Both patterns produce a stream of state changes — yet they sit at entirely different layers of your stack, solve different problems, and carry very different costs. Here is how to tell them apart and pick the right one.
At first glance, Event Sourcing and Change Data Capture (CDC) look like two names for the same idea: capture what changed, and send it somewhere useful. In practice, however, the two patterns differ in where they live, what guarantees they offer, and how much they will cost your team to introduce. Getting this choice wrong is expensive — Event Sourcing in particular rewrites the rules of how your application persists data, and rolling it back after the fact is rarely straightforward.
In this article, we will walk through both patterns clearly, compare them across the dimensions that actually matter in production, and end with a practical decision guide. Along the way, we will look at Java and Spring Boot examples using the tools most teams reach for: Debezium for CDC, and frameworks like Axon or EventStoreDB for Event Sourcing.
What Is Event Sourcing?
Event Sourcing is an application-level design pattern. Instead of persisting only the current state of an entity — the usual row in a relational table — the application records every change that happened to that entity as an immutable event. The current state is then derived by replaying those events in order.
Think about a bank account. In a traditional CRUD model, you store the current balance and overwrite it on every transaction. With Event Sourcing, you instead append events like MoneyDeposited(amount=500) and MoneyWithdrawn(amount=200). To find the current balance, you fold those events from the beginning — or from the latest snapshot.
// Axon Framework — a simple event-sourced aggregate in Spring Boot
@Aggregate
public class BankAccount {
@AggregateIdentifier
private String accountId;
private BigDecimal balance;
@CommandHandler
public BankAccount(OpenAccountCommand cmd) {
apply(new AccountOpenedEvent(cmd.getAccountId(), cmd.getInitialDeposit()));
}
@EventSourcingHandler
public void on(AccountOpenedEvent event) {
this.accountId = event.getAccountId();
this.balance = event.getInitialDeposit();
}
@CommandHandler
public void handle(DepositMoneyCommand cmd) {
apply(new MoneyDepositedEvent(accountId, cmd.getAmount()));
}
@EventSourcingHandler
public void on(MoneyDepositedEvent event) {
this.balance = this.balance.add(event.getAmount());
}
}
Notice that the aggregate never calls save(). The events themselves are the source of truth, and the event store is the primary database. This is what distinguishes Event Sourcing from simply publishing domain events alongside a CRUD persist — in Event Sourcing the event is the persistence.
As the event log grows, replaying from the beginning becomes slow. The snapshot pattern periodically saves the current state so consumers can start from the latest snapshot and replay only subsequent events. Most Event Sourcing frameworks include this out of the box.
What Is Change Data Capture?
Change Data Capture is a database-level technique. It monitors the transaction log of an existing database — PostgreSQL’s WAL, MySQL’s binlog, MongoDB’s oplog — and emits a structured event for every row-level insert, update, or delete. Crucially, the application does not need to be aware of any of this. It keeps writing to its tables exactly as before, and the CDC connector reads the change events externally.
Debezium is the most widely adopted open-source CDC tool in the Java ecosystem. It runs as a Kafka Connect connector and streams change events to Kafka topics, which downstream services can then consume in real time.
# Debezium PostgreSQL connector configuration (connector.json)
# Deploy via Kafka Connect REST API:
# POST http://localhost:8083/connectors
{
"name": "pg-orders-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "localhost",
"database.port": "5432",
"database.user": "debezium",
"database.password": "dbz",
"database.dbname": "shop",
"topic.prefix": "shop",
"table.include.list": "public.orders",
"plugin.name": "pgoutput"
}
}
Once that connector is running, every change to the orders table is automatically published to the Kafka topic shop.public.orders as a structured event containing both the before and after state of the row. Downstream consumers — an analytics service, a search indexer, an audit log — subscribe to that topic and react accordingly.
A single business action — say, “transfer $100 from account A to account B” — may produce several CDC events: a debit on one row, a credit on another, a transfer record insert. CDC sees the rows; it does not inherently understand the business transaction that caused them.
The Fundamental Difference
The cleanest way to state the core distinction is this:
Event Sourcing
- Events are written by the application
- Events are the primary persistence
- Current state is derived from events
- Domain semantics are baked into event names
- Requires redesigning your data model
Change Data Capture
- Events are read from the database log
- Database state is still primary
- Events are derived from database writes
- Events carry row-level, not domain-level, semantics
- Zero application changes required
As Streamkap puts it well: in true Event Sourcing, events are the primary artifact and database state is derived. With CDC, database state is primary and events are derived. That reversal of cause and effect explains nearly every practical difference between the two.
Side-by-Side Comparison
| Dimension | Event Sourcing | CDC (e.g. Debezium) |
|---|---|---|
| Where it lives | Application layer | Database / infrastructure layer |
| Application changes needed | Yes — significant redesign | No — transparent to app |
| Event semantics | Rich domain events (OrderShipped) | Raw data changes (UPDATE orders SET status='shipped') |
| Full history replay | Yes — events are the store | Limited by log retention |
| Audit trail quality | Excellent — intent is captured | Good — data changes only |
| Retroactive migration | Very hard on existing systems | Easy to bolt on existing systems |
| Operational complexity | High | Medium |
| CQRS compatibility | Natural fit | Works well with Outbox pattern |
| Typical tooling (Java) | Axon, EventStoreDB, Eventuate | Debezium + Kafka Connect |
The Outbox Pattern: Bridging Both Worlds
One of the most practically useful combinations is running CDC on top of an Outbox table. This is where the two patterns genuinely complement each other, and it is increasingly the recommended approach for teams who need domain event semantics without fully committing to an Event Sourcing data model.
The idea is straightforward: your application writes its domain events into a dedicated outbox table as part of the same database transaction that updates the primary state. A CDC connector then reads that outbox table and publishes the events to Kafka. The result is domain-semantic events with transactional guarantees — and no dual-write problem.
-- The outbox table in PostgreSQL
CREATE TABLE outbox_events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
aggregate_id VARCHAR(255) NOT NULL,
event_type VARCHAR(255) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
-- In your Spring service: both writes in one transaction
@Transactional
public void shipOrder(Long orderId) {
Order order = orderRepo.findById(orderId).orElseThrow();
order.setStatus("SHIPPED");
orderRepo.save(order);
outboxRepo.save(new OutboxEvent(
order.getId().toString(),
"OrderShipped",
"{\"orderId\":" + orderId + ",\"shippedAt\":\"" + Instant.now() + "\"}"
));
// Debezium picks up the outbox row and publishes to Kafka automatically
}
Debezium even ships an Outbox Event Router transform that routes events to different Kafka topics based on the aggregate_id or event_type columns, so you do not end up with a single firehose topic for all events.
It gives you domain-semantic events and at-least-once delivery with no distributed transaction, no dual-write race condition, and no application-level retry logic. For most microservice architectures, this is simpler than full Event Sourcing while delivering most of the same downstream benefits.
Comparing Complexity Over Time
One chart worth looking at is how each approach’s operational complexity evolves as a system grows. Event Sourcing starts expensive and stays demanding; CDC starts cheap but can accumulate complexity as your schema and event consumer count scales.
Relative Operational Complexity by System Scale
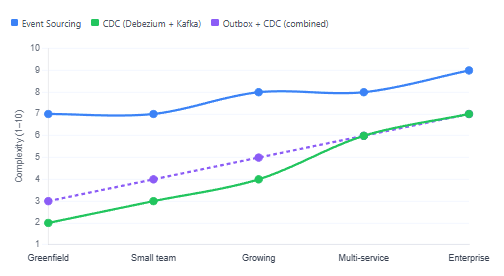
When to Choose Event Sourcing
Event Sourcing is a strong fit when the history of intent is a first-class requirement — not just “what changed” but “why, in what sequence, and who requested it.” However, it imposes real costs, so the use case needs to justify the redesign.
Choose Event Sourcing when…
- You need a complete, tamper-evident audit trail — legal, financial, or compliance scenarios where the sequence of decisions matters.
- Your domain logic involves temporal queries: “what was the state of this entity on this date?”
- You are building a new greenfield service and the team is comfortable with CQRS and event-driven design.
- Business events carry rich semantic meaning that CDC row events cannot capture (
ClaimApprovedvsUPDATE claims SET approved=true). - You need the ability to correct past events and reproject read models — event replay is a first-class feature.
When to Choose CDC
CDC shines in integration and data propagation scenarios, especially when you need to connect systems that already exist and cannot be rewritten. Because it requires zero application changes, it is also the most pragmatic choice for teams that want event-driven integration without taking on architectural debt.
Choose CDC when…
- You need to replicate data from an existing CRUD service to downstream consumers (analytics warehouse, search index, caching layer) without changing that service.
- You are retrofitting event-driven patterns onto a legacy system.
- Your team is comfortable with Kafka and Kafka Connect but not ready for a full Event Sourcing architecture.
- Data synchronization and replication are the primary goals, and row-level semantics are sufficient.
- You want to implement the Outbox pattern to guarantee event delivery without dual-write complexity.
When to Use Both Together
Use both when…
- Event-sourced aggregates need to propagate their events to external systems — CDC on the event store’s projection tables bridges the gap.
- A system has both greenfield event-sourced services and legacy CRUD services that must share a single event bus.
- You want domain events from the Outbox pattern with CDC providing the reliable transport layer.
Tooling Landscape for Java Teams
| Tool | Pattern | Spring Boot Integration | Notes |
|---|---|---|---|
| Debezium | CDC | Spring Cloud Stream, Kafka Connect | Most mature open-source CDC; supports PostgreSQL, MySQL, MongoDB, Oracle and more |
| Axon Framework | Event Sourcing | Native Spring Boot starter | Full CQRS + Event Sourcing framework; pairs with Axon Server as event store |
| EventStoreDB | Event Sourcing | Via Java client library | Purpose-built event store; strong projections support |
| Eventuate Tram | Outbox + CDC | Spring Boot starter available | Specifically designed around the Transactional Outbox pattern with CDC |
| Kafka + Custom Outbox | Outbox + CDC | Spring Kafka, spring-tx | Maximum control; higher setup cost |
Adoption Trends: Where Teams Are Investing
Based on community signals — GitHub stars, conference talks, and job postings — it is clear that CDC and the Outbox pattern have significantly broader adoption among Java teams than full Event Sourcing. Event Sourcing remains the right choice in specific bounded contexts, but it is rarely the default starting point for new services.
Relative Adoption Signal Across Java Ecosystem (2024–2025)
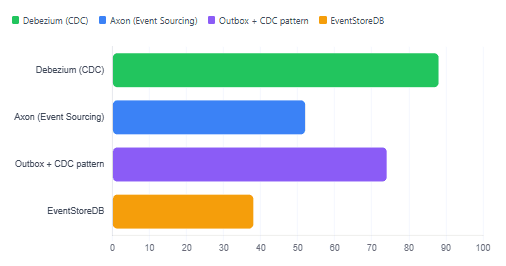
A Quick Decision Tree
If you are still unsure which path to take, the following set of questions will usually narrow it down quickly:
- Do you need to derive business intent from the events? If yes and the system is new → Event Sourcing. If yes and the system is existing → Outbox + CDC.
- Are you integrating with existing services you cannot change? → CDC.
- Is the audit trail a legal or compliance requirement? If intent matters → Event Sourcing. If data changes are sufficient → CDC.
- Does your team have event-driven architecture experience? If not → start with CDC and the Outbox pattern; it is significantly easier to introduce.
- Are you building a new greenfield bounded context where history replay is a first-class feature? → Event Sourcing is a strong candidate.
The engineers behind Debezium have written directly about this: CDC with the Outbox pattern is usually a better alternative to full Event Sourcing and is compatible with CQRS. Event Sourcing still has value in some use cases, but they encourage trying the Outbox approach first.
What We Learned
Event Sourcing and CDC are not competing solutions to the same problem — they operate at entirely different layers of a system. Event Sourcing is an application design pattern where events are the primary persistence artifact, giving you rich domain semantics, full replay capability, and a complete audit trail of intent. CDC is a database infrastructure technique that reads the transaction log and streams row-level changes to downstream consumers, requiring zero application changes and fitting naturally onto existing CRUD systems.
For most Java teams, CDC with the Transactional Outbox pattern is the pragmatic starting point: you get at-least-once event delivery, domain-semantic events, and no dual-write problem — without the significant architectural cost of fully embracing Event Sourcing. Event Sourcing earns its keep in greenfield bounded contexts where temporal queries, complete audit trails, and event replay are genuine requirements, not just aspirational ones. When in doubt, reach for Debezium and an Outbox table first, and layer Event Sourcing into specific aggregates only where the domain truly demands it.
