Spec-Driven Developmentwith AI Coding Agents: The Workflow Replacing”Prompt and Pray”
AI-assisted coding went from novelty to daily practice — but the dominant approach produces inconsistent, hard-to-review output. Spec-driven development is the pattern that keeps Java codebases maintainable. Here’s the workflow, the tooling, and the pitfalls nobody talks about.
There is a version of AI-assisted Java development that looks like this: a developer pastes a rough feature description into their IDE chat, watches the agent generate a service class and a repository layer, runs the tests, shrugs when three of them fail, prompts again to fix them, and eventually merges something that works — but that nobody else on the team can clearly explain or safely modify six months later. If that sounds uncomfortably familiar, you’re in good company.
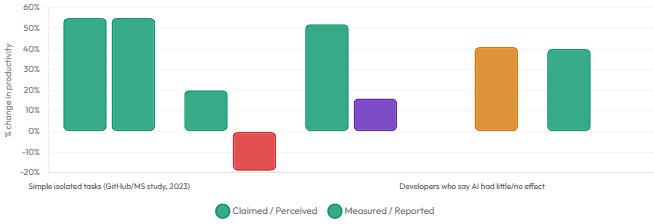
Stack Overflow’s 2025 Developer Survey — covering over 90,000 developers globally — found that 66% name “almost right, but not quite” code as their biggest frustration with AI tools, and a further 45% flag time spent debugging AI-generated code as a major drain. Meanwhile, a controlled study by METR found that experienced developers using AI tools took 19% longer to complete tasks than without — despite believing they were 20% faster. The gap between perceived and measured productivity is real, and it’s largely caused by the overhead of reviewing, correcting, and integrating unpredictable agent output.
Spec-driven development (SDD) is the emerging answer to this problem. The idea is simple in principle and non-trivial in execution: write a detailed specification first, then let the agent implement it. The spec becomes the contract between the human developer and the AI agent — and critically, it becomes the basis for code review, not the code itself. This article walks through why that shift matters, exactly what a good spec looks like for Java work, how to run the workflow with real tools, and where it fails.

That last number is the most important one. The dominant failure mode of AI-assisted development is not the model being wrong — it’s the model being wrong because it didn’t know something that the developer assumed was obvious. Spec-driven development is, at its core, a discipline for making the implicit explicit before the agent ever sees a task.
1. Why “Prompt and Pray” Fails Java Teams Specifically
The “prompt and pray” pattern has a home context where it works reasonably well: small, self-contained tasks, boilerplate generation, quick scripts, and greenfield prototypes. The problems compound when it meets the reality of a mature Java codebase — and they compound in several specific ways that are worth naming.
1.1 The context gap is architectural, not incidental
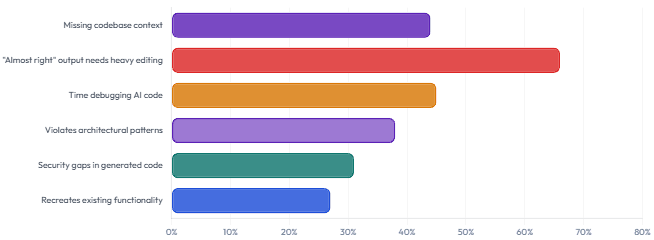
A Java enterprise service is typically built on a specific set of decisions: which transaction management strategy, which exception hierarchy, which validation framework, how repositories handle pagination, whether DTOs use MapStruct or manual mapping, how Spring Security context propagates. An AI agent handed a feature request has no access to any of this. Qodo’s 2025 State of AI Code Quality report found that structural tasks — refactoring and feature additions that require understanding the broader codebase — are precisely the tasks where AI context gaps are most severe. The agent generates code that compiles, integrates it into the wrong layer, and uses patterns that conflict with existing conventions. The developer then spends 45 minutes correcting it.
1.2 Code review becomes harder, not easier
When a human developer writes code, the pull request implicitly carries intent — the reviewer can ask “why did you do it this way?” and get a meaningful answer. When an agent writes code without a spec, that question has no good answer. The output reflects what pattern the model has seen most frequently, not what your architecture requires. Thoughtworks’ analysis notes that this dynamic shifts the review burden from evaluating intent to auditing implementation line-by-line — which is the opposite of what code review is supposed to do.
1.3 Non-determinism compounds over time
Language models are non-deterministic. Run the same prompt twice and you may get slightly different code. In a codebase where multiple features were built this way, over time you end up with inconsistent patterns that all technically work but that resist standardisation. InfoQ’s architectural analysis puts this plainly: a code issue produced by AI generation is an outcome of a gap in the specification, and because of non-determinism, that gap resurfaces in different forms every time the code is regenerated. The spec is the only stable, repeatable thing. Without it, you’re not shipping features — you’re accumulating drift.
Spec-driven development may not have the visibility of a term like vibe coding, but it is nevertheless one of the most important practices to emerge in 2025.
Thoughtworks Technology Advisory, December 2025
1.4 Where AI-Generated Code Actually Fails — Root Causes Reported by Developers
2. What Spec-Driven Development Actually Means
The term “spec-driven development” covers a spectrum of rigor, and it’s important to be precise about what we mean here — because the spectrum ranges from “write a bit more context in your prompt” to “make the specification a formally executable artifact.” An arXiv paper published in early 2026 describes three distinct levels:
| Level | Name | Spec Role | Best For | Java Fit |
|---|---|---|---|---|
| Level 1 | Spec-First | Markdown requirements doc; human-reviewed before agent proceeds | Feature additions to existing codebases; team use | High — practical starting point |
| Level 2 | Spec-Anchored | Spec + BDD scenarios / API contracts that validate generated code | API-first services; regulated environments; multi-team | High — pairs well with Spring + OpenAPI |
| Level 3 | Spec-as-Source | Specification literally becomes the source artifact; code is a derived output | Embedded systems, formal verification contexts | Low — too rigid for most Java teams today |
For most Java enterprise teams in 2026, Level 1 (Spec-First) is the right starting point. Level 2 becomes appropriate once the team has built the habit and wants to add automated drift detection. Level 3 is largely theoretical for application development.
The practical workflow at Level 1 follows four sequential phases — and the critical discipline is that each phase must be completed and reviewed before the next begins. Skipping from Phase 1 to Phase 4 is just “prompt and pray” with extra steps.
Phase 1 · Human Work
Write the requirements document
A Markdown file (docs/requirements.md) that defines: the user story, measurable acceptance criteria, explicit constraints (“what NOT to build”), integration points with existing services, and non-functional requirements. The agent does not touch code until this document exists and has been reviewed by a second human. The spec is the contract — it should be specific enough that another developer could implement without clarification.
Phase 2 · Agent Work, Human Review
Let the agent produce an implementation plan
Ask the agent to read requirements.md and produce docs/plan.md — a technical implementation plan that maps requirements to design decisions. Crucially, you are not asking for code yet. You’re asking the agent to reason about the approach. JetBrains’ Junie documentation calls this “the checkpoint” — a space to review strategy before any code changes happen. Reviewing a plan is fast. Reviewing wrong code is slow.
Phase 3 · Agent Work, Human Review
Break the plan into bounded tasks
The agent produces docs/tasks.md — a numbered checklist of atomic implementation units. Each task should have a clear definition of done. The key discipline here is that you never ask the agent to “do everything in tasks.md.” Instead, you say: “Complete tasks 1–2 from tasks.md and mark them as completed.” Bounded context per agent invocation is what keeps output reviewable. Each task completion triggers a human review before the next task begins.
Phase 4 · Agent Work, Human Gate
Controlled implementation with validation
The agent implements each task, constrained by the plan. After each set of tasks: review code changes, run existing tests, confirm the implementation matches the spec. If a task uncovers unexpected complexity, update tasks.md before proceeding. The spec and the plan are living documents during this phase — if reality diverges from the plan, the plan gets updated, not silently ignored. The spec remains the source of truth throughout.
3. What a Good Java Spec Actually Contains
The quality of agent output correlates directly with the quality of the specification — and for Java specifically, there are categories of context that are easy to omit because they feel obvious to the team but are completely opaque to the agent. Here is a concrete example of the structure that works.
# docs/requirements.md — Example: Payment Processing Service Feature # This file is reviewed by a senior engineer before the agent proceeds to Plan phase. ## 1. User Story As a checkout service, I want to submit a payment request and receive a synchronous response with either a confirmation token or a typed failure reason, so that I can surface actionable errors to the frontend without polling. ## 2. Acceptance Criteria (must all pass before merge) - POST /api/v1/payments returns 200 + PaymentConfirmationDto on success - Returns 422 + PaymentFailureDto (with machine-readable reason code) on validation failure - Returns 503 + retry-after header when payment provider is unavailable - Response time p99 < 800ms under 200 concurrent requests (existing load profile) - All inputs validated via existing @ValidPaymentRequest annotation (do NOT add a new one) ## 3. Explicit Constraints — What NOT to Build - Do NOT introduce async processing or queuing; this endpoint is synchronous by design - Do NOT add a new PaymentRepository; use the existing AuditLogRepository for persistence - Do NOT catch Exception broadly; use the existing GlobalExceptionHandler pattern - Do NOT use Lombok @Builder on response DTOs; team standard is record types (Java 21) ## 4. Integration Points - Calls StripeGatewayClient (existing bean, located in payment.gateway package) - Uses PaymentContextHolder for propagating idempotency keys (existing, ThreadLocal-backed) - Emits PaymentAttemptedEvent via existing ApplicationEventPublisher — see EventCatalog.md ## 5. Non-Functional Requirements - Idempotent: duplicate requests within 5 minutes must return the original response - Auditable: every attempt logged to AuditLog table with correlation ID from MDC - No new Spring Security config; endpoint inherits existing /api/v1/** RBAC policy ## 6. Out of Scope (explicitly, to prevent agent hallucination) - Refunds, partial captures, multi-currency support — separate stories - Webhook handling from Stripe — separate service
Notice what this specification contains that a typical developer prompt does not: explicit references to existing patterns, a clear list of what the agent must not build, integration points with named existing classes, and non-functional constraints that the agent would otherwise invent its own approach to. The section headings are not arbitrary — they map to the categories of context that the Zencoder SDD guide identifies as most frequently missing from agent inputs.
The “explicit constraints” section is the most valuable part of any spec. In established codebases, agents consistently recreate functionality that already exists, introduce patterns that conflict with team standards, and add new dependencies instead of using existing ones. Telling the agent what not to build is at least as important as telling it what to build. Most spec templates omit this entirely.
4. The Tooling Landscape in 2026
Several tools now offer structured support for spec-driven workflows, either as first-class features or as compatible frameworks. None of them is a complete solution — they are best understood as scaffolding around the human discipline described above.
| Tool | License / Type | SDD Workflow | Agent(s) | Java Support | Best For | Notable Detail |
|---|---|---|---|---|---|---|
| GitHub Spec Kit | Open Source | /spec→/plan→/tasks→implement | Copilot, Claude Code, Gemini CLI | Language-agnosticMarkdown-based; works with any JVM project | GitHub Copilot teams | Framework-neutral; team brings its own agent and tooling discipline |
| Amazon Kiro | AWS / Paid | spec→hooks→auto-steer | Kiro native agent | GoodAWS SDK and Lambda integration built-in | AWS-native Java microservices | SDD workflow is predefined and enforced by the IDE; least manual setup of the four |
| JetBrains Junie | Commercial | requirements→plan→tasksIn-IDE; checkpoint review before code generation | Junie agent (IntelliJ-native) | ExcellentJVM-aware; understands Spring beans, Maven deps, class hierarchy | IntelliJ IDEA Java teams | Agent reads the project model directly — no need to manually include class context in the spec |
| Claude Code + AGENTS.md | CLI / API | AGENTS.md→custom flowTeam defines and owns the entire SDD process | Claude (long context, Git-native) | StrongLarge context window handles full Maven monorepo in one session | Teams who want full workflow ownership | Most flexible but requires the most discipline — no guardrails beyond what the team writes into AGENTS.md |
For Java teams on IntelliJ, Junie offers the most integrated experience because the agent has direct access to the project model — it understands Spring beans, Maven dependencies, and existing class hierarchies without the developer having to manually include that context in the spec. For teams on VS Code or using CLI workflows, Claude Code with a well-maintained AGENTS.md file offers the most flexibility. Thoughtworks notes that methodologically neutral tools like Claude Code and Cursor require the team to define their own SDD workflow — which is both a burden and an advantage, since it forces the team to make the process explicit rather than relying on a tool’s opinionated defaults.
Developer Perception vs Measured Reality — AI Tool Productivity (2025 Studies)
5. The Pitfalls Nobody Talks About
Spec-driven development has genuine weaknesses that its advocates often gloss over. Understanding them upfront prevents the disillusionment that comes from treating SDD as a silver bullet rather than a structured practice.
Pitfall 1 · The Waterfall Trap
Over-formalised specs slow feedback cycles
Writing an exhaustive spec before writing any code sounds rigorous, but it can reintroduce waterfall dynamics. The ThoughtWorks Technology Radar explicitly warns that early SDD adopters are “relearning that handcrafting exhaustive AI rules fails to scale.” The antidote is to scope specs tightly — one feature, not one service. A spec that takes longer to write than the feature would take to implement is a process smell.
Pitfall 2 · Spec Rot
Specs drift from the code they spawned
Once the agent has implemented a feature, the spec can quickly become outdated as the code evolves through subsequent PRs and bug fixes. If the spec is treated as a disposable process intermediate rather than a living document, it provides false confidence on future regeneration. The team needs a clear policy on spec maintenance — either the spec is updated with every significant code change, or it is explicitly marked as a snapshot-at-time-of-implementation.
Pitfall 3 · Context Window Limits
Large codebases still overwhelm agents
Even with a perfect spec, an agent operating on a large Spring monolith may lose track of earlier context as it works through tasks. Cerbos research calls this “context rot” — accuracy drops as more context accumulates within a single session. The mitigation is to keep agent sessions short and task-scoped, re-supplying the spec and relevant existing code at the start of each session rather than assuming the agent “remembers” from earlier in the conversation.
Pitfall 4 · Security Blindspots
Specs don’t automatically encode security requirements
Agents generate code that matches the spec — not code that is secure by default. If the spec doesn’t explicitly address input sanitisation, SQL injection vectors, authentication checks, and audit logging, the agent won’t add them. For Java services, this means security requirements must be first-class spec citizens, not afterthoughts. Consider a shared security-constraints.md file that is automatically included in every feature spec via an AGENTS.md reference.
A specific Java security note: AI agents are prone to generating broad
catch (Exception e)blocks, overly permissive CORS configurations, and missing@PreAuthorizeannotations on new endpoints — particularly when these are not explicitly called out in the spec. Add a security checklist to your spec template and make it a required section, not an optional one.
6. Rolling It Out on an Existing Java Team
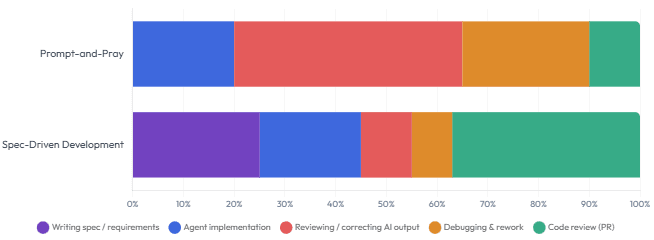
The biggest adoption barrier for SDD is not technical — it’s the perception that writing specs is overhead rather than work. The reframe that tends to land well with senior engineers is this: the spec replaces the time you currently spend in Slack explaining context to the agent repeatedly. It’s not additional work; it’s front-loaded work that compounds.
A practical two-phase rollout for teams coming from “prompt and pray” looks like this. In the first two weeks, introduce the spec template for new features only — don’t try to retrofit existing code. Run one SDD cycle end-to-end with a senior engineer acting as “spec author” and a junior engineer as “reviewer.” The explicit goal is to discover what context your team currently assumes and which categories are missing from the template. In the following month, add the security-constraints.md shared file and make it a required include in all specs. Add a simple validation gate to CI: if a PR introduces a new Spring @RestController endpoint without a corresponding docs/requirements.md entry referencing that endpoint’s path, the build fails with a clear message.
# Simple Maven Enforcer plugin rule to require a requirements.md exists
# before a new @RestController file can be merged.
# Add to your pom.xml <build><plugins> section:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-enforcer-plugin</artifactId>
<version>3.5.0</version>
<executions>
<execution>
<id>spec-required</id>
<goals><goal>enforce</goal></goals>
<configuration>
<rules>
<requireFilesDontExist>
<!-- CI script checks git diff for new *Controller.java files -->
<!-- and enforces a matching docs/requirements.md entry exists -->
<!-- see: .github/workflows/spec-check.yml in your repo -->
</requireFilesDontExist>
</rules>
</configuration>
</execution>
</executions>
</plugin>
# Complement with a GitHub Actions check (.github/workflows/spec-check.yml):
# This script runs on PR and verifies that any new *Controller.java file
# introduced in the diff has a corresponding docs/requirements.md entry.
name: Spec Presence Check
on: [pull_request]
jobs:
spec-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with: {fetch-depth: 0}
- name: Check spec exists for new controllers
run: |
NEW_CONTROLLERS=$(git diff --name-only origin/main HEAD \
| grep -E 'Controller\.java$' | grep '^src/')
for f in $NEW_CONTROLLERS; do
CLASS=$(basename "$f" .java)
if ! grep -r "$CLASS" docs/ >/dev/null 2>&1; then
echo "❌ No requirements.md entry found for $CLASS"
echo " Add a spec to docs/ before merging new endpoints."
exit 1
fi
done
echo "✅ Spec presence check passed"
That CI check is deliberately lightweight — it verifies that a spec document exists and references the new controller class, not that the spec is high quality. Quality is a human judgment. The check prevents the most common failure mode: forgetting to write the spec at all because the sprint is moving fast.
One important mindset shift for senior engineers: in spec-driven development, writing the spec is the senior engineering contribution. The agent implements; the experienced developer thinks. Zencoder’s SDD guide notes that this democratises AI productivity — junior developers following the same spec-to-implementation workflow produce more consistent output because the architectural reasoning is captured in the spec, not locked in individual prompting expertise.
Time Distribution: Prompt-and-Pray vs Spec-Driven Development (Typical Feature Cycle)
7. What We Have Learned
The “prompt and pray” pattern is not a developer failing — it is a rational response to tooling that rewards speed. However, as AI coding agents move from autocomplete assistants to autonomous implementers working across multiple files, that approach breaks down in ways that are slow and expensive to repair: inconsistent patterns, unreviewed security gaps, non-deterministic drift, and code that no one fully owns because no one designed it.
Spec-driven development does not fix AI coding agents. What it does is give the agent a contract to execute against, give the reviewer something meaningful to evaluate, and give the team a written record of intent that outlasts the conversation that produced it. For Java teams specifically, the most important spec sections are the constraints — what existing patterns to follow, what not to build, which existing classes to use — because these are precisely the architectural decisions that agents cannot infer from a feature description alone.
The tooling — GitHub Spec Kit, Amazon Kiro, JetBrains Junie, Claude Code with AGENTS.md — is mature enough to support this workflow today. The harder part is cultural: treating spec-writing as the primary engineering contribution rather than an administrative overhead. Teams that make that shift consistently produce more reviewable, more maintainable, and ultimately more trustworthy AI-assisted code. In 2026, that distinction is increasingly the difference between AI as a force multiplier and AI as a technical debt accelerator.
