Beyond CAP: Why the PACELC Model Is a Better Framework for Database Decisions in 2026
CAP is one of the most cited and most misunderstood results in distributed systems. Daniel Abadi’s PACELC model extends it by revealing the tradeoff that CAP completely ignores: even when your network is healthy and there is no partition in sight, replication still forces you to choose between latency and consistency. This is the tradeoff that actually governs your system on a normal Tuesday.
1. What CAP Actually Says
The CAP theorem, originally proposed by Eric Brewer in a 2000 keynote and formally proved by Gilbert and Lynch in 2002, states that a distributed system cannot simultaneously guarantee all three of the following properties when a network partition occurs:
| Property | Definition (as CAP uses it) | What it means in practice |
|---|---|---|
| Consistency (C) | Every read receives the most recent write or an error — specifically linearizability | All nodes always agree on the current value |
| Availability (A) | Every request receives a non-error response — but it may not contain the most recent data | The system never refuses to answer |
| Partition Tolerance (P) | The system continues to operate despite an arbitrary number of messages being dropped between nodes | The system survives network splits |
Because network partitions are inevitable in any real distributed system — hardware fails, routers misbehave, cloud availability zones lose connectivity — partition tolerance is not actually a choice. You must design for it. That reduces CAP to a single binary decision: when a partition occurs, do you sacrifice consistency or availability?
In the NoSQL boom of the late 2000s, the answer was almost always “sacrifice consistency” — and CAP was the justification. Systems like Cassandra, Dynamo, and Riak were proudly labelled “AP” databases. This was, in retrospect, both correct and deeply misleading.
2. Three Things CAP Gets Wrong
By the mid-2010s, a number of serious criticisms of CAP had accumulated. Notably, Martin Kleppmann — the author of Designing Data-Intensive Applications — published a detailed critique in 2015 that identified several fundamental problems with how CAP is used in practice. It is worth going through the most important ones, because understanding them is precisely what makes PACELC feel necessary rather than academic.
Problem 1: CAP uses a narrow, oversimplified model
As Kleppmann pointed out, the CAP theorem was formally proved for a very specific model: a single read-write register. It says nothing about transactions that touch multiple objects, and it considers only one type of fault — a complete network partition where nodes are up but cannot communicate. It ignores node crashes, disk failures, software bugs, and slow networks that are not quite partitioned. In other words, CAP’s formal scope is much narrower than the way it is typically applied.
Problem 2: The “CA” category is a fiction
You will still encounter databases described as “CA” — consistent and available, sacrificing partition tolerance. As Kleppmann and others have noted, this is essentially meaningless. Any system that runs on more than one machine must handle network failures, full stop. A “CA” system is simply a system that has not yet experienced a partition and has not thought carefully about what happens when it does.
Problem 3: CAP treats its properties as binary when they are not
Consistency in the real world is not a single thing. There is linearizability (the strongest model, what CAP uses), sequential consistency, causal consistency, read-your-writes consistency, and eventual consistency — a whole spectrum with very different performance and correctness implications. CAP collapses all of this into “consistent or not.” Similarly, availability in CAP means “every single node responds to every request,” which no real system guarantees. Real availability is measured by SLAs — 99.9%, 99.99% — which CAP cannot express.
“The CAP theorem is too simplistic and too widely misunderstood to be of much use for characterising systems. We should use more precise terminology to reason about our tradeoffs.”— Martin Kleppmann, “Please Stop Calling Databases CP or AP” (2015)
Most importantly, however, CAP only addresses system behaviour during a partition. And as Daniel Abadi observed in 2010, partitions are relatively rare. The tradeoff that governs daily system behaviour — the one you cannot escape even on a perfectly healthy network — is something CAP does not model at all.
3. The Hidden Tradeoff CAP Ignores
Here is the core observation that motivates PACELC: as soon as a distributed system replicates data, a tradeoff between consistency and latency arises — regardless of whether any partition is occurring.
To see why, consider a straightforward write to a database with two replicas in different data centres. You have three options:
| Replication Strategy | Latency | Consistency | What Actually Happens |
|---|---|---|---|
| Synchronous (write to both before ACK) | High — must wait for cross-DC round trip (~100ms+ on WAN) | Strong — both replicas agree immediately | Client waits for the far replica to confirm. Consistent, but slow. |
| Asynchronous (write to one, replicate later) | Low — client gets ACK from local replica in ~1ms | Eventual — second replica will catch up eventually | Client returns fast. A crash before replication means the second replica is behind. |
| Quorum (write to majority) | Medium — must wait for a quorum of replicas | Tunable — depends on read/write quorum size | Cassandra’s default: consistency level controls the tradeoff at query time. |
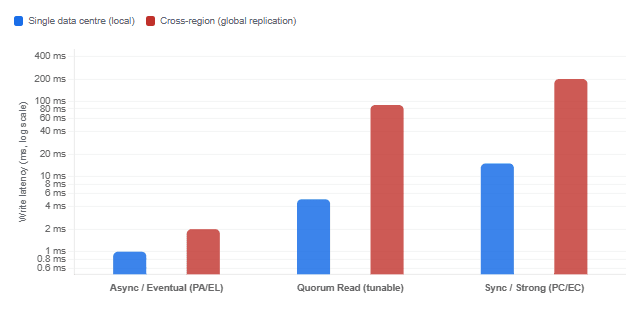
Notice that there is no partition anywhere in that analysis. The network is perfectly healthy. Yet you are still forced to choose. As Abadi argued — and as Kleppmann independently observed in his latency-delay framework — the reason so many production systems choose eventual consistency is not primarily because they are afraid of partitions. It is because synchronous replication adds latency that users feel on every single request. In practice, as Abadi stated directly in a 2024 interview, “consistency requires coordination. You have to have two different locations communicate with each other to be able to remain consistent. Consistency just takes time.”
The Core Insight
CAP explains what you sacrifice during a crisis (a partition). PACELC explains what you sacrifice every single day. For most systems, the second question matters far more — because partitions happen rarely, while every user request is subject to the latency-consistency tradeoff.
4. Enter PACELC: The Complete Picture
Daniel Abadi, then at Yale University (now the Darnell-Kanal Professor of Computer Science at the University of Maryland), first described the PACELC framework in a 2010 blog post and formalised it in a widely-cited 2012 paper titled “Consistency Tradeoffs in Modern Distributed Database System Design.”
PACELC is pronounced “pass-elk”. The acronym captures two separate operating modes for any distributed system:
The PACELC Statement
If there is a Partition (P): the system must choose between Availability (A) and Consistency (C) — just as CAP says.
Else (E) — when the system is running normally with no partition — the system must choose between Latency (L) and Consistency (C).
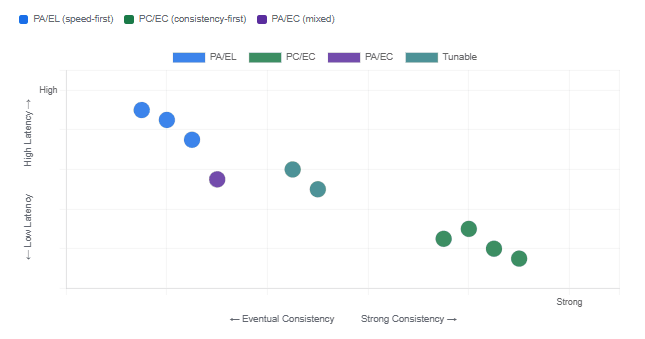
The result is a two-part classification for every distributed database. Instead of the single CP/AP label that CAP forces, PACELC gives you a pair: PA/EL, PC/EC, PA/EC, or PC/EL. Each combination tells you something meaningful about both the normal operating mode and the failure mode of the system.
Critically, Abadi argued that the Else (E) part of PACELC is the more important half in practice, because normal operation is vastly more common than partitioned operation. Systems that choose eventual consistency to avoid coordination overhead are primarily making an Else-Latency (EL) choice, not primarily a partition-driven Availability (PA) choice — even if they have historically justified it with CAP.
5. The Four PACELC Quadrants Explained
| PACELC Label | Partition Behaviour | Normal-Operation Behaviour | Tradeoff Summary |
|---|---|---|---|
PA/EL | Stay available; accept stale reads | Prioritise low latency; accept stale reads | Speed above all. Consistency sacrificed in both modes. |
PC/EC | Stay consistent; may reject requests | Prioritise consistency; accept higher latency | Correctness above all. Latency cost paid in both modes. |
PA/EC | Stay available during a partition | Enforce strong consistency when healthy | Splits the two modes. Uncommon and complex to reason about. |
PC/EL | Stay consistent during a partition | Prioritise low latency when healthy | Abadi argues this combination has no compelling motivation — rare in practice. |
Of these four, PA/EL and PC/EC are by far the most common in production systems, and for good reason. They are coherent end-to-end philosophies that a developer can reason about consistently. A PA/EL system always prioritises speed and availability; a PC/EC system always prioritises correctness. The mixed configurations (PA/EC and PC/EL) require developers to track which operating mode the system is in at any given time, which adds significant cognitive overhead.
Developer Experience Note
PC/EC and PA/EL are the natural cognitive models. When you write a query against Cassandra, you know you might get slightly stale data — always. When you write against CockroachDB, you know the write is globally ordered — always. Mixed configurations like PA/EC require you to check which mode the system is currently in, which makes application-layer reasoning significantly harder.
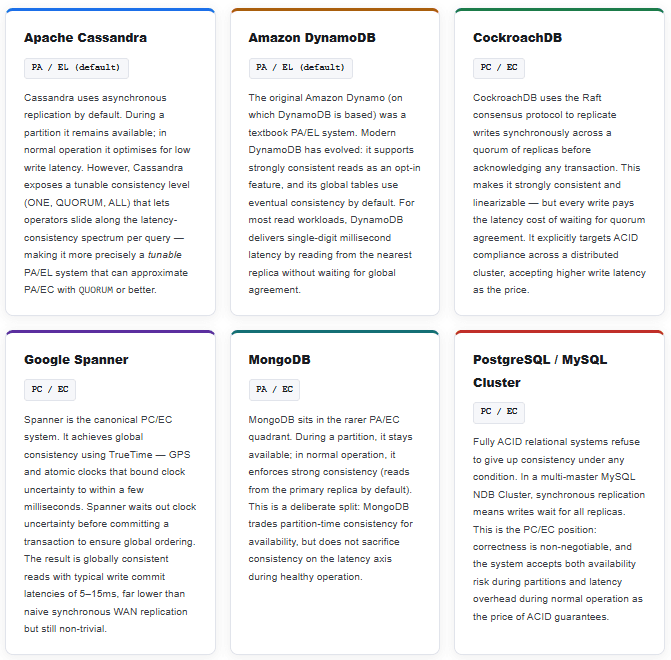
6. Real Databases Mapped to PACELC
With the quadrant model in hand, it becomes possible to precisely characterise the design philosophy of every major distributed database. The following cards reflect the classifications from Abadi’s original 2012 paper, updated where systems have evolved since then.
A note on Azure Cosmos DB
Cosmos DB deserves special mention because it does not fit neatly into any single quadrant — and that is by design. It exposes five selectable consistency levels: Strong, Bounded Staleness, Session, Consistent Prefix, and Eventual. Users choose where they want to sit on both the partition and normal-operation axes. At the “Strong” level it is PC/EC; at “Eventual” it is PA/EL. As Wikipedia’s PACELC entry notes, Cosmos DB “never violates the specified consistency level,” which makes it formally CP — but its tunable model means different workloads within the same database can occupy different PACELC positions simultaneously.
7. Latency vs. Consistency: The Numbers
The abstract tradeoff becomes much more concrete when expressed in terms of typical operational numbers. The charts below show two important dimensions: how each database class maps to the PACELC quadrant space, and the real-world latency cost of moving from eventual to strong consistency.
PACELC Quadrant Positioning of Major Databases
Typical Write Latency by Replication Strategy (Single Data Centre vs. Cross-Region)
8. Using PACELC for Real Architecture Decisions
The value of PACELC is not that it tells you which database to pick. Rather, it gives you a precise vocabulary for the question you should be asking before you evaluate any database: “What does this workload require in both the normal case and the failure case?” Framing the answer in PACELC terms leads to more honest tradeoff discussions than the CAP-era habit of simply labelling a system “AP” and moving on.
When PA/EL is the right choice
Choose PA/EL systems when latency is a primary user-facing concern and your business logic can tolerate brief windows of stale data. Common examples include social media feeds, product recommendation engines, shopping carts (where over-selling can be handled operationally), and analytics dashboards. In all these cases, a 200ms read that returns data that is 500ms stale is usually far better for user experience than a 50ms wait for coordination that then takes 150ms to return perfectly current data.
When PC/EC is the right choice
Choose PC/EC systems when correctness is non-negotiable. Financial ledgers, inventory systems where overselling is unacceptable, healthcare records, and any system where “the user sees the value they just wrote” is a hard requirement all belong here. The latency cost is real but usually acceptable: within a single data centre, synchronous replication to a quorum typically adds only single-digit milliseconds. The cost rises dramatically only for cross-region global consistency.
When tunable systems (Cassandra, Cosmos DB) make sense
Some applications have heterogeneous requirements within a single system. A multi-tenant SaaS platform might need strong consistency for billing records but can accept eventual consistency for user activity streams. Tunable systems like Cassandra (consistency levels) and Cosmos DB (five consistency tiers) allow teams to make the latency-consistency tradeoff independently per query or per collection, rather than committing the entire application to a single point on the spectrum.
In a system design interview, once you have identified that your system needs replication (and almost all interesting systems do), ask yourself: “Is this PA/EL or PC/EC?” That question immediately surfaces whether consistency or latency is the dominant constraint — and from there, the database choice and replication strategy follow naturally. Candidates who can articulate this distinction clearly stand out from those who stop at “it’s an AP system.”
PACELC and the CAP theorem together
Finally, it is important to note that PACELC does not replace CAP — it contains it. The PAC portion of PACELC is exactly the CAP theorem. Abadi’s point was not that CAP is wrong, but that it is incomplete. A system’s behaviour during a partition still matters; it is just that the equally important behaviour outside of partitions had been left off the map entirely. Together, the two frameworks give a complete picture of the tradeoffs any replicated distributed database must navigate.
9. What We Have Learned
CAP gave distributed systems engineers a useful vocabulary in the 2000s, but it only tells half the story. PACELC tells the other half — and for most production systems, the other half is the one that matters every day. Here is a concise summary of what we have covered:
- CAP describes partition behaviour only. It models what a system must sacrifice when a network split occurs — consistency or availability. Since partition tolerance is not optional in any real multi-node system, CAP reduces to a single binary decision: C or A during a fault.
- CAP has three significant limitations. It uses an overly narrow formal model (a single read-write register), treats consistency and availability as binary when they are continuous spectrums, and completely ignores what happens during normal — non-partitioned — operation.
- The consistency-latency tradeoff is always present. The moment a system replicates data — which it must for availability and performance — every write and every read forces a choice between waiting for replicas to agree (consistency) and returning immediately (low latency). This tradeoff applies on every single request, not just during rare partitions.
- PACELC frames both operating modes. It classifies a system as PA/EL, PC/EC, PA/EC, or PC/EL — capturing both its partition-time behaviour (the CAP part) and its normal-operation behaviour (the Else part). PA/EL and PC/EC are the most common and most coherent design philosophies.
- Real databases map cleanly to PACELC. Cassandra and DynamoDB are PA/EL — speed and availability first. CockroachDB and Google Spanner are PC/EC — global consistency at the cost of higher latency. MongoDB is PA/EC. Cosmos DB is tunable across all quadrants.
- PACELC is a better design tool than CAP. When choosing a database or designing a replication strategy, asking “Is this PA/EL or PC/EC for normal operation?” gives you far more actionable guidance than asking “Is this CP or AP?”
