From Dijkstra’s irreducible warning to the limits of formal proof — a philosophical inquiry into what it means to know that software works.
Every time a test suite goes green, a developer makes a claim — quietly, implicitly, without usually examining it: “this code is correct.” But correct for what? Correct to what degree? Correct under which assumptions? And correct as known by whom?
These are not merely academic questions. They are the questions that distinguish a test suite that finds bugs from one that creates false confidence. Understanding the epistemology of testing — that is, the theory of what testing actually allows us to know — is one of the most practically useful things a software engineer can do. And it begins, necessarily, with one of the most quoted and least examined sentences in the field.
Program testing can be used to show the presence of bugs, but never to show their absence.
— Edsger W. Dijkstra, “Notes on Structured Programming,” 1970
Dijkstra was not being cynical. He was being precise. And that precision matters, because fifty-five years later, the industry’s relationship with that sentence remains deeply uncomfortable. We quote it, then act as though it doesn’t apply to our test suite, our coverage metrics, our CI pipeline. We treat a passing build as proof. It isn’t. But understanding exactly what it is — and what alternatives exist — is where the real intellectual work begins.
1.The Asymmetry at the Heart of Testing
Dijkstra’s observation is not a statement about engineering quality. It’s a statement about logic — specifically about the difference between verification and falsification. Karl Popper made the same observation about science decades earlier: you can never verify a universal claim by observing instances of it, but you can falsify it by finding a single counterexample. A test suite is an empirical instrument. It probes a finite number of inputs and states. Your software, by contrast, operates across an effectively infinite space of possible inputs, execution orderings, hardware states, and environmental conditions.
Consider the simplest possible function: one that adds two 32-bit integers. The input space is 2⁶⁴ — roughly 18.4 quintillion combinations. If you ran 1,000 tests per second and started in the year 1 AD, you would still be running today. Testing a function that works on three threads, each of which can be preempted at any instruction boundary, produces a combinatorial explosion that makes exhaustive testing not merely impractical but cosmologically impossible.
This is not a solvable engineering problem. It is a fundamental epistemic constraint. And once you internalise it, the question changes from “how do I prove my code is correct?” to something more honest: “what kind of knowledge am I actually acquiring, and how confident should I be in it?”
Testing is not proof. It is probabilistic evidence — evidence that is structured, biased, and incomplete in ways that matter enormously.
2. What Empirical Testing Actually Gives You
If testing cannot prove absence of bugs, it might seem tempting to dismiss it. That would be a mistake. Empirical testing gives us something real and valuable — it gives us falsification under specific conditions. When a test fails, you know something definitive: the code behaves incorrectly for at least this input, in this environment, at this moment. That is a hard epistemological fact. The problem is not with what a failing test tells you. It’s with what a passing test tells you.
A passing test tells you that the code behaved correctly for that particular input, in that particular execution environment, with those particular side-effects suppressed or mocked. It tells you nothing about other inputs, other environments, or other concurrency interleavings. The confidence gap between “all tests passed” and “the code is correct” is bridged not by logic, but by the developer’s informal model of the code’s behaviour — a model that is almost never made explicit and almost always incomplete.
2.1 The Problem of Test Oracle
There is a deeper problem lurking beneath test coverage discussions: the oracle problem. To write a test, you need to know what the correct answer is. For simple functions, this is trivial. For complex systems — distributed consensus algorithms, financial calculations under edge conditions, machine-learned classifiers — specifying the oracle is as hard as writing the code itself, sometimes harder. Many real-world bugs live precisely in the gap between what the oracle is capable of expressing and what the code actually does. A test that checks the wrong thing gives you not just no evidence, but actively misleading evidence: it trains your intuition that the code is correct when it isn’t.
The Test Oracle Problem
A test oracle is the mechanism by which you determine whether a test passed or failed — in the simplest case, an expected output value. The oracle problem is the difficulty of specifying correct oracles for complex systems, particularly when the correct behaviour is not precisely known in advance, depends on subtle invariants, or emerges from the interaction of many components. It is a well-studied problem in software testing theory, first formalised by Weyuker (1982). Many classes of software — machine learning systems, compression algorithms, numerical simulations — are inherently “non-testable” in the traditional sense because the oracle problem is effectively unsolvable.
3. Property-Based Testing — Asking Better Questions
One of the most productive responses to the oracle problem, and to the epistemic limits of example-based testing generally, is property-based testing. Rather than asking “does this function return 4 when given 2 + 2?”, property-based testing asks “does this function satisfy these structural invariants for all inputs from this domain?” The shift is philosophically significant: instead of checking specific outputs, you are specifying general truths.
QuickCheck, originally developed for Haskell by Koen Claessen and John Hughes in 1999, pioneered this approach. In QuickCheck, assertions are written about logical properties that a function should fulfill; the library then attempts to generate test cases that falsify those assertions. When it finds a failing case, it shrinks the input to the smallest possible counterexample — a critical feature, because randomly generated failures are often too large and complex to debug directly.
The insight is elegant. You are not testing whether reverse([1,2,3]) == [3,2,1]. You are testing that reverse(reverse(xs)) == xs for all xs — which is a property that expresses something true about what reversal means, not just what it does on one input. Furthermore, you can express properties like “sorting is idempotent,” “serialisation and deserialisation are inverse operations,” and “all elements of the input appear in the output of a filter, and no others” — properties that rule out large classes of bugs simultaneously.
Haskell — QuickCheck property for round-trip serialisation
-- A round-trip property: any value serialised then deserialised
-- should be identical to the original. Tests this for 100 random inputs.
import Test.QuickCheck
prop_roundTrip :: Order -> Bool
prop_roundTrip order =
deserialise (serialise order) == Just order
-- Run with: quickCheck prop_roundTrip
-- +++ OK, passed 100 tests. — or —
-- *** Failed! Falsifiable (after 14 tests and 2 shrinks):
-- Order {id = 0, amount = -1, currency = ""} ← shrunk counterexample
The Hypothesis library brought this to Python with sophisticated stateful testing. Property-based testing was mainly introduced by the QuickCheck framework in Haskell, and it targets all the scope covered by example-based testing: from unit tests to integration tests. Today, implementations exist for Java (jqwik), Rust (quickcheck, proptest), JavaScript (fast-check), Scala (ScalaCheck), and most other mainstream languages.
Nevertheless, property-based testing doesn’t escape Dijkstra’s warning. It samples from the input space — more cleverly than hand-written tests, but still finitely. It shifts the epistemic question from “did this specific input pass?” to “did any of these 10,000 randomly generated inputs fail?” — a more powerful question, but still an empirical one. The gap between “no counterexample found in 10,000 runs” and “no counterexample exists” remains unbridged. To cross that gap entirely, you need a different kind of tool.
The Knowledge Spectrum: From Tests to Proof
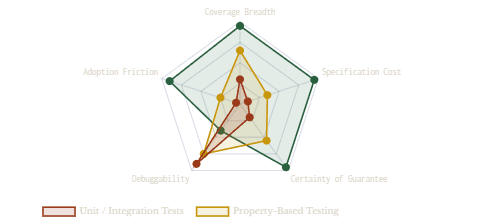
4. Formal Verification — What Proof Actually Costs
Formal verification promises to cross the gap entirely. Instead of running code against inputs and observing outputs, you prove — mathematically, with machine-checkable steps — that the code satisfies a specification for all possible inputs and all possible execution paths. If the proof is correct, Dijkstra’s warning no longer applies. You don’t merely have evidence. You have knowledge in the strongest available sense.
This is not science fiction. It is a real and growing field. The seL4 microkernel has a machine-checked proof of functional correctness — its implementation in C is proven to correspond to its formal specification under the semantics of C as formalised in Isabelle/HOL. The CompCert C compiler has been proven correct: it never produces incorrect output for any valid C program. Amazon uses TLA+ to verify the design of services like DynamoDB and S3. High complexity increases the probability of human error in design, code, and operations; standard verification techniques in industry are necessary but not sufficient — deep design reviews, code reviews, static code analysis, stress testing, and fault-injection testing can still leave subtle bugs hiding in complex concurrent fault-tolerant systems.
However, formal verification carries costs that make it inaccessible for most production software development, and those costs are worth examining honestly rather than hand-waving away.
4.1 The Specification Problem
To formally verify code, you first need a formal specification. And writing a correct formal specification is at least as hard as writing correct code — sometimes harder, because specifications must be written in languages designed for mathematical precision rather than computational convenience. Tools like Coq (now Rocq), Lean 4, and Isabelle/HOL require significant expertise. Specification languages like TLA+, while useful, cannot easily specify global correctness properties of the program — for example, it’s hard to write a contract that specifies that the program must eventually respond to every user request, or that the database can never lose data.
Furthermore, a verified system is only as trustworthy as its specification. If the specification does not capture what the system should do, the proof is correct but meaningless. This is the specification gap: bugs at the level of what you intended the system to do cannot be caught by formal verification, only bugs in the implementation relative to the stated specification. In practice, many real-world failures — including security vulnerabilities — live precisely at the boundary between intent and specification.
The Verification Gap
Formal verification proves that code matches a specification. It cannot prove that the specification captures what you actually wanted. This distinction — between verified correctness and intended correctness — is not a technical limitation to be engineered around. It is an irreducible epistemic boundary. A formally verified system can still fail to do what its users need.
4.2 The Model–Reality Gap
Even when specifications are correct, verified systems interact with the unverified world. Hardware has timing vulnerabilities. Operating system schedulers introduce non-determinism not present in formal models. Network stacks have bugs. The JVM adds abstractions that differ from the CPU’s actual execution model. Verification at one layer of the stack provides strong guarantees within that layer — but the stack is deep, and each transition between layers introduces new epistemic risk.
Formal Verification in Industry: Where It’s Actually Used
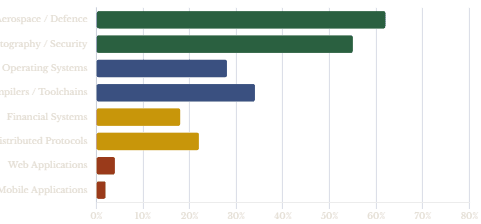
5. A Hierarchy of Certainty
Having surveyed the landscape, it is worth mapping it honestly. Different techniques provide different kinds and degrees of epistemic warrant. None provides certainty without cost. The question for any engineering team is not “which technique proves correctness?” but “what kind of knowledge do we need, for which parts of our system, and what are we willing to pay for it?”
| Technique | What You Learn When It Passes | Certainty Level | Practical Cost | Best Applied To |
|---|---|---|---|---|
| Unit / Integration Testing | Correct for these specific inputs | Weak | Low | Regression detection, documentation |
| Property-Based Testing | No counterexample found across N random inputs | Moderate | Medium | Invariant validation, edge case discovery |
| Fuzzing (coverage-guided) | No crash/fault in explored code paths | Moderate | Medium–High | Security-sensitive parsing, I/O handling |
| Model Checking (TLA+) | Property holds for all reachable states up to bound | High (bounded) | High | Distributed algorithms, protocol design |
| Abstract Interpretation | Absence of specific runtime errors (e.g., null deref) | High (soundly) | High | Safety-critical C/C++ code, compilers |
| Theorem Proving (Coq, Lean) | Property holds for all inputs, all paths, always | Very High | Very High | Cryptographic primitives, OS kernels, compilers |
Notice that each step up the certainty ladder buys you more knowledge at the cost of more effort, more specification work, and — crucially — more assumptions about the correctness of the tools themselves. A proof assistant like Lean 4 has a small trusted kernel, and that kernel’s correctness is itself not machine-verified. It is verified by human scrutiny and the accumulated trust of the community. Certainty all the way down turns out to be turtles, not bedrock.
6.The Pragmatics of Knowing Enough
All of this might seem to lead to paralysis. If even formal proofs rest on unverified assumptions, if testing is fundamentally incomplete, if specifications can be wrong — what should engineers actually do? The answer is not nihilism. It is risk-calibrated epistemics.
Different parts of a system carry different failure costs. The sorting algorithm in a UI component and the serialisation logic for financial transactions are not the same kind of problem. A cryptographic hash function and a configuration file parser are not the same kind of problem. The appropriate level of epistemic rigour — the appropriate investment in certainty — is proportional to the cost of being wrong. Accordingly, the engineering practice that follows from taking testing epistemology seriously is not “apply formal verification to everything.” It is “apply the right kind of knowledge-acquisition to each component, proportional to what’s at stake if the knowledge is wrong.”
A Practical Heuristic
Start with property-based testing before adding more unit tests. Properties tend to surface the structural assumptions embedded in your code — and those assumptions are where real bugs usually hide. When a property-based test finds a failure, the shrunk counterexample often points directly to an edge case your mental model had excluded without realising it. This is knowledge acquisition at its most efficient.
There is also a sociological dimension to this that purely technical approaches miss. The purpose of a test suite is not solely to catch bugs in isolation. It is to build and maintain a shared model of the system’s intended behaviour across a team over time. Tests are a form of communicable knowledge — they encode assumptions in an executable and auditable form. A test that documents expected behaviour for a future developer reading the code is performing a different epistemological function than a test probing for edge-case failures. Both are valid. Conflating them, or optimising for only one, is where test suites go wrong.
In this sense, Dijkstra’s warning is not a counsel of despair. It is an invitation to be precise about what kind of knowledge you are claiming, what its limits are, and what those limits imply for how you build, test, and reason about the systems you are responsible for. That kind of epistemic precision — knowing what you know, and knowing what you don’t — is, in the end, the beginning of engineering as a mature discipline rather than a hopeful craft.
7. What We’ve Learned
Dijkstra’s 1970 observation — that testing shows the presence of bugs, not their absence — is not pessimism. It is a precise epistemological claim about the asymmetry between falsification and verification. Testing is empirical evidence: finitely sampled, environment-dependent, and oracle-constrained. It gives us strong knowledge when tests fail, and weaker probabilistic knowledge when they pass.
Property-based testing (QuickCheck, Hypothesis, jqwik) shifts the question from “did this input pass?” to “does this invariant hold across a large random sample?” — a more powerful frame that better maps the structural assumptions of code, and whose shrinking mechanism makes failures directly debuggable. But it remains empirical: no finite sample bridges the gap to universal correctness.
Formal verification (TLA+ for design, Coq/Lean for implementation proofs) bridges that gap — but at the cost of specification correctness, tool trust, and the unavoidable model–reality gap where verified models interact with unverified hardware and software stacks. The seL4 kernel and CompCert compiler demonstrate that this is possible; they also demonstrate that it is not cheap.
The mature practice is risk-calibrated: unit tests for regression and documentation, property-based tests for invariant discovery, formal methods for correctness-critical components. Knowing what you know — and what you don’t — is the epistemological foundation that makes the rest of the discipline coherent.
