Both. I started working on this little project a couple of months back using Hudson v1.395 and returned to it after the great divide happened. I took it as an opportunity to see whether there would be any significant problems should I choose to move permanently to Jenkins in the future. There were a couple of hiccups- most notably that the new CLI jar didn’t work right out of the box- but overall v1.401 of Jenkins worked as expected after the switch. The good news is the old version of the CLI jar still works, so this example is actually using a mix of code to get things done. Anyway, the software is great and there’s more than enough credit to go around.
The API
Jenkins/Hudson has a handy remote API packed with information about your builds and supports a rich set of functionality to control them, and the server in general, remotely. It is possible to trigger builds, copy jobs, stop the server and even install plugins remotely. You have your choice of XML, JSON or Python when interacting with the APIs of the server. And, as the build in documentation says, you can find the functionality you need on a relative path from the build server url at:
“/…/api/ where ‘…’ portion is the object for which you’d like to access”.
This will show a brief documentation page if you navigate to it in a browser, and will return a result if you add the desired format as the last part of the path. For instance, to load information about the computer running a locally hosted Jenkins server, a get request on this url would return the result in JSON format: http://localhost:8080/computer/api/json.
{
'busyExecutors': 0,
'displayName': 'nodes',
'computer': [
{
'idle': true,
'executors': [
{
},
{
}
],
'actions': [
],
'temporarilyOffline': false,
'loadStatistics': {
},
'displayName': 'master',
'oneOffExecutors': [
],
'manualLaunchAllowed': true,
'offline': false,
'launchSupported': true,
'icon': 'computer.png',
'monitorData': {
'hudson.node_monitors.ResponseTimeMonitor': {
'average': 111
},
'hudson.node_monitors.ClockMonitor': {
'diff': 0
},
'hudson.node_monitors.TemporarySpaceMonitor': {
'size': 58392846336
},
'hudson.node_monitors.SwapSpaceMonitor': null,
'hudson.node_monitors.DiskSpaceMonitor': {
'size': 58392846336
},
'hudson.node_monitors.ArchitectureMonitor': 'Mac OS X (x86_64)'
},
'offlineCause': null,
'numExecutors': 2,
'jnlpAgent': false
}
],
'totalExecutors': 2
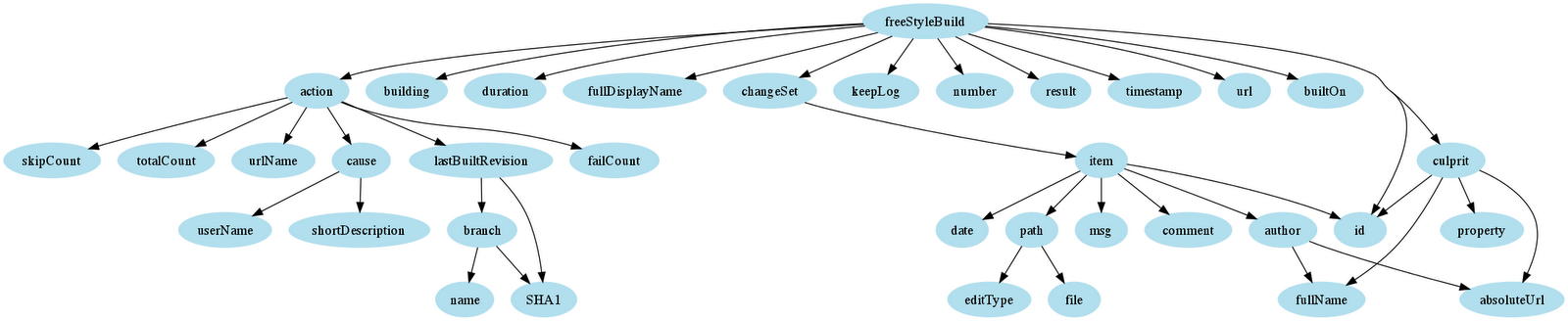
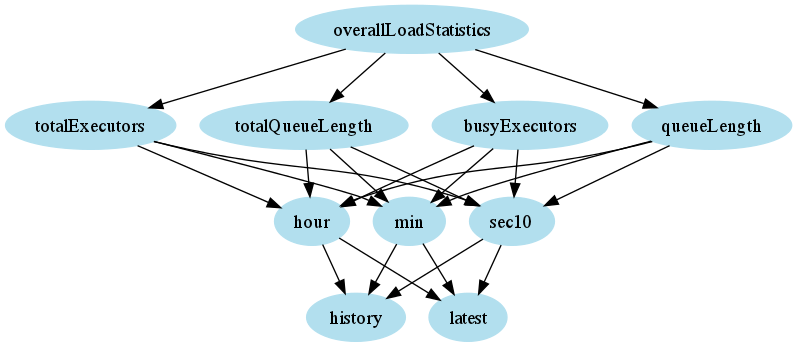
}Here’s the same tree rendered using GraphViz.

This functionality extends out in a tree from the root of the server, and you can gate how much of the tree you load from any particular branch by supplying a ‘depth’ parameter on your urls. Be careful how high you specify this variable. Testing with a load depth of four against a populous, long-running build server (dozens of builds with thousands of job executions) managed to regularly timeout for me. To give you an idea, here’s a very rough visualization of the domain at depth three from the root of the api.

Getting data out of the server is very simple, but the ability to remotely trigger activity on the server is more interesting. In order to trigger a build of a job named ‘test’, a POST on http://localhost:8080/job/test/build does the job. Using the available facilities, it’s pretty easy to do things like:
- load a job’s configuration file, modify it and create a new job by POSTing the new config.xml file
- move a job from one build machine to another
- build up an overview of scheduled builds
The CLI Jar
There’s another way to remotely drive build servers in the CLI jar distributed along with the server. This jar provides simple facilities for executing certain commands remotely on the build server. Of note, this enables installing plugins remotely and executing a remote Groovy shell. I incorporated this functionality with a very thin wrapper around the main class exposed by the CLI jar as shown in the next code sample.
/**
* Drive the CLI with multiple arguments to execute.
* Optionally accepts streams for input, output and err, all of which
* are set by default to System unless otherwise specified.
* @param rootUrl
* @param args
* @param input
* @param output
* @param err
* @return
*/
def runCliCommand(String rootUrl, List<String> args, InputStream input = System.in,
OutputStream output = System.out, OutputStream err = System.err)
{
def CLI cli = new CLI(rootUrl.toURI().toURL())
cli.execute(args, input, output, err)
cli.close()
}And here’s a simple test showing how you can execute a Groovy script to load information about jobs, similar to what you can do from the built-in Groovy script console on the server, which can be found for a locally installed deployment at http://localhost:8080/script.
def 'should be able to query hudson object through a groovy script'()
{
final ByteArrayOutputStream output = new ByteArrayOutputStream()
when:
api.runCliCommand(rootUrl, ['groovysh', 'for(item in hudson.model.Hudson.instance.items) { println('job $item.name')}'],
System.in, output, System.err)
then:
println output.toString()
output.toString().split('\n')[0].startsWith('job')
}
Here are some links to articles about the CLI, if you want to learn more :
- Hudson CLI wikidoc
- Jenkins CLI wikidoc
- A template for PHP jobs on Jenkins
- An article from Kohsuke Kawaguchi
- A nice tutorial
HTTPBuilder
HTTPBuilder is my tool of choice when programming against an HTTP API nowadays. The usage is very straightforward and I was able to get away with only two methods to support reaching the entire API: one for GET and one for POST. Here’s the GET method, sufficient for executing the request, parsing the JSON response, and complete with (albeit naive) error handling.
/**
* Load info from a particular rootUrl+path, optionally specifying a 'depth' query
* parameter(default depth = 0)
*
* @param rootUrl the base url to access
* @param path the api path to append to the rootUrl
* @param depth the depth query parameter to send to the api, defaults to 0
* @return parsed json(as a map) or xml(as GPathResult)
*/
def get(String rootUrl, String path, int depth = 0)
{
def status
HTTPBuilder http = new HTTPBuilder(rootUrl)
http.handler.failure = { resp ->
println 'Unexpected failure on $rootUrl$path: ${resp.statusLine} ${resp.status}'
status = resp.status
}
def info
http.get(path: path, query: [depth: depth]) { resp, json ->
info = json
status = resp.status
}
info ?: status
}Calling this to fetch data is a one liner, as the only real difference is the ‘path’ variable used when calling the API.
private final GetRequestSupport requestSupport = new GetRequestSupport()
...
/**
* Display the job api for a particular Hudson job.
* @param rootUrl the url for a particular build
* @return job info in json format
*/
def inspectJob(String rootUrl, int depth = 0)
{
requestSupport.get(rootUrl, API_JSON, depth)
}Technically, there’s nothing here that limits this to JSON only. One of the great things about HTTPBuilder is that it will happily just try to do the right thing with the response. If the data returned is in JSON format, as these examples are, it gets parsed into a JSONObject. If on the other hand, the data is XML, it gets parsed into a Groovy GPathResult. Both of these are very easily navigable, although the syntax for navigating their object graphs is different.
What can you do with it?
My primary motivation for exploring the API of Hudson/Jenkins was to see how I could make managing multiple servers easier. At present I work daily with four build servers and another handful of slave machines, and support a variety of different version branches. This includes a mix of unit and functional test suites, as well as a continuous deployment job that regularly pushes changes to test machines matching our supported platform matrix, so unfortunately things are not quite as simple as copying a single job when branching. Creating the build infrastructure for new feature branches in an automatic, or at least semi-automatic, fashion is attractive indeed, especially since plans are in the works to expand build automation. For a recent 555 day project, I utilized the API layer to build a Grails app functioning as both a cross-server build radiator and a central facility for server management. This proof of concept is capable of connecting to multiple build servers and visualizing job data as well as specific system configuration, triggering builds, and direct linking to each of the connected servers to allow for drilling down further. Here’s a couple of mock-ups that pretty much show the picture.

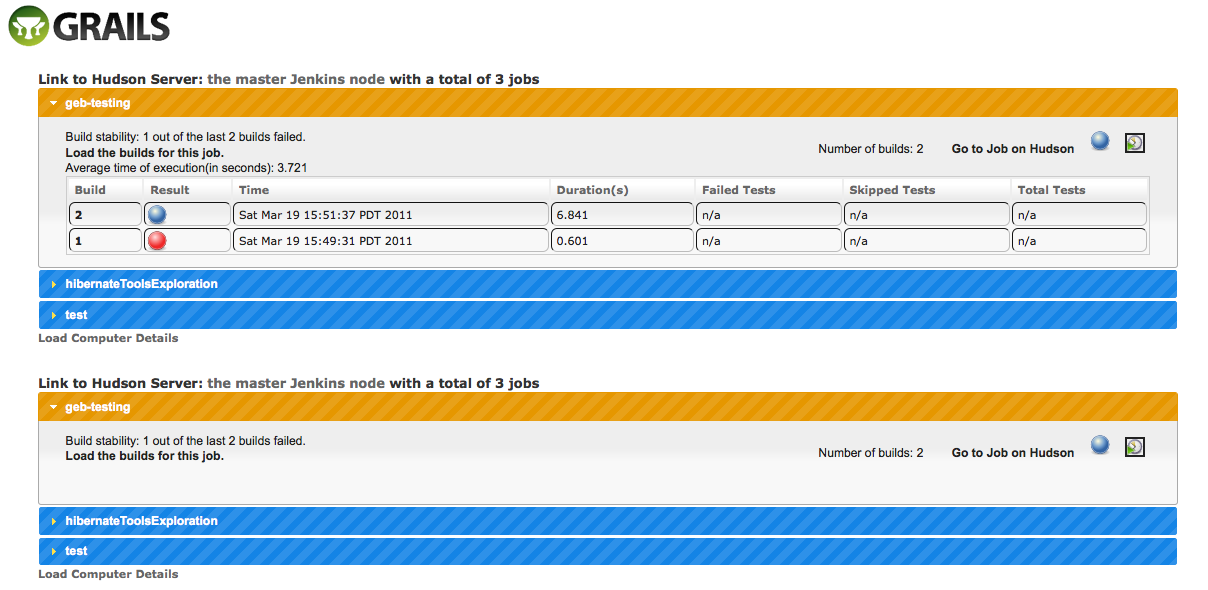
Just a pretty cool app for installing Jenkins
This is only very indirectly related, but I came across this very nice and simple Griffon app, called the Jenkins-Assembler which simplifies preparing your build server. It presents you with a list of plugins, letting you pick and choose, and then downloads and composes them into a single deployable war.

Enough talking – where’s the code???
Source code related to this article is available on github. The tests are more of an exploration of the live API than an actual test of the code in this project. They run against a local server launched using the Gradle Jetty plugin. Finally, here’s some pretty pictures for you.
[Show as slideshow]
[View with PicLens]

.png)
.png)
.png)
.png)
.png)
Continue to Part 2.
Reference: Hooking into the Jenkins(Hudson) API from our JCG partner Kelly Robinson at the The Kaptain on … stuff blog.
