Event Sourcing Without a Framework: What You Actually Need, What You Don’t, and the Parts Nobody Warns You About
Most Java tutorials reach for Axon before explaining the moving parts underneath it. This is the framework-agnostic treatment — the event store, the snapshot problem, schema evolution, replay, and the distinction between an event store and an event bus that most guides quietly skip.
A certain pattern repeats itself in Java teams discovering event sourcing for the first time. Someone reads the theory, gets excited, searches for a tutorial, and lands on Axon Framework. Within a day they have events flowing, aggregates rehydrating, and a sagas handling compensation. Everything feels clean. Then, six months later, the team hits a wall: they need to evolve an event schema, or replay a projection, or understand why a particular aggregate is slow to load — and they realise they do not actually know what the framework is doing for them. At that point, going back to first principles is genuinely hard.
This article is the first-principles treatment. We will build event sourcing in plain Java with no framework dependency beyond a JDBC connection and Jackson. More importantly, we will spend most of our time on the parts that are rarely covered: the non-obvious hard parts that only become obvious after something breaks in production.
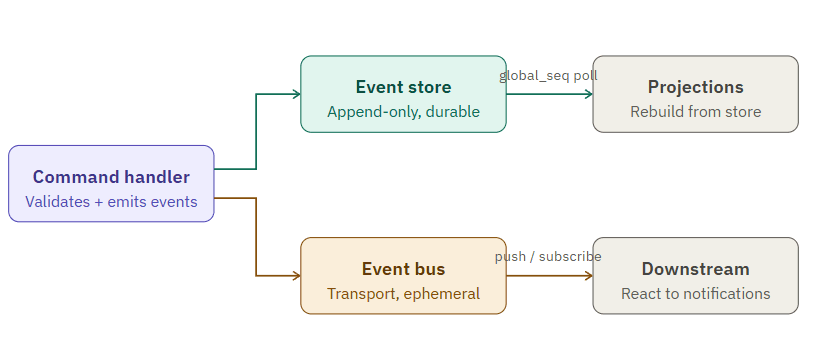
Start with the distinction almost everyone blurs: event store vs event bus
Before a single line of Java, it is worth getting this distinction crisp, because blurring it leads to architectural mistakes that are painful to undo later.
An event bus is a transport mechanism. It carries a message from a producer to one or more consumers right now. It is concerned with delivery, routing, and fan-out. Kafka, RabbitMQ, and even Spring’s internal ApplicationEventPublisher are all event bus concerns. An event bus is inherently ephemeral: once a message is consumed and acknowledged, it is either gone or archived for debugging. You would not rebuild the state of your domain by replaying a Kafka topic from the beginning in production — at least, not without significant ceremony.
An event store is a persistence mechanism. It is an append-only log of everything that has ever happened to every aggregate in your system. Its job is not delivery — it is authoritative storage. When you ask “what is the current state of order ord-4821?”, the event store gives you every event that has ever been applied to that aggregate, in order, from the beginning of time. You reconstruct the current state by replaying those events, not by querying a projection table.
“The event store is your source of truth. The event bus is your notification mechanism. A system that confuses the two will eventually find itself in the unenviable position of having lost history it thought it was persisting.”
In practice, the two often work together: when you append an event to the store, you also publish it to a bus for downstream consumers. But they must remain conceptually and physically separate. Your event store should never depend on your event bus being up. And your projections should be rebuildable from the event store alone, without the bus.
The minimal event store schema you actually need
An event store, at its core, is a single append-only table. Teams often over-engineer the schema on the first attempt. Here is what you genuinely need, plus the constraints that enforce the invariants you care about.
CREATE TABLE event_store (
global_sequence BIGSERIAL PRIMARY KEY,
stream_id VARCHAR(255) NOT NULL,
stream_version BIGINT NOT NULL,
event_type VARCHAR(255) NOT NULL,
payload JSONB NOT NULL,
metadata JSONB NOT NULL DEFAULT '{}',
occurred_at TIMESTAMPTZ NOT NULL DEFAULT now(),
UNIQUE (stream_id, stream_version)
);
CREATE INDEX idx_event_store_stream
ON event_store (stream_id, stream_version);
CREATE INDEX idx_event_store_global
ON event_store (global_sequence);
The UNIQUE (stream_id, stream_version) constraint is doing significant work here. It enforces optimistic concurrency at the database level: two concurrent writes to the same aggregate at the same version will result in one succeeding and one receiving a unique constraint violation, which your application layer translates into a concurrency exception and a retry. This is your primary concurrency guard, and it is far simpler and more reliable than application-level locking.
The global_sequence is a monotonically increasing integer across all streams. Projections use it to track their position — a projection records the last global_sequence it processed, and on restart it picks up from there. This is how you get reliable, resumable projection rebuilds without a message broker.
Gaps in sequences
PostgreSQL sequences can have gaps — for example, if a transaction is rolled back after the sequence advances. Consequently, your projection polling logic must never assume that all sequences between last_processed and max_seen exist. Query WHERE global_sequence > :last AND global_sequence <= :batch_max and handle gaps gracefully.
The Java event model: what you need and nothing more
The event model itself requires very little boilerplate in modern Java. A sealed interface for your domain events, records for the concrete types, and a simple envelope for serialisation are all you need to get started. Java records, available since Java 16 and stable since Java 17, are an excellent fit here because they are immutable by default and require no Lombok.
// The marker interface — all domain events implement this
public sealed interface DomainEvent permits
OrderPlaced, OrderShipped, OrderCancelled, PaymentReceived { }
// A concrete event — a plain Java record
public record OrderPlaced(
String orderId,
String customerId,
BigDecimal amount,
String currency,
Instant occurredAt
) implements DomainEvent { }
// The envelope written to and read from the event_store table
public record EventEnvelope(
long globalSequence,
String streamId,
long streamVersion,
String eventType,
String payloadJson,
String metadataJson,
Instant occurredAt
) { }
The EventRepository is, deliberately, a narrow interface. It has three methods: append a batch of events for a single stream, load all events for a stream, and load events from a given version onwards (used after a snapshot). That is the entire write and read API you need for the aggregate side of your system.
public interface EventRepository {
// Append events for a stream, enforcing optimistic concurrency.
// expectedVersion is the version of the last known event for this stream.
// Throws OptimisticConcurrencyException if the stream has moved on.
void append(String streamId, long expectedVersion,
List<DomainEvent> events);
// Load all events for a stream from the beginning.
List<EventEnvelope> loadStream(String streamId);
// Load events for a stream starting after a given version.
// Used when a snapshot is available.
List<EventEnvelope> loadStreamFrom(String streamId, long afterVersion);
}
Optimistic concurrency: the part that actually protects you
The append operation deserves close attention because getting it wrong leads to lost updates and corrupted aggregate state. The pattern is straightforward: before appending, you assert that the current maximum version for this stream equals the version you loaded. If another writer has appended in the meantime, the unique constraint fires.
// Simplified JDBC implementation of the append method
public void append(String streamId, long expectedVersion,
List<DomainEvent> newEvents) {
String sql = """
INSERT INTO event_store
(stream_id, stream_version, event_type, payload, occurred_at)
VALUES (?, ?, ?, ?::jsonb, ?)
""";
try (Connection conn = dataSource.getConnection()) {
conn.setAutoCommit(false);
try (PreparedStatement ps = conn.prepareStatement(sql)) {
long version = expectedVersion;
for (DomainEvent event : newEvents) {
version++;
ps.setString(1, streamId);
ps.setLong(2, version);
ps.setString(3, event.getClass().getSimpleName());
ps.setString(4, serializer.serialize(event));
ps.setObject(5, Instant.now());
ps.addBatch();
}
ps.executeBatch();
conn.commit();
} catch (SQLException ex) {
conn.rollback();
// PostgreSQL error code 23505 = unique_violation
if ("23505".equals(ex.getSQLState())) {
throw new OptimisticConcurrencyException(streamId, expectedVersion);
}
throw new EventStoreException("Append failed for stream: " + streamId, ex);
}
} catch (SQLException ex) {
throw new EventStoreException("Connection failure", ex);
}
}
This is the complete concurrency mechanism. There is no need for distributed locks, no need for a SELECT FOR UPDATE, and no need for a version column on your aggregate read model. The database unique constraint does the work, and it does it correctly under concurrent load.
Aggregate load time vs event count — with and without snapshots
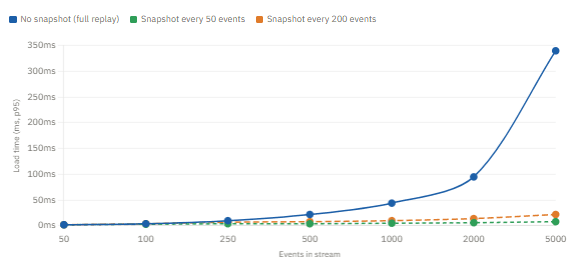
Snapshots: the right strategy, and the one nobody warns you about
The chart above makes the snapshot trade-off obvious: without snapshots, aggregate load time grows linearly with event count. Eventually, that becomes a real problem — not on day one, but reliably after an aggregate accumulates a few hundred events. The question is not whether to snapshot, but when and how.
The interval strategy
The simplest approach: after every N events appended to a stream, take a snapshot. Store the serialised aggregate state alongside the stream version at which the snapshot was taken. On the next load, check for the most recent snapshot first, load aggregate state from it, and then replay only the events appended after that version.
CREATE TABLE snapshots ( stream_id VARCHAR(255) NOT NULL, stream_version BIGINT NOT NULL, payload JSONB NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), PRIMARY KEY (stream_id, stream_version) );
// Loading an aggregate with snapshot support
public Order loadOrder(String orderId) {
Optional<Snapshot> snap = snapshotRepository.findLatest(orderId);
List<EventEnvelope> events = snap
.map(s -> eventRepository.loadStreamFrom(orderId, s.streamVersion()))
.orElseGet(() -> eventRepository.loadStream(orderId));
Order order = snap
.map(s -> deserializer.deserialize(s.payload(), Order.class))
.orElseGet(Order::empty);
events.forEach(env -> order.apply(deserializer.deserialize(env)));
return order;
}
The part nobody warns you about: snapshot invalidation after schema changes
Here is the problem. You take a snapshot of an aggregate at version 150. Three months later, you add a new field to the aggregate’s Java class. The snapshot at version 150 was serialised without that field. When you deserialise it now, Jackson either throws an UnrecognizedPropertyException or silently populates the new field with null. Neither outcome is what you want.
The solution is to version your snapshots independently. Store a snapshot_schema_version alongside each snapshot. When you change the aggregate structure, increment the schema version. Your snapshot loader checks the schema version before using a snapshot: if the version does not match the current schema, it falls back to a full replay from the event store. This is slower, but it is correct.
The snapshot invalidation trap
Never silently accept a deserialization failure from a snapshot and fall back to full replay without logging a warning. If your snapshots are silently invalid in production, you will not notice until aggregate load times start climbing — and by then, the root cause may be non-obvious.
Schema evolution of events: the four strategies
This is the section that frameworks tend to abstract away, and consequently the section most developers have never thought through carefully. Events are immutable once written, but the classes that represent them in your codebase are not. At some point, you will need to change what an event looks like. There are four recognised strategies, each with different trade-offs.
| Strategy | Description | Backward compatibility | Operational cost | Best for |
|---|---|---|---|---|
| Weak schema | Accept unknown fields, use defaults for missing ones. Jackson’s @JsonIgnoreProperties(ignoreUnknown=true). | High | Low | Additive changes: new optional fields |
| Event versioning | Write OrderPlacedV2 as a new type. Keep reading both in the aggregate apply() method. | High | Medium | Structural changes that preserve both old and new semantics |
| Upcasting | A pipeline of transformers converts old event JSON to the current structure before deserialisation. | High | Medium | When you want a single event class but need to read old payloads |
| In-place migration | A migration script rewrites old events in the store to the new format. | Destructive | High | Only when the old format is genuinely unusable and you have full control of all replaying code |
In practice, the first two strategies handle 90% of real-world cases. The weak schema approach costs you nothing in most additive scenarios. Event versioning is verbose but explicit — you can grep your codebase for all places that handle OrderPlacedV1 and know exactly what you are supporting.
Upcasting is the most powerful pattern and the one most worth understanding in detail. The core idea: instead of keeping old Java classes around forever, you write a chain of pure functions that transform raw JSON. Each function takes the JSON of a specific event version and returns the JSON of the next version. At deserialisation time, you run the chain before handing the JSON to Jackson.
// A simple upcaster chain for OrderPlaced schema evolution
public interface Upcaster {
String eventType();
int fromVersion();
JsonNode upcast(JsonNode oldPayload);
}
// Upcast OrderPlaced from schema v1 (no currency field)
// to schema v2 (currency field added, defaulting to "USD")
public class OrderPlacedV1ToV2 implements Upcaster {
@Override public String eventType() { return "OrderPlaced"; }
@Override public int fromVersion() { return 1; }
@Override
public JsonNode upcast(JsonNode v1) {
ObjectNode v2 = v1.deepCopy();
if (!v2.has("currency")) {
v2.put("currency", "USD"); // safe default for legacy events
}
return v2;
}
}
// The chain runs all upcasters in version order before deserialisation
public class UpcasterChain {
private final Map<String, List<Upcaster>> byType;
public JsonNode upcast(String eventType, int storedVersion, JsonNode payload) {
List<Upcaster> chain = byType.getOrDefault(eventType, List.of());
JsonNode current = payload;
for (Upcaster u : chain) {
if (u.fromVersion() >= storedVersion) {
current = u.upcast(current);
}
}
return current;
}
}
Replay performance: what actually makes it slow
When you need to rebuild a projection from scratch — whether because you introduced a bug in the projection logic or because you are adding a new read model — you will replay every event in the store in global_sequence order. In a mature system, that might be tens of millions of events. The naive implementation does this slowly, and the reasons are worth understanding.
Projection replay throughput — events per second by approach
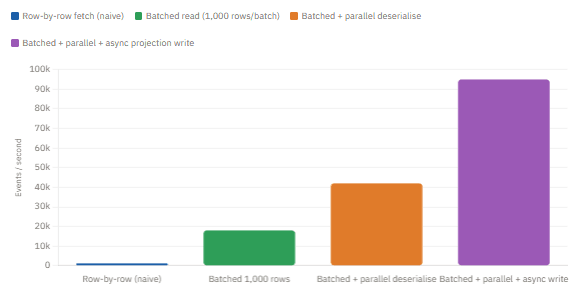
Several factors account for the 80× difference between the naive approach and the optimised one. First and most significantly, row-by-row fetches generate one round-trip per event. Use setFetchSize() on your JDBC statement to enable cursor-based streaming, and process events in batches. Second, deserialisation of JSON is CPU-bound and embarrassingly parallel — use a ForkJoinPool or Java 21 virtual threads to process batches concurrently. Third, if your projection writes go to a database, batching those writes provides another large multiplier.
Additionally, if you run multiple projections simultaneously, consider whether they can share the single-pass read from the event store. Reading 10 million events once and fanning them out to 5 projections in memory is far faster than reading 10 million events 5 times.
On catch-up subscriptions
A catch-up subscription is the mechanism a projection uses to stay current without polling. The projection stores its last processed global_sequence. A background thread periodically queries for new events above that position and feeds them to the projection handler. This is simpler than a Kafka consumer group, does not require a message broker, and is easy to make reliable with a simple retry loop. For most systems, it is all you need.
What you actually do not need
It is worth being direct about what this approach does not give you, and why that is often fine rather than a limitation.
| Feature | Framework provides | Do you need it? | DIY cost if you do |
|---|---|---|---|
| Saga orchestration | Axon’s @Saga, step tracking, compensation | Only for multi-aggregate transactions | Medium — a saga state table + handler, ~200 lines |
| Distributed command routing | Axon Server routes commands to correct aggregate instance | Only in multi-node deployments with sharding | High — use Kafka or consistent hashing |
| Dead-letter queue for projections | Built-in replay and error isolation | Yes, in production | Low — a failed_events table + admin tool |
| Projection registry and lifecycle | Automatic tracking of all projections | Helpful but not essential | Low — a projection_checkpoints table |
| Event serialiser / deserialiser | XStream, Jackson, custom | Always | Very low — Jackson with the upcaster chain above |
The key insight from this table is that the most valuable parts of a framework are the parts that address genuinely hard distributed systems problems: cross-aggregate coordination, reliable delivery in a multi-node environment, and failure isolation at the projection level. If your system does not have those problems yet, you are paying a framework’s cognitive overhead for features you are not using.
When to reach for a framework
The framework answer becomes attractive when: you have multiple services coordinating via sagas; you need to shard command processing across nodes; or your team is new to event sourcing and wants guardrails. None of those are true for most teams starting out. Build the simple version first, and the places where you feel its absence will tell you exactly which framework features are worth the dependency.
The projection checkpoint table: a detail that matters
Before closing, there is one small detail that prevents a large class of production incidents: the projection checkpoint. Every projection must durably record its position in the event stream. Without this, a process restart replays the entire history every time — which is expensive at best and causes duplicate side effects at worst.
CREATE TABLE projection_checkpoints ( projection_name VARCHAR(255) PRIMARY KEY, last_sequence BIGINT NOT NULL DEFAULT 0, updated_at TIMESTAMPTZ NOT NULL DEFAULT now() );
The checkpoint update should happen in the same database transaction as the projection’s write. If your projection writes to the same PostgreSQL instance as your event store, this is straightforward. If it writes to a separate store — say, Elasticsearch — you need to decide whether you are willing to accept at-least-once delivery (checkpoint after write, accept idempotent handlers) or prefer at-most-once (checkpoint before write, accept occasional missed events). For most business projections, idempotent at-least-once delivery is the pragmatic choice. Make your projection handlers idempotent by checking whether the event’s global_sequence has already been processed before applying it.
What we have learned
- An event store is a persistence mechanism — an append-only log of everything that happened. An event bus is a delivery mechanism. Keeping them separate means your source of truth never depends on a broker being available.
- A single append-only PostgreSQL table with a
UNIQUE (stream_id, stream_version)constraint gives you a fully functional event store with optimistic concurrency at the database level, no application-level locking required. - Aggregate load time grows linearly with event count without snapshots. Snapshots every 50–200 events flatten this curve dramatically. But snapshot schema versioning is essential — a snapshot written before a schema change must be invalidated, not silently misread.
- Schema evolution of events has four strategies: weak schema (additive changes), event versioning (new types in parallel), upcasting (JSON transform chain), and in-place migration (destructive, use rarely). The first two cover most real-world cases; upcasting handles the rest cleanly.
- Replay throughput improves by 80× or more when you move from row-by-row JDBC fetches to batched reads with parallel deserialisation. A catch-up subscription based on
global_sequencepolling is all you need for live projection updates without a message broker. - Frameworks like Axon earn their place for distributed sagas and multi-node command routing. For a single-node or single-service deployment, the framework’s overhead often exceeds its benefit. Know what it does before you add it.
