From the classic Specification API to the new PredicateSpecification in Spring Data 4.0, generic search criteria builders, Querydsl integration, and pagination — everything your search layer needs to stop growing a new repository method for every new filter.
Every enterprise application eventually runs into the same wall. It starts innocently: a repository method called findByStatus. Then someone needs findByStatusAndCategory. Then findByStatusAndCategoryAndPriceGreaterThan. Before long the repository interface has dozens of methods, each covering one specific combination of filter conditions, and adding a new filter means a new method, a new JPQL string to maintain, and a new test to write. The combinatorial explosion is the problem, and Spring Data JPA’s dynamic query toolkit is the solution.
This article walks through the full toolkit — from the foundational Specification interface and how it maps to the JPA Criteria API, to the new PredicateSpecification introduced in Spring Data 4.0 (2025.1), generic criteria builders for truly table-driven search, Querydsl integration for type-safe fluent predicates, and the combination of dynamic filters with pagination and sorting. Along the way, practical code examples show patterns that are in production use in real Spring Boot 3 and 4 applications.
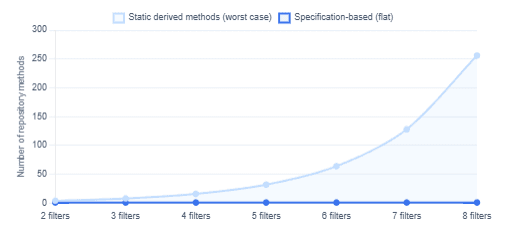
Repository Method Explosion — Static vs Dynamic Query Approach
The Foundation: JPA Criteria API
Before reaching for Spring Data’s abstractions, it helps to understand what sits underneath them. The JPA Criteria API (now at version 3.2 in Spring Data 4.0) is a programmatic, type-safe way to build queries at runtime rather than writing JPQL strings. Instead of constructing query strings by concatenation — an approach that is both fragile and a potential SQL-injection surface — the Criteria API lets you assemble a query object step by step using strongly typed builder objects.
The three central types are: CriteriaBuilder, which creates predicates and expressions; Root<T>, which represents the entity being queried and provides access to its fields; and CriteriaQuery<T>, which represents the assembled query. In practice, writing Criteria API code directly is verbose. Spring Data’s Specification and PredicateSpecification interfaces wrap these types cleanly, hiding most of the boilerplate while exposing just the predicate-construction logic that varies between queries.
Specification<T>: The Classic Approach
The Specification<T> interface is Spring Data JPA’s primary abstraction for dynamic querying. It is a functional interface with a single method — toPredicate(Root<T>, CriteriaQuery<?>, CriteriaBuilder) — that you implement to describe a filter condition. What makes it powerful is composition: two specifications can be combined with .and() and .or(), and the resulting composite specification is itself a Specification that can be combined further.
To enable it, your repository extends JpaSpecificationExecutor<T> alongside the standard JpaRepository:
// Repository — extend JpaSpecificationExecutor to unlock dynamic querying
public interface ProductRepository
extends JpaRepository<Product, Long>,
JpaSpecificationExecutor<Product> {
// No extra methods needed — findAll(Specification, Pageable) is inherited
}
Individual specifications are typically defined as static factory methods grouped in a dedicated class. Each method returns a lambda (or null if the criterion is absent, which is safely handled by Specification.where()):
import org.springframework.data.jpa.domain.Specification;
public class ProductSpecs {
public static Specification<Product> hasCategory(String category) {
if (category == null || category.isBlank()) return null;
return (root, query, cb) ->
cb.equal(root.get("category"), category);
}
public static Specification<Product> nameLike(String keyword) {
if (keyword == null || keyword.isBlank()) return null;
return (root, query, cb) ->
cb.like(cb.lower(root.get("name")), "%" + keyword.toLowerCase() + "%");
}
public static Specification<Product> priceBetween(Double min, Double max) {
if (min == null && max == null) return null;
return (root, query, cb) -> {
if (min == null) return cb.le(root.get("price"), max);
if (max == null) return cb.ge(root.get("price"), min);
return cb.between(root.get("price"), min, max);
};
}
public static Specification<Product> isInStock() {
return (root, query, cb) -> cb.isTrue(root.get("inStock"));
}
}
At the service layer, these atomic specifications are composed at runtime based on which filters the caller actually provided. Null specifications returned by the factories are filtered out by Specification.where(), so the final query only contains the clauses that matter:
import static org.springframework.data.jpa.domain.Specification.where;
@Service
public class ProductService {
private final ProductRepository repo;
public Page<Product> search(ProductFilter f, Pageable pageable) {
Specification<Product> spec = where(ProductSpecs.hasCategory(f.category()))
.and(ProductSpecs.nameLike(f.keyword()))
.and(ProductSpecs.priceBetween(f.minPrice(), f.maxPrice()));
if (Boolean.TRUE.equals(f.inStockOnly())) {
spec = spec.and(ProductSpecs.isInStock());
}
return repo.findAll(spec, pageable);
}
}
Why return null from specs?
Specification.where(null)produces a no-op specification — one that adds no predicate to the query. Chaining.and(null)similarly has no effect. This means your composition code stays linear, with no nested if-checks for each optional filter.
Spring Data 4.0: The New PredicateSpecification
Spring Data 2025.1 (Spring Data JPA 4.0), released alongside Spring Boot 4 and Spring Framework 7, introduced a refinement: PredicateSpecification<T>. The key difference from the classic Specification<T> is that PredicateSpecification is query-type-agnostic. The classic Specification receives a CriteriaQuery<?> argument, which ties the implementation to a specific query type and can cause issues when the same specification is reused in count queries, subqueries, or delete operations. PredicateSpecification removes that coupling entirely:
// Spring Data JPA 4.0+ (Spring Boot 4 / Jakarta EE 11 / JPA 3.2)
import org.springframework.data.jpa.domain.PredicateSpecification;
import jakarta.persistence.criteria.From;
import jakarta.persistence.criteria.CriteriaBuilder;
import jakarta.persistence.criteria.Predicate;
public class OrderSpecs {
// PredicateSpecification — no CriteriaQuery argument, fully query-agnostic
public static PredicateSpecification<Order> forCustomer(Long customerId) {
if (customerId == null) return null;
return (From<?, Order> from, CriteriaBuilder cb) ->
cb.equal(from.get("customerId"), customerId);
}
public static PredicateSpecification<Order> placedAfter(LocalDate date) {
if (date == null) return null;
return (from, cb) ->
cb.greaterThanOrEqualTo(from.get("placedAt"), date);
}
}
PredicateSpecification instances compose with the same .and() / .or() combinators as the classic interface, and can be passed wherever a Specification is accepted. In practice, for most new code written against Spring Data 4.0, PredicateSpecification is the preferred choice because it is safer to reuse across different query types — count queries, update/delete queries introduced in Spring Data 4.0, and future query forms — without risk of CriteriaQuery-specific side effects.
Spring Data 4.0 also introduced
UpdateSpecificationandDeleteSpecification— query-bound variants that work the same way for bulk update and delete operations through the repository. This means the same predicate logic you write for afindAllcan be reused in a bulk delete without rewriting the predicate from scratch.
Handling Joins in Specifications
Dynamic filters frequently cross association boundaries. A product search that filters by the supplier’s country, an order search that filters by the customer’s tier, an employee search that filters by department name — all of these require joining related entities. Specifications handle this naturally through the Root‘s join() method. The important production detail is distinguishing when to use join() versus fetch(), and managing duplicate results when joining collections.
public class EmployeeSpecs {
// Filter by department name via an INNER JOIN
public static Specification<Employee> inDepartment(String deptName) {
if (deptName == null) return null;
return (root, query, cb) -> {
// Avoid duplicate rows in count queries
if (Long.class != query.getResultType()) {
query.distinct(true);
}
Join<Employee, Department> dept = root.join("department", JoinType.INNER);
return cb.equal(dept.get("name"), deptName);
};
}
// Eagerly fetch the address in the same query (avoids N+1)
public static Specification<Employee> withAddress() {
return (root, query, cb) -> {
if (Long.class != query.getResultType()) {
root.fetch("address", JoinType.LEFT);
}
return cb.conjunction(); // no predicate — fetch only
};
}
}
N+1 and count query pitfall: When you call
root.fetch()inside a specification, the fetch must be guarded against count queries (wherequery.getResultType()isLong.class), because Hibernate cannot apply a fetch join to a count query and will throw. The check above is the standard idiom for this case.
Generic Search Criteria: One Builder for Any Entity
For applications with many searchable entities, repeating the specification pattern for each one becomes its own form of boilerplate. A generic search criteria approach solves this by representing a filter as a plain data object — a key, an operation, and a value — and delegating predicate construction to a reusable builder that works against any entity type.
// A search criterion: field + operation + value
public record SearchCriteria(String key, SearchOperation operation, Object value) {}
public enum SearchOperation {
EQUAL, NOT_EQUAL, LIKE, GREATER_THAN, LESS_THAN, IN
}
// A generic specification that applies one criterion to any entity
public class GenericSpecification<T> implements Specification<T> {
private final SearchCriteria criteria;
public GenericSpecification(SearchCriteria criteria) {
this.criteria = criteria;
}
@Override
public Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
return switch (criteria.operation()) {
case EQUAL -> cb.equal(root.get(criteria.key()), criteria.value());
case NOT_EQUAL -> cb.notEqual(root.get(criteria.key()), criteria.value());
case LIKE -> cb.like(cb.lower(root.get(criteria.key())),
"%" + criteria.value().toString().toLowerCase() + "%");
case GREATER_THAN -> cb.greaterThan(root.get(criteria.key()),
criteria.value().toString());
case LESS_THAN -> cb.lessThan(root.get(criteria.key()),
criteria.value().toString());
case IN -> root.get(criteria.key()).in((Collection<?>) criteria.value());
};
}
}
// A builder that accumulates criteria and produces a composite Specification
public class SpecificationBuilder<T> {
private final List<SearchCriteria> params = new ArrayList<>();
public SpecificationBuilder<T> with(String key, SearchOperation op, Object value) {
params.add(new SearchCriteria(key, op, value));
return this;
}
public Specification<T> build() {
if (params.isEmpty()) return Specification.where(null);
return params.stream()
.map(GenericSpecification<T>::new)
.reduce(Specification.where(null), Specification::and);
}
}
With this in place, a REST controller can accept a list of filter triples from the client, turn them into SearchCriteria objects, and pass the assembled specification directly to the repository — with no entity-specific code required in the builder itself. The pattern also maps naturally onto UI-driven search forms where the available fields and operators are dynamic.
Querydsl: Type-Safe Predicates Without String Field Names
The Specification approach, for all its flexibility, still refers to entity fields by string name — root.get("price"), root.get("category"). A typo in a field name is not caught at compile time. For teams that want full compile-time safety on field references, Querydsl is the answer.
Querydsl’s annotation processor generates a Q-class for each JPA entity — QProduct for Product, QOrder for Order, and so on. Each Q-class exposes the entity’s fields as typed path objects. Predicates are then written using a fluent API on those paths, with IDE autocompletion and compiler checking on every field access:
// Querydsl — type-safe predicates using generated Q-classes
// Repository must extend QuerydslPredicateExecutor
public interface ProductRepository
extends JpaRepository<Product, Long>,
JpaSpecificationExecutor<Product>,
QuerydslPredicateExecutor<Product> {}
// Usage in service
import com.example.entity.QProduct;
import com.querydsl.core.BooleanBuilder;
@Service
public class ProductQueryService {
private final ProductRepository repo;
public Iterable<Product> search(String keyword, Double maxPrice, String category) {
QProduct p = QProduct.product; // generated Q-class
BooleanBuilder builder = new BooleanBuilder();
if (keyword != null) builder.and(p.name.containsIgnoreCase(keyword));
if (maxPrice != null) builder.and(p.price.loe(maxPrice));
if (category != null) builder.and(p.category.eq(category));
return repo.findAll(builder);
}
}
Notice that p.name, p.price, and p.category are all strongly typed path objects — rename the field in the entity and the Q-class regenerates, making the compiler flag every use site that needs updating. This makes Querydsl particularly valuable in large codebases where field names change over time and manual audit is impractical.
The trade-off is build complexity: Querydsl requires an annotation processor in your Maven or Gradle build, and generating Q-classes adds a step to every clean build. Teams already using Lombok and MapStruct — which also require annotation processing — absorb this cost easily. Teams without existing annotation processing may find it harder to justify for simpler use cases.
Combining Dynamic Filters with Pagination and Sorting
Dynamic queries rarely appear without pagination. A search form that returns thousands of unfiltered records is a performance problem regardless of how elegantly the filter predicate was constructed. Fortunately, JpaSpecificationExecutor includes a findAll(Specification<T>, Pageable) overload that handles both simultaneously, and the returned Page<T> contains the total element count for rendering pagination controls on the client.
// REST controller wiring — filter + sort + page from query parameters
@RestController
@RequestMapping("/api/products")
public class ProductController {
private final ProductService productService;
// GET /api/products?category=books&keyword=spring&page=0&size=20&sort=price,asc
@GetMapping
public Page search(
@RequestParam(required = false) String category,
@RequestParam(required = false) String keyword,
@RequestParam(required = false) Double minPrice,
@RequestParam(required = false) Double maxPrice,
@RequestParam(defaultValue = "false") boolean inStockOnly,
Pageable pageable) { // Spring auto-populates from query params
ProductFilter filter = new ProductFilter(category, keyword, minPrice, maxPrice, inStockOnly);
return productService.search(filter, pageable);
}
}
Spring’s Pageable resolver automatically binds page, size, and sort query parameters to a Pageable instance. This means the controller needs no manual sorting logic — the caller sends sort=price,asc or sort=name,desc and the repository applies it to the filtered query without additional code. The combination delivers a fully dynamic, sortable, paginated search API from a handful of well-structured classes.
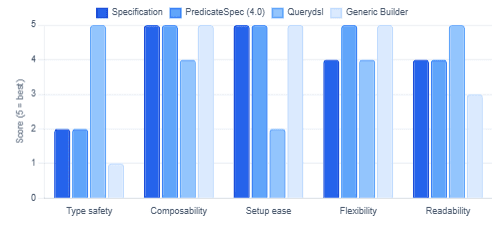
Choosing the Right Approach
Each dynamic querying strategy covered here has a different profile of simplicity, type safety, and flexibility. The table below maps the key trade-offs to help you pick the right tool for your context.
| Approach | Compile-time safety | Boilerplate | Reusability | Best for |
|---|---|---|---|---|
Specification<T> | Partial — strings for fields | Low | High — composable | Most REST filter APIs; Spring Boot 3 |
PredicateSpecification<T> | Partial — strings for fields | Low | High — query-agnostic | Spring Data 4.0+; reuse across find/count/delete |
Generic SpecificationBuilder | Runtime — field names as strings | Very low per entity | Very high — entity-agnostic | Table-driven or UI-driven filter APIs |
| Querydsl predicates | Full — Q-class paths | Medium — annotation processor setup | High — fluent composition | Large codebases; refactoring-heavy environments |
| Derived query methods | Full | Zero per method | None — one method per combination | Simple, fixed-filter repositories only |
Approach Comparison — Developer Experience Dimensions (scored 1–5)
Performance Considerations
Dynamic queries introduce a genuine performance consideration that static queries do not: because the query shape varies at runtime, the database cannot always reuse cached query plans as effectively. In practice, this matters most when specifications generate highly variable SQL — queries with dramatically different join counts or predicate structures. For typical search forms with a fixed set of optional filters, the variation is small enough that database plan caching remains effective.
The more common performance pitfall is the N+1 problem. When a specification triggers a join or when results include lazily-loaded associations that are accessed in the application layer, Hibernate issues one query per result row for those associations. The mitigation is to use root.fetch() inside the specification for associations that you know will be accessed, guarded against count queries as shown earlier. Alternatively, entity graphs can be applied on top of a specification query, giving you per-call control over which associations to fetch eagerly without baking it into the specification itself.
It is also worth ensuring that the columns most frequently used as filter predicates are properly indexed at the database level. A beautifully composed specification that generates a well-structured SQL query is still slow if the underlying table scan is unavoidable. Dynamic querying is not a substitute for thoughtful indexing — it is a complement to it.
| Practice | Why it matters |
|---|---|
Return null from spec factory when criterion is absent | Keeps composition linear; Specification.where(null) is a safe no-op |
Guard fetch() against count queries | Prevents Hibernate exception in paginated queries |
Prefer PredicateSpecification on Spring Data 4.0+ | Query-agnostic; safe to reuse in count, update, and delete operations |
Call query.distinct(true) when joining collections | Prevents duplicate result rows from one-to-many joins |
| Index columns used as filter predicates | Dynamic queries are not faster than the database index they rely on |
| Always paginate dynamic query results | Prevents full table scans from returning unbounded result sets |
What We Learned
Dynamic searching in Spring Data JPA is not a single feature — it is a toolkit with different tools suited to different needs. We started with the foundational Specification<T> interface, which wraps the JPA Criteria API into composable, reusable predicate objects that eliminate the need for a new repository method per filter combination. We then covered the new PredicateSpecification<T> introduced in Spring Data 4.0, which removes the coupling to a specific query type and makes predicates safe to reuse across count, update, and delete operations.
We built a generic SpecificationBuilder for table-driven search APIs where filter fields and operations arrive dynamically at runtime, and we examined Querydsl’s Q-class approach for teams that want full compile-time safety on field references. Finally, we wired everything together with Spring’s Pageable support for paginated, sortable results from a single controller endpoint. Understanding when to reach for each tool — and which performance pitfalls to avoid in each case — is what separates a search layer that scales gracefully from one that becomes a maintenance burden as requirements grow.
