is installed it needs to be configured. First step is to create a ‘credentials.json’ file in the root directory of the EMR CLI directory. The content of my credentials.json:
{
"access_id": "XXXXXXXXXXXXXXX",
"private_key": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"keypair": "4synergy_palma",
"key-pair-file": "/Users/pascal/4synergy_palma.pem",
"log_uri": "S3://map-reduce-intro/log",
"region": "eu-west-1"
}When the CLI’s are installed we can start with the real work. I just stick to the example in the EMR Developers Guide.
1. Set up and fill the S3 buckets
Open up a Terminal window.
Create S3 bucket from command line:
s3cmd mb s3://map-reduce-intro
Create an input file to be used with test job as input:
nano input.txt
And put some text in it:
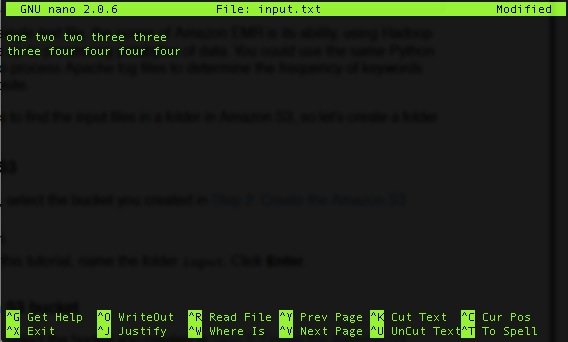
Next upload this file to the bucket in a new folder in the bucket:
s3cmd put input.txt s3://map-reduce-intro/input/
Next create a mapper function (Python script) and upload that to the S3 bucket:
nano wordsplitter.py
and put the example script in it from the developers guide:
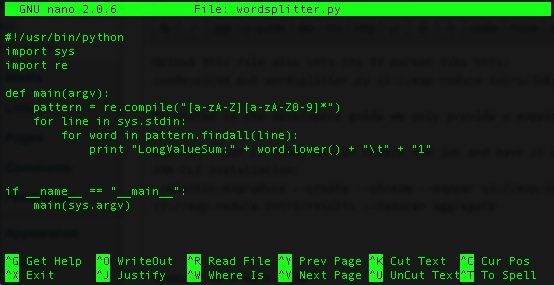
Upload this file also into the S3 bucket like this:
s3cmd put wordsplitter.py s3://map-reduce-intro/job/
As stated in the developers guide we only provide a mapping script since we are using a default reduce function of Hadoop, ‘aggregate’.
Now the input is ready we can create the job and have it executed.
2. Create and run a EMR job
We do this by executing the following command from the root of our EMR CLI installation:
./elastic-mapreduce --create --stream --mapper s3://map-reduce-intro/job/wordsplitter.py --input s3://map-reduce-intro/input --output s3://map-reduce-intro/results --reducer aggregate
The output in the terminal will be simply a job ID like:
Created job flow j-2MO24NGGNMC5N
Get the results from the S3 bucket
If we move to the S3 bucket and list the ‘results’ folder we see the following (please note that it might take a few minutesbefore the cluster is started, executed and terminated):
MacBook-Air-van-Pascal:~ pascal$ s3cmd ls s3://map-reduce-intro/results/ 2013-05-06 20:03 0 s3://map-reduce-intro/results/_SUCCESS 2013-05-06 20:03 27 s3://map-reduce-intro/results/part-00000 MacBook-Air-van-Pascal:~ pascal$
The _SUCCESS file just tells us the job went fine. The file ‘part-00000′ contains the output of our ‘aggregate’ action we performed. To get it do:
s3cmd get s3://map-reduce-intro/results/part-00000
Now if we look at the expected contents:
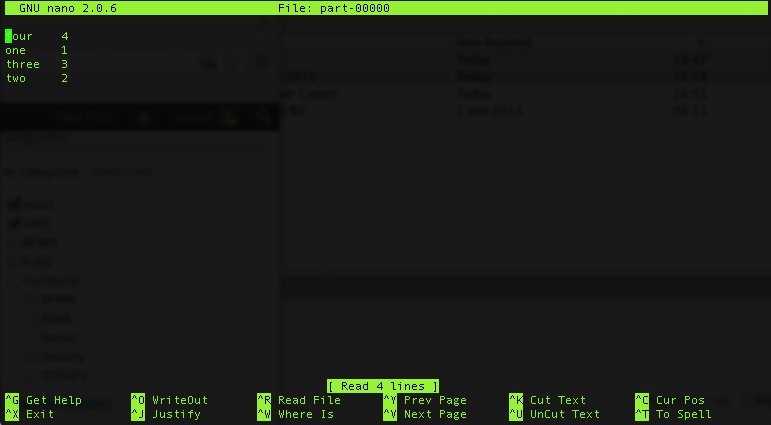
I know this is a very basic example and there is really a lot more to show about EMR but at least this should give you a start to play with it yourself.
One thing to keep in mind is that costs are being charged per hour and that if you only are using a cluster for a few seconds you will be charged for the complete hour. An hour costs about 0.015 cents on top of the EC2 costs of the cluster.
