Domain-Driven Design Was Written for a World Without LLMs — What Happens to the Ubiquitous Language When the Model Speaks It Better Than Your Team Does?
Eric Evans gave us the Ubiquitous Language as the hardest artifact a team can build. Large language models now absorb it in minutes. That is not a productivity win — it is a philosophical challenge.
There is a conversation happening in senior engineering teams that rarely makes it to conference slides. It goes something like this: a new engineer joins, gets handed the domain documentation, and within an afternoon is already asking the same questions that took their predecessor three months to formulate. Not because the documentation improved. Because they fed it to a large language model and the model came back speaking fluent insurance, healthcare, or logistics domain language — whichever the team happens to work in.
That shift is quietly unsettling for anyone who has spent serious time with Domain-Driven Design. The reason it matters has nothing to do with tooling. It cuts right to the philosophical bedrock of the methodology.
The Original Promise of the Ubiquitous Language
When Eric Evans published Domain-Driven Design: Tackling Complexity in the Heart of Software in 2003, the central provocation was this: the most dangerous thing in a software project is not bad technology. It is the translation loss between what a domain expert knows and what an engineer builds. Every time a concept crosses the boundary from domain to code — through requirements documents, meetings, and tribal memory — something is lost or distorted.
The Ubiquitous Language was Evans’ answer. A shared, rigorous vocabulary that lives simultaneously in the mouths of domain experts, in the conversations between teams, and in the code itself. Not a glossary pinned to a wall, but a living model refined through constant dialogue. The transfer of that language to new team members was understood to be slow, expensive, and irreplaceable. That difficulty was, in a sense, the point. Teams that had done the hard work of building a precise shared vocabulary had a genuine competitive advantage, because their models actually reflected the domain.
“The Ubiquitous Language is not documentation about the domain. It is the alignment mechanism between domain knowledge and the code that models it. That distinction is crucial — and it is exactly what LLMs are now challenging.”
Bounded contexts emerged as a direct consequence of this idea. When two teams used the same word to mean different things, Evans argued you should not try to force a single model — you should draw an explicit boundary, name the context, and translate at the seam. The Bounded Context was, at its root, a solution to the limits of human language alignment at scale.
What Changes When a Model Speaks Domain Fluently
Consider what a modern LLM actually does when you hand it your domain documentation, your event storming diagrams, your ADRs, and your existing codebase. Within a single context window, it can hold a richer cross-section of your domain model than most individual engineers carry in their heads after years of work. It will surface relationships between domain concepts that a new engineer would take months to infer. It will flag when your code uses “account” to mean two different things in two different aggregates — not because it understands your business, but because it is extraordinarily good at detecting lexical inconsistency across a large corpus.
Furthermore, it does this without the social overhead that makes domain alignment genuinely difficult in practice. There are no misremembered meetings, no silos formed after a re-org, no junior developer who was afraid to ask what “settlement” means in this particular context. The model does not get tired, does not hold onto the 2019 model when the domain shifted in 2022, and does not confuse the marketing team’s definition with the engineering team’s.
Worth noting
This is not the same as saying LLMs understand the domain. They do not. But they are remarkably good at two things that DDD treats as expensive human skills: detecting language inconsistency and mediating between natural language and structured code. Those are, in fact, the two core problems the Ubiquitous Language was designed to solve.
A Quick Look at How Teams Are Already Using This
Before we get philosophical, it is worth grounding this in what is actually happening in practice. The table below summarises some of the ways teams are already using LLMs in a DDD workflow, along with a realistic assessment of what they replace and what they do not.
| DDD Activity | Traditional approach | LLM-assisted equivalent | What survives human work? |
|---|---|---|---|
| Knowledge transfer to new engineers | Months of pair programming and domain workshops | Context-window loading of docs + interactive Q&A | Tacit knowledge, edge-case nuance, political context |
| Ubiquitous Language audit | Manual review of code against glossary | LLM cross-references code, docs, and conversations for lexical drift | Intentional ambiguity decisions still require humans |
| Event Storming facilitation | Physical or virtual workshops, domain expert present | LLM can generate a draft domain model and flag missing events | Domain expert validation; model can hallucinate domain constraints |
| Bounded context mapping | Drawn manually, documented in ADRs | LLM can propose context boundaries from existing codebase | Organisational politics, team topology, and Conway’s Law remain human concerns |
| Anti-corruption layer design | Designed explicitly when contexts meet | LLM can generate translation code with context from both sides | Semantic ownership decisions cannot be delegated |
What you notice immediately is that LLMs are competent at the mechanical layers of DDD — the parts that involve pattern matching, lexical consistency, and structural alignment. They are far less reliable on the parts that involve actual domain knowledge: understanding why a particular model reflects a real-world constraint, or why two seemingly identical concepts need to stay separate because the business treats them differently.
Estimated weeks before a new engineer can independently work on domain-level code (illustrative data based on practitioner surveys, 2023–2024)
Time to Productive Domain Contribution — New Engineers
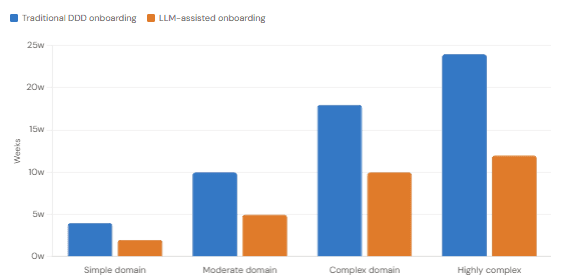
Does This Change What the Ubiquitous Language Is For?
Here is the genuinely unsettling question: if a model can absorb your domain documentation and converse fluently in your domain language, what is the Ubiquitous Language actually doing in your organisation?
Evans’ original answer was twofold. First, the language aligns understanding between domain experts and engineers so that the model in the code accurately reflects reality. Second — and this is the part that often gets overlooked in tactical DDD discussions — the process of building that language is itself a form of knowledge discovery. When a business analyst and a software engineer argue about what “invoice” means, they are not wasting time on semantics. They are discovering a genuine ambiguity in how the business works, and that discovery has real consequences for the software.
LLMs challenge the first function quite directly. If the model can mediate the language gap more cheaply than a human DSL and a team of domain-literate engineers, then the practical case for investing in the Ubiquitous Language as an alignment tool weakens. However, they do not challenge the second function at all. An LLM that finds a lexical inconsistency in your codebase does not tell you whether the inconsistency reflects genuine domain complexity or just sloppy naming. That judgement requires a human who understands the business.
The key insight
The Ubiquitous Language may be evolving from an alignment mechanism — its original role — into a quality signal. A well-maintained domain language is now less valuable as a way to bridge the gap between domain experts and engineers, and more valuable as evidence that the team has done the hard epistemological work of truly understanding the domain.
The Risk of Fluent-But-Shallow Domain Models
There is a failure mode worth naming explicitly. LLMs are extraordinarily good at producing language that sounds domain-correct. Given your documentation, they will write aggregates that use your terminology, generate event names that feel familiar, and propose bounded context boundaries that look plausible. This fluency can mask a fundamental shallowness.
A domain model is not correct because it uses the right words. It is correct because its structure reflects genuine constraints and invariants in the real world. A model where “order” and “quote” are the same aggregate might be linguistically consistent but semantically broken, if in your domain a quote can be revised after submission while an order cannot. That distinction only surfaces through deep conversations with domain experts — not through pattern matching on documentation.
The risk, in short, is that teams use LLMs to produce a domain model faster without doing the slow, iterative work that makes the model accurate. This is not a problem with LLMs per se. It is a problem with how humans tend to treat fluency as a proxy for understanding. Consequently, the disciplines that DDD places around domain workshops, context mapping, and explicit aggregate design become more important in an LLM-assisted workflow, not less — because there is now a capable tool that can generate plausible-looking wrong answers at speed.
Expert practitioner ratings of LLM usefulness across DDD activities (1 = low value, 5 = high value). Based on DDD community practitioner feedback, 2024.
Where LLMs Add the Most — and Least — Value in a DDD Workflow
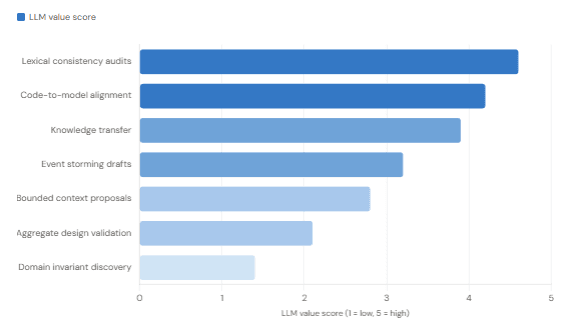
Re-examining Bounded Contexts in a World of AI Mediators
The Bounded Context was, at its heart, a concession to cognitive and organisational limits. Two teams cannot share a single model indefinitely as the domain grows, so you draw a boundary and accept that “customer” means something different on each side, with an explicit translation layer at the seam. The Context Map was the tool for documenting those translation decisions and the relationships between bounded contexts.
LLMs can, in principle, reduce the cost of translation at context seams. Given the models on both sides of a boundary, they can propose Anti-Corruption Layer mappings, flag when upstream changes will break downstream assumptions, and even generate the translation code itself. This is genuinely useful. However, it does not dissolve the need for the conceptual boundary.
The reason bounded contexts exist is not primarily a communication problem — it is a model ownership problem. The reason “customer” means something different in the billing context versus the logistics context is that the billing team and the logistics team have different responsibilities, different invariants to protect, and different rates of change. Those organisational realities do not disappear because a language model can translate between them. If anything, having a cheap translation mechanism makes it easier to tolerate imprecise boundaries, which is a long-term architectural risk.
“A cheap translation mechanism at a context seam does not mean the boundary is drawn correctly. It might just mean the cost of drawing it wrongly is temporarily hidden.”
A Practical Heuristic for LLM-Augmented DDD Teams
Rather than pretending this shift is not happening or treating LLMs as a simple accelerant, the following table offers a more nuanced framing. It distinguishes between activities where you should lean into LLM assistance, activities where you should use LLMs critically, and activities where you should protect the human process.
| Activity | Recommended stance | Reasoning |
|---|---|---|
| Language consistency audits | Lean in — LLMs are strong here | Lexical drift detection across large codebases is exactly what LLMs do well |
| New engineer onboarding | Lean in, with caveats | Speeds ramp-up significantly; supplement with human sessions on tacit knowledge |
| First-draft event storming | Use critically | Useful for generating hypotheses; always validate with a domain expert before committing |
| Bounded context boundary proposals | Use critically | LLMs see structural patterns but not team topology or organisational politics |
| Aggregate design and invariant definition | Protect human process | Aggregate invariants encode domain rules; these require domain expert validation, not just language fluency |
| Domain expert interview facilitation | Protect human process | The knowledge discovery function of DDD requires genuine dialogue; cannot be outsourced to a model |
An Example Worth Considering: the Anti-Corruption Layer as LLM Task
One area where LLMs already show genuine practical value is Anti-Corruption Layer (ACL) generation. The ACL exists at the boundary between two bounded contexts that have incompatible models. Traditionally, writing it involves a developer deeply understanding both models and writing translation logic that is tedious, error-prone, and rarely tested well.
Given good documentation of both bounded contexts, an LLM can draft a plausible ACL with reasonable coverage. Here is a simplified illustration of the kind of prompt structure that tends to work well in practice:
# Example: prompting an LLM to draft an ACL between two bounded contexts
# This assumes you have documented both contexts as plain text.
# Adjust model and file names for your environment.
export UPSTREAM_CONTEXT="./docs/billing-context.md"
export DOWNSTREAM_CONTEXT="./docs/logistics-context.md"
export OUTPUT="./src/acl/billing-to-logistics-translator.ts"
# Requires: curl, jq, an ANTHROPIC_API_KEY environment variable
# Works with: bash, zsh on macOS/Linux
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d "{
\"model\": \"claude-opus-4-5\",
\"max_tokens\": 2048,
\"messages\": [{
\"role\": \"user\",
\"content\": \"Given the following two bounded context glossaries, generate a TypeScript Anti-Corruption Layer class that translates entities from the Billing context to the Logistics context. Billing context: $(cat $UPSTREAM_CONTEXT). Logistics context: $(cat $DOWNSTREAM_CONTEXT). Include TypeScript types and a bidirectional translate method.\"
}]
}" \
| jq -r '.content[0].text' > $OUTPUT
echo "ACL draft written to $OUTPUT — review before committing."
The output will be syntactically coherent and terminologically consistent with your documentation. What it will not catch: semantic mismatches that are not visible in the written model, business rules that live in people’s heads rather than in documentation, and edge cases that only appear in production. The point is not that the LLM replaces the ACL design process. It is that it makes the mechanical part of that process dramatically cheaper, freeing human attention for the genuinely hard parts.
What the Strategic Question Actually Is
The tactical DDD community — aggregates, repositories, domain events, bounded contexts as implementation concerns — is largely unaffected by LLMs. Those patterns remain useful regardless of how we think about language alignment. What does change is the strategic question at the heart of DDD as a methodology.
Evans’ core argument was: invest heavily in building a shared domain language, because that investment pays compound returns over the life of the system. The language slows down initial development but creates an alignment substrate that makes every subsequent change cheaper and safer. The implicit assumption was that this investment is necessary because the alternative — building without a shared language — leads to model drift and cognitive fragmentation.
LLMs introduce a third option: build with a shared language, but let a model maintain and mediate it, rather than relying on the slow, expensive human process of alignment through dialogue. That option is genuinely attractive. It is also, arguably, architecturally fragile in ways we do not fully understand yet. A language model is a statistical reflection of your documentation, not a participant in the ongoing knowledge discovery process that gives DDD its real power.
The reframing
The Ubiquitous Language should now be understood as having two layers: a surface layer — consistent terminology across code, docs, and conversations — and a deep layer — the team’s collective understanding of why the model is structured the way it is. LLMs can do most of the work of the surface layer. The deep layer remains irreducibly human, and it is, if anything, now more important to protect deliberately because there is a seductive tool that can make the surface layer look healthy even when the deep layer is hollow.
What We Have Learned
- Eric Evans’ Ubiquitous Language was designed to solve the translation cost between domain experts and engineers. LLMs reduce that cost dramatically — but they do so by pattern-matching on existing documentation, not by doing the underlying knowledge discovery work.
- LLMs add the most value in the mechanical layers of DDD: lexical consistency audits, knowledge transfer acceleration, Anti-Corruption Layer drafting, and first-pass event storming. They add the least value in aggregate design, invariant definition, and domain expert facilitation — precisely the activities where getting things wrong is most costly.
- Bounded contexts exist because of organisational and model-ownership realities, not primarily because of communication costs. LLMs do not dissolve those realities; they make it cheaper to tolerate imprecise boundaries, which is a long-term risk rather than a benefit.
- The danger of fluent-but-shallow domain models is real. An LLM can produce a model that sounds right and looks right but encodes incorrect domain constraints, because it is optimising for linguistic consistency rather than domain accuracy.
- The most productive reframing is to think of the Ubiquitous Language as having a surface layer (LLMs can maintain this) and a deep layer (the team’s understanding of why the model looks the way it does — this remains human work). Protecting the deep layer is now a deliberate architectural discipline, not an automatic outcome of the DDD process.
