Understanding API Caching and Its Benefits in Improving Performance and User Experience
Every time a user taps a button, loads a feed, or runs a search, their request travels across a network to a server, which in turn queries databases, calls downstream services, and assembles a response before sending it back. Under light load that chain works fine. Under real-world conditions — concurrent users, global audiences, spiky traffic — it becomes a bottleneck that degrades performance, drives up infrastructure costs, and quietly erodes user trust.
Caching is the most powerful single tool available for breaking that chain. Rather than repeating the same expensive work for every identical request, a well-designed cache stores a computed response and serves it directly the next time someone asks. The result is faster responses, lower server load, reduced bandwidth consumption, and a more resilient system overall. Yet caching is also famously easy to implement badly. Understanding the underlying principles — the layers, the strategies, the freshness mechanisms — is what separates a cache that helps from one that quietly serves stale data nobody notices.
This article covers how API caching works conceptually, the layers where it operates, the strategies teams choose from, how freshness and invalidation are managed, and why the numbers behind a well-tuned cache are so compelling.
Scale of the problem: According to Cloudflare’s 2025 Internet Trends report, API traffic now accounts for over 57% of all HTTP requests on the public internet. Without caching, the infrastructure required to serve that volume at consistent latency would be economically prohibitive for most organisations.
What caching actually means for an API
At its most fundamental level, an API cache is a storage layer that sits between the requester and the origin — the database, compute service, or third-party system that generates the canonical response. When a request arrives and a valid cached copy already exists, the cache returns that copy without touching the origin at all. This is called a cache hit. When no valid copy exists, the request passes through to the origin, the response is stored in the cache for future use, and then returned to the requester. That is a cache miss.
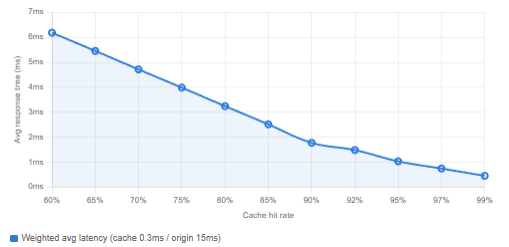
The ratio of hits to total requests — the cache hit rate — is the primary metric by which a cache’s effectiveness is measured. And the difference between a modest and an excellent hit rate is not merely incremental. When cache latency is 0.3 milliseconds and origin latency is 15 milliseconds, moving from a 60% hit rate to a 99% hit rate reduces average response time by a factor of 12.7. That is not a marginal optimisation — it is a fundamental shift in the quality of experience a system delivers.
The caching layers: where responses live
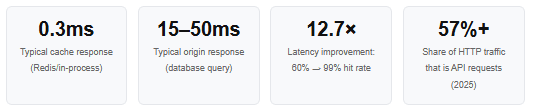
One of the conceptual shifts that makes caching easier to reason about is recognising that it is not a single mechanism but a hierarchy of mechanisms. Responses can be cached at multiple points along the request path, and each layer has different characteristics in terms of proximity to the user, storage capacity, and invalidation control.
- Client-side cache (browser / mobile app)The closest cache to the user. HTTP response headers instruct the client on whether and how long to store a response locally. For stable content such as product catalogues or reference data, a client-side cache eliminates the network round-trip entirely — the fastest possible response.
- CDN edge cacheGeographically distributed nodes that cache responses close to users worldwide. A request originating in São Paulo that hits a CDN edge in that region never needs to travel to an origin server in Frankfurt. CDNs are no longer just for static assets — modern edge computing platforms like Cloudflare Workers and AWS CloudFront Functions allow logic execution and even personalised response caching at the edge.
- API gateway cacheAn intermediate layer that many organisations operate between their public API surface and their backend services. Gateway caches are useful for protecting backend services from traffic spikes, applying consistent TTL policies across endpoints, and enforcing rate limits alongside caching rules.
- Application-level in-memory cacheA cache managed by the application itself — often a local LRU structure held in the process’s own memory. Extremely fast, but limited in capacity and not shared between instances. Useful for hot data accessed repeatedly within a single service, such as configuration objects or frequently read reference lists.
- Distributed cache (Redis / Memcached)A shared, networked cache that all instances of a service can read from and write to. This is the backbone of most production caching architectures. It scales independently of the application, supports complex data structures, and provides a consistent view of cached state across a horizontally scaled fleet.
- Database query cacheThe lowest level, managed within the database itself. Results of expensive queries can be cached at this layer, reducing compute load on the database engine. However, this layer provides the least control and should be treated as a supplementary mechanism rather than a primary caching strategy.
In practice, the most effective architectures combine multiple layers: browser cache for static assets, CDN for public content, application-level in-memory cache for the hottest data, and a distributed cache for shared mutable state. Each layer intercepts the requests it can serve most efficiently, so the ones that reach the origin are genuinely those that cannot be cached.
Chart: response time across caching layers
Approximate response latency by layer — from client cache to uncached origin (lower is better)
The core caching strategies
Choosing a caching strategy is not a single decision but a set of trade-offs between simplicity, consistency, and performance. Each strategy answers the question slightly differently: when should the cache be populated, and how should writes be handled?
Cache-aside (lazy loading)
The most widely used pattern. The application is responsible for managing the cache explicitly. When a request arrives, the application checks the cache first. On a miss, it fetches the data from the origin, stores it in the cache, and returns it. The cache is populated lazily — only data that is actually requested gets cached. This means the cache starts empty and fills over time, so early traffic after a deployment or cache flush may experience higher latency than steady state. Cache-aside is well-suited to read-heavy workloads where the application has detailed knowledge of which data is worth caching.
Write-through caching
Every write operation updates both the cache and the origin simultaneously. This ensures the cache is always consistent with the origin — no stale data can exist for a key that has been written through. The trade-off is write latency: every update must complete two writes before returning. Write-through is particularly appropriate for data where reads immediately after writes are common and staleness would cause visible errors, such as user account balances or inventory quantities.
Write-behind (write-back) caching
Writes go to the cache first and are flushed to the origin asynchronously. This provides very low write latency and high write throughput, but introduces a window of inconsistency: if the cache fails before the write is flushed, data can be lost. Write-behind is most appropriate in high-write workloads where eventual consistency is acceptable and losing a small number of writes in a failure scenario is a tolerable risk.
Read-through caching
Superficially similar to cache-aside, but with the cache itself — rather than the application — responsible for populating on a miss. When the cache receives a request for a key it does not hold, it fetches the data from the origin, stores it, and returns it. The application always talks to the cache, never directly to the origin. This simplifies application code but makes the cache a single point through which all reads flow, which can become a bottleneck if the cache layer itself is not sized or replicated appropriately.
Stale-while-revalidate
A strategy that prioritises low latency over strict freshness. When a cached item’s TTL has expired, rather than blocking the request while fetching a fresh copy from the origin, the cache immediately returns the stale item and kicks off a background refresh. The user receives a response with no additional latency; the next request, arriving moments later, will find a fresh copy already in place. The stale-while-revalidate pattern ensures users get instant responses from cached data while fresh data is fetched in the background, making it one of the most user-experience-friendly strategies available for data that does not require strict freshness guarantees.
| Strategy | Read latency | Write latency | Consistency | Best suited for |
|---|---|---|---|---|
| Cache-aside | Low (after warm-up) | Origin only | Eventual | Read-heavy; app has full cache control |
| Write-through | Low | Higher (two writes) | Strong | Read-after-write patterns; financial data |
| Write-behind | Low | Very low | Eventual (risk of loss) | High-write workloads; eventual consistency acceptable |
| Read-through | Low | Origin only | Eventual | Simplified application logic; consistent read path |
| Stale-while-revalidate | Very low (always instant) | Origin only | Slightly stale during refresh | High-traffic public APIs; UX-sensitive endpoints |
TTL: the clock that governs freshness
Every cached item needs an answer to a single question: how long is this data good for? The Time-to-Live setting — universally abbreviated as TTL — is the primary mechanism for answering that question. When a TTL expires, the cached item is considered stale, and the next request for that key will trigger a fresh fetch from the origin.
Setting TTL correctly is far more nuanced than it first appears. Set it too short and the cache provides little benefit — the cache miss rate is high, origin load remains elevated, and the cost of serialising and storing data is not recouped. Set it too long and users see outdated information, which can range from a minor annoyance to a serious correctness problem depending on the data involved.
The practical answer is that TTL should reflect the natural rate of change of the data, not a uniform system-wide setting. Static assets like fonts and hashed build artefacts can be cached for up to a year. Public API data and product images suit one to twenty-four hours. Search results and pricing pages suit one to five minutes. User dashboards, checkout flows, and authentication endpoints should generally not be cached at all.
The TTL calibration principle: When in doubt, start with a shorter TTL and lengthen it as you observe cache hit rates and data freshness requirements in production. A TTL that is too short can be extended without user-visible side effects; a TTL that is too long can serve stale data that damages trust before anyone notices.
Cache invalidation: the hardest problem
Phil Karlton’s famous observation — that there are only two hard things in computer science: cache invalidation and naming things — remains as relevant as ever. TTL provides automatic expiry, but it is a blunt instrument. When data changes at the source, a cached copy does not know it has been superseded until the TTL clock runs out.
For many use cases, that delay is acceptable. For others it is not — and that is where active invalidation strategies come in.
TTL expiry
The simplest approach: set a TTL and let the cache expire naturally. Easy to implement, operationally low-complexity, and sufficient when data changes are infrequent relative to the TTL window. The downside is that, in the worst case, stale data persists for nearly the full TTL duration after the source has changed.
Event-driven invalidation
Rather than waiting for a TTL to expire, events emitted by the source system trigger cache purges or updates immediately. When an order is completed, an event fires and the relevant cache keys are invalidated in real time. Event-driven purges — such as webhooks or Change Data Capture — can trigger immediate cache updates whenever the underlying data changes, keeping cached responses in sync. This approach offers the tightest consistency guarantees and is well-suited to data where staleness has visible business consequences.
Surrogate key purging
A technique popularised by CDN providers such as Fastly and Cloudflare. Objects stored in the cache are tagged with one or more surrogate keys — semantic labels that describe what the object contains. When a specific entity changes, all objects tagged with that entity’s surrogate key can be purged in a single operation, even if those objects are spread across thousands of distinct cache URLs. This is particularly powerful for content-heavy systems where one piece of source data may be embedded in many different cached responses.
Cache warming
Rather than waiting for users to trigger cache fills after a flush or deployment, cache warming proactively populates the cache with expected hot data before traffic arrives. This prevents the thundering herd problem — the burst of origin load that occurs when many users simultaneously encounter a cold cache. Cache warming is especially important for critical data where a burst of simultaneous cache misses could overwhelm the backend.
The thundering herd: When a popular cache entry expires and many concurrent users request the same key simultaneously, each of them triggers an independent origin fetch. The result can be hundreds of identical database queries arriving in milliseconds. Mitigating this requires either cache warming, request coalescing (ensuring only one origin fetch is triggered per key regardless of concurrency), or staggered TTL jitter to prevent synchronised expiry.
Chart: the effect of hit rate on weighted average latency
Weighted average API response time at different cache hit rates (cache = 0.3ms, origin = 15ms)
HTTP caching semantics: how the web’s own machinery works
A distinct but deeply related topic is the standardised HTTP caching mechanism built into the web itself. Unlike application-level caches that require custom code, HTTP caching is implemented by every browser, CDN, and HTTP proxy on the planet, making it a zero-marginal-cost caching layer for any API that speaks HTTP.
The primary instrument is the Cache-Control response header, which carries directives that tell every cache in the response path how to handle the item. The max-age directive specifies, in seconds, how long the response can be considered fresh. The public directive signals that the response can be cached by shared caches like CDNs, while private restricts caching to the end client’s browser. The no-store directive prevents any caching at all, and no-cache allows storage but requires revalidation with the origin before serving.
Alongside Cache-Control, two validation mechanisms allow caches to check whether a stored response is still valid without fetching the full response body again. ETags provide a unique validation token that confirms whether cached content is current, while the Last-Modified header provides a timestamp for the resource. When a cached item’s TTL has expired, the client can send a conditional request carrying the ETag or Last-Modified value; if the origin determines that nothing has changed, it responds with a compact 304 Not Modified rather than re-transmitting the full payload. This saves bandwidth and reduces origin compute load while preserving freshness guarantees.
What caches should never hold
Knowing what to cache is only half of the discipline; knowing what to exclude is equally important. Caching the wrong data leads to correctness failures, security vulnerabilities, and wasted memory. Certain categories of data are either inherently uncacheable or require careful handling.
| Data category | Caching suitability | Reason |
|---|---|---|
| Public reference data (country lists, categories) | Excellent — long TTL | Changes rarely; high read volume; no privacy risk |
| Product listings and descriptions | Good — medium TTL | Changes occasionally; significant traffic; safe to serve slightly stale |
| Aggregate statistics and dashboards | Good — short to medium TTL | Expensive to compute; tolerable staleness of seconds to minutes |
| Per-user personalised data | Caution — private cache only | Must never be stored in shared caches; requires user-scoped cache keys |
| Financial balances and real-time inventory | Short TTL or skip | Stale values have direct business impact; prefer write-through or no cache |
| Authentication tokens and session data | Do not cache in shared layers | Security-sensitive; leaking between users is a serious vulnerability |
| Checkout and payment responses | Never cache | Non-idempotent operations; caching can cause double charges or order duplication |
The broader benefits: beyond raw latency
Faster responses are the most visible benefit of caching, but the full value extends considerably further. Consequently, the business case for investing in a robust caching strategy reaches well beyond the engineering team.
From an infrastructure cost perspective, every cache hit is a database query that does not run, a compute cycle that does not occur, and a byte of bandwidth that does not get transferred. Intelligent caching strategies reduce infrastructure costs by approximately 80% in high-read workloads. For organisations serving millions of API requests per day, that is not a marginal saving — it is the difference between a system that scales economically and one that demands constant capacity expansion.
From a resilience perspective, caches act as a buffer between users and origin systems. During traffic spikes driven by viral social media moments, seasonal events, or integrations triggering bulk requests, a well-warmed cache absorbs the burst without passing it to backend services. Furthermore, certain caching patterns allow systems to continue serving responses even when the origin is temporarily degraded, by serving stale content rather than returning errors — a capability that can mean the difference between a degraded-but-functional user experience and a complete outage.
From a user experience perspective, the connection between response time and user satisfaction is well-established. A user who receives a result in 200 milliseconds has a qualitatively different experience than one who waits 1.5 seconds, even though both responses are technically within acceptable limits. Caching reduces response times from the 200–500ms range to under 10ms for frequently accessed data, a shift that users perceive immediately even if they cannot articulate why the application feels different.
The flywheel effect: A faster API leads to higher engagement. Higher engagement produces more requests to the same endpoints. More requests to cacheable endpoints improve the cache hit rate organically. A higher hit rate further reduces latency. This self-reinforcing loop means the benefits of caching compound over time as usage patterns stabilise.
Eviction policies: what the cache forgets and when
A cache has finite memory. When it fills up, something must be removed to make room for new items. The eviction policy determines what gets discarded. Different policies optimise for different access patterns, and choosing the wrong one for a workload can significantly reduce the effective hit rate.
The Least Recently Used policy removes the item that has gone the longest without being accessed. This is the most widely used policy and performs well for workloads where recent access is a reasonable predictor of future access. The Least Frequently Used policy instead removes the item that has been accessed the fewest times overall, making it better suited to workloads where some items are consistently popular regardless of when they were last accessed. Time-based expiry simply removes items once their TTL has elapsed, regardless of access patterns — the simplest policy and often the right starting point before optimising further.
In practice, combining TTL with LRU eviction balances freshness and performance effectively for most general-purpose API caching scenarios. TTL prevents indefinitely stale data; LRU prevents the cache from filling with items that are never requested again.
Observability: measuring what the cache is actually doing
A cache that is not observed is a cache that cannot be improved. The metrics that matter most in a production caching system are the cache hit rate, the eviction rate, the miss rate broken down by endpoint, and the origin traffic reduction percentage. Together these tell the story of whether the cache is serving its purpose and where the gaps are.
A cache hit rate below 80% is almost always a signal that either the TTL is too short, the cache key is too granular (capturing query-string variations that could safely be ignored), or the cache size is too small and evictions are too frequent. Conversely, a cache that reports very high hit rates alongside growing user complaints about stale data is almost certainly using TTLs that are too long for the volatility of the data being served.
Monitoring should also track the pattern of misses — specifically, whether they tend to cluster in time (suggesting synchronised TTL expiry causing thundering herds) or are distributed evenly (suggesting normal cache miss behaviour). Staggering TTLs slightly using randomised jitter prevents the former.
What we have learned
In this article, we explored API caching from first principles through to the practical decisions that determine whether a caching layer actually delivers on its promise. We started with the fundamental mechanics of cache hits and misses and why the relationship between hit rate and latency is non-linear — moving from 60% to 99% hit rate is a 12.7× latency improvement, not a 39% one.
We then walked through the full hierarchy of caching layers: client, CDN edge, API gateway, application-level in-memory, distributed cache, and database query cache, noting that effective architectures typically combine several of these rather than relying on any single layer. We covered the five core caching strategies — cache-aside, write-through, write-behind, read-through, and stale-while-revalidate — along with the trade-offs each one makes between read latency, write latency, and consistency.
We examined TTL as the primary freshness mechanism, why TTL settings must reflect the natural rate of change of individual data types rather than a blanket system value, and the three main invalidation strategies — TTL expiry, event-driven purging, and surrogate key purging — for keeping cached data trustworthy. Finally, we covered the broader benefits of caching beyond raw speed: infrastructure cost reduction, system resilience under traffic spikes, and the compounding UX gains that follow as hit rates improve over time.
