In the second part of the series we introduced memory management and interrupt handling support provided by virtualization hardware extensions. But effective virtualization solutions need to reach beyond the core to communicate with peripheral devices. In this post we discuss the various techniques used for virtualizing I/O, the problems faced, and the hardware solutions to mitigate these problems.
The Difficulty Of Virtualizing I/O
Before we talk about the hardware solutions at the system level for virtualization we need to set up a motivation for what is driving these features. To appreciate the problems we have to recognize that in some ways communicating with I/O in a
virtualized environment is a paradox. We want to run an operating system in a sandboxed environment where it is oblivious to the the system outside the virtual environment. But I/O cannot be oblivious to the outside environment because it is communicating with that environment. So, understandably virtualizing I/O becomes a difficult problem. So moving away from the philosophical questions, what is the goal of virtualization and how does I/O fit into that goal? In my view it is to provide a managed environment for hosting a VM that improves the overall user experience. To achieve this goal, ideally we’d like I/O in a VM to have the following properties:
- The guest has access to the same I/O devices it would use in a native environment.
- The guest OS cannot affect the I/O operations or memory of other guests.
- The software changes to the guest OS must be minimal.
- The guest OS needs to be able to recover from a failure of the hardware or migration of the VM.
- The I/O operations on the guest OS should have similar performance to running natively.
In this list we can see how several items on the list are competing with other items on the list. So the final solution will require trade-offs based on the particular use-case. Now, With these goals in mind let us look at the various techniques for implementing I/O virtualization and the problems faced.
Emulated Or Paravirtualized Devices
When implementing full virtualization, one of the simplest options is for the guest OS to emulate a virtual device on the host. The guest communicates with this virtual device and the hypervisor detects the guest’s communication. This can be done using trapping of device accesses, or permissions to certain pages of memory. The hypervisor understands the operations by the guest OS on the virtual device and performs the corresponding operation on the physical device. This technique is called hosted or split I/O.
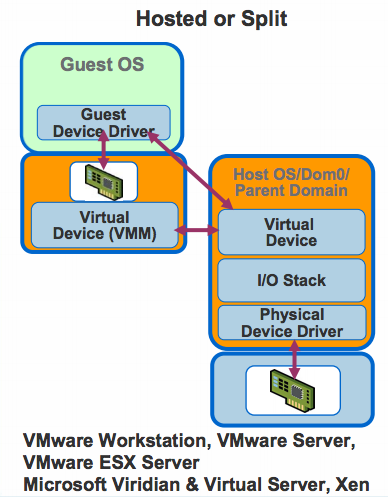
The advantage of this technique is that since every call goes through the hypervisor, the hypervisor can provide the desired functionality. For example the hypervisor can track every I/O operation the device is presently waiting on. Similarly restricting a guest from affecting other guests becomes simplified because all physical device accesses are managed by the hypervisor. But this technique has a high CPU overhead. The data needs to be copied multiple times, processed through multiple I/O stacks, etc. The performance can be improved by using paravirtualization. In this case the device drivers in the OS implement an ABI with the hypervisor. The device drivers interface with the hypervisor and the hypervisor directly communicates with the physical device as is shown in the figure below.
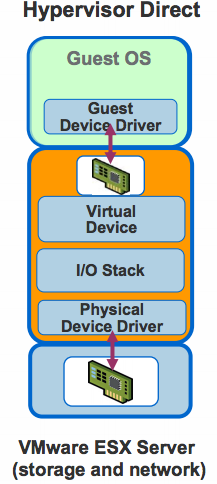
This technique provides better performance with similar control but there is still a significant performance overhead, for example, in trapping to the hypervisor. Figure below shows the difference observed by IBM in using an emulated IDE controller vs IBM’s virtio-blk paravirtualized device drivers in KVM.
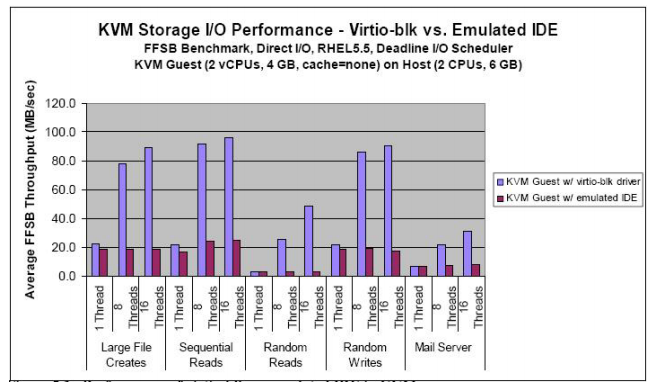
When looking at this overhead it is important to keep in mind it is very use-case dependent. A CPU bound benchmark will not show much sensitivity to the virtualization of I/O. Alternatively for an I/O heavy benchmark this overhead can be significant. As an example the conjugate-gradient method for solving a system of linear equation spends around 70% of CPU cycles in the user mode and spends the remaining time in the hypervisor kernel engaged in disk I/O.
Passthrough I/O
Passthrough I/O greatly improves performance by remapping the guest page tables to directly write to the physical device. This eliminates most of the overhead in trapping to the hypervisor for every operation. This technique brings the bulk of I/O processing to near-native speeds.
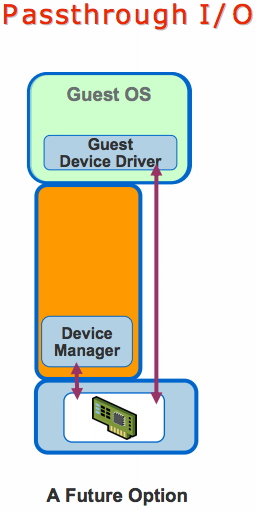
There are several issues that need to be addressed to effectively virtualize I/O using this technique. Consider the case of a guest using DMA accesses to communicate with a device. In this scenario we need to account for the following issues.
Isolation
The goal of virtualization is to to sandbox the guest OS to keep it from accessing the data of other guest OSes. We do this in the guest by adding a second stage translation. However, the DMA devices operate on physical addresses and are not aware of second stage translations. So if a guest is given unrestricted access to a DMA device it can read or write to any physical address in memory and corrupt the memory of other guests. So there needs to be a protection mechanism instituted to make sure a device only directs DMA requests from a particular guest to go to memory associated with that guest. Furthermore, more than one guest may need to access the same device. The device needs to be able to distinguish between the accesses coming from different devices and redirect them correctly.
Physical Address
To complete the DMA transaction the guest OS needs to provide the device with the proper physical address in memory to find the data. But the guest does not know the physical address of the data, only the Intermediate Physical Address (IPA) which is in essence a virtual address. For the DMA access to work the device must be able to translate the IPA to the correct physical address.
Contiguous Memory Blocks
The problem cannot be solved by just providing the device with the correct PA. The device expects the DMA target region to be located in a contiguous region of memory. In a virtualized environment this is not guaranteed. The hypervisor may allocate guest pages that are not contiguous in as small as 4K blocks. So the device must be able to do this translation for the entire DMA region.
32 Bit Devices In Larger Address Spaces
This problem is similar to the problem with a 32 bit guest on a 64 bit host discussed in the previous post. The system may have older devices that cannot access the complete larger address spaces of newer systems. An address translation is necessary to use these devices with a DMA outside their normal addressable range.
Hardware Support
The problems mentioned above are not easily solved in software and need a hardware solution that correctly maps device addresses to the correct guest. Most platforms have hardware solutions for this. This mechanism is called IOMMU for IO Memory Management Unit. Intel calls their implementation VT-d, AMD calls their implementation AMD-Vi, and ARM calls their implementation SystemMMU. The basic idea for the IOMMU is simple. An address translation unit is placed in between any devices that may be used by a guest OS. When the hypervisor is setting up second stage page tables for a guest OS to access the device, it sets up the IOMMU too. Similar to tablewalks in the core, address translations are expensive. So TLBs are implemented to reduce the overhead of address translations.

System MMU
The ARM System MMU is programmed with different translation contexts. It maps each transaction to the corresponding context by matching against expected streams. Based on the context the System MMU may either bypass the translation, cause a fault, or perform a translation. The System MMU in the ARM architecture provides full 2 stage translation support (as described in the previous post) and depending on the context we may either do a first stage translation or a second stage translation. To perform the translation the System MMU has registers analogous to the TTBRs and other control registers for each context.
The system MMU may also receive faults during its translation process or if a context is not setup. Depending on the type of fault and how the System MMU is configured it may take certain actions. A translation fault can trigger an interrupt. This allows an opportunity for the hypervisor to service the interrupt and restart the translation so it can come to completion. The System MMU may also send a BUSERROR to the appropriate requestor. There are syndrome registers present to ease the process of diagnosing and fixing the problem.
Some advantages of System MMU don’t even need virtualization. Since the System MMU enables every device to perform VA to PA translations, I/O operations can be performed by drivers in user-space using VAs. The permission checking and translation maps can ensure one user application does not corrupt the memory of another application . This would eliminate the traps to kernel presently required further reducing I/O overhead. Another problem is dealing with contiguous memory. Many operations result in very large DMA accesses that cannot be allocated a single chunk of memory by the OS. Presently they need to either be split into multiple DMA requests or performed with complex DMA scatter-gather operations. The System MMU enables the device to communicate via a DMA based on a contiguous VA instead of fragmented PAs. This both reduces the CPU overhead and simplifies the software and device.
It should be noted that the System MMU is a part of the platform rather than a part of the core architecture. This means it only affects the drivers. Because of this many features are implementation defined. For example the bits used to match a stream and map it to a context are implementation defined. Since there is no user code that is aware of this part of the system, changes to the system MMU architecture wouldn’t require as many legacy code issues.
So using these techniques the hypervisor can provide an appropriate implementation of virtualized I/O according to the use-case. This concludes the third installment of this series on virtualization. This series continues in the next post discussing the use-cases for virtualization especially the use cases targeted in the mobile space by ARM.
Resources
For more information check out the following resources.
- http://xpgc.vicp.net/course/svt/TechDoc/ch12-IOArchitecturesForVirtualization.pdf
- http://nowlab.cse.ohio-state.edu/NOW/dissertations/huang.pdf
- http://www.ibm.com/developerworks/linux/library/l-virtio/
- http://pic.dhe.ibm.com/infocenter/lnxinfo/v3r0m0/topic/liaat/liaatbestpractices_pdf.pdf
- http://www.mulix.org/lectures/xen-iommu/xen-io.pdf
- http://developer.amd.com/wordpress/media/2012/10/IOMMU-ben-yehuda.pdf
- http://www.arm.com/files/pdf/System-MMU-Whitepaper-v8.0.pdf
- http://software.intel.com/en-us/articles/intel-virtualization-technology-for-directed-io-vt-d-enhancing-intel-platforms-for-efficient-virtualization-of-io-devices
- http://support.amd.com/us/Processor_TechDocs/48882.pdf

