1. Introduction: Java Enters the AI Arena
For years, Python dominated AI development while Java—the backbone of enterprise systems—remained on the sidelines. That changed dramatically in 2023-2024 with the emergence of Spring AI and LangChain4j, two frameworks purpose-built for integrating LLMs into Java applications. By 2025, both have matured into production-ready platforms powering enterprise AI systems worldwide.
The convergence is deliberate: Spring AI addresses the fundamental challenge of AI integration by connecting enterprise data and APIs with AI models, while LangChain4j simplifies LLM integration through unified APIs, supporting 20+ popular LLM providers and 30+ embedding stores. This article examines how Java developers can leverage these frameworks to build sophisticated AI applications without leaving the JVM ecosystem.

2. Spring AI: Enterprise AI with Spring Principles
2.1 Architecture Philosophy
Spring AI applies familiar Spring ecosystem design principles—portability, modularity, and POJOs—to AI domain challenges. The framework’s architecture centers on several key abstractions that Java developers recognize immediately.
The ChatClient API provides a fluent interface idiomatically similar to WebClient and RestClient, making LLM interactions feel native to Spring developers. Rather than learning proprietary SDK patterns, teams leverage existing Spring knowledge to build AI features.
The Advisors API encapsulates recurring generative AI patterns, transforming data sent to and from LLMs while providing portability across various models. This abstraction layer means switching from OpenAI to Anthropic or Azure OpenAI requires configuration changes, not code rewrites.
2.2 Model Context Protocol Integration
Spring AI’s deep integration with the Model Context Protocol represents a significant architectural advance. MCP standardizes how AI applications interact with external tools and resources through a Client-Server architecture that ensures clear separation of concerns. Developers can expose Spring services as MCP servers using simple annotations, or consume external MCP servers as clients.
This separation creates distinct developer communities: AI application builders orchestrate multiple MCP servers and integrate with AI models, while service developers focus on exposing domain-specific capabilities through standardized primitives without worrying about AI orchestration.
2.3 Production Readiness
Spring AI 1.0 GA, released in May 2025, brings enterprise-grade capabilities: ETL framework for document ingestion supporting sources from S3 to MongoDB, comprehensive observability through Spring Boot Actuator integration, and memory management features including compaction and retention policies for long-running conversations.
The framework supports all major AI providers—Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama—with structured outputs mapping AI model responses directly to POJOs. For vector databases, Spring AI provides auto-configuration for Apache Cassandra, Chroma, Milvus, MongoDB Atlas, Pinecone, Qdrant, Redis, and Weaviate.
3. LangChain4j: Framework-Agnostic AI for Java
3.1 Design Principles
LangChain4j was built as a framework that feels native to Java developers, embracing Java idioms like strong typing, annotation-driven programming, dependency injection, and compile-time checks. Created by Dmytro Liubarskyi in early 2023, the project stabilized with version 1.0 in May 2025 after extensive beta testing.
The framework provides three levels of abstraction allowing developers to choose appropriate balance between simplicity and control. High-level AI Services use interfaces and annotations for rapid development. Mid-level components like ChatMemory and EmbeddingStore offer modular building blocks. Low-level APIs provide direct access to model interactions when fine-grained control matters.
3.2 Multimodal and Agentic Capabilities
By spring 2025, LangChain4j supported multimodal models processing images, audio, and video, with use cases including podcast transcription, video chaptering, and large-scale document analysis now feasible in Java applications. The speech-to-text support with Gemini exemplifies this capability—audio instructions convert directly to actions or literal transcriptions based on prompting.
The framework embraces agentic architectures where multi-agent systems break complex tasks into specialized roles. Version 1.3.0 introduced langchain4j-agentic and langchain4j-agentic-a2a modules, moving these patterns from experimental to first-class support. Each agent implements as an AiService, with orchestration handled through Spring State Machine or Quarkus messaging patterns.
3.3 Enterprise Support and Governance
Both Red Hat and Microsoft support the project, with Microsoft reporting hundreds of customers running LangChain4j in production, backed by joint security audits and vulnerability remediation. The integration of OpenAI’s official Java SDK directly into the project signals enterprise-grade governance.
LangChain4j integrates seamlessly with Spring Boot, Quarkus, and Helidon, providing starter modules and auto-configuration for each framework. The comprehensive quality gates—code formatting via Spotless, 70-80% coverage with JaCoCo, dependency enforcement—ensure production reliability.
4. RAG Patterns: Connecting Knowledge to Models
4.1 The RAG Architecture
Retrieval-Augmented Generation enhances LLMs by incorporating an information-retrieval mechanism that allows models to access and utilize additional data beyond their original training set. Rather than retraining models when information changes, RAG augments the model’s external knowledge base with updated information.
The pipeline consists of four stages:
Ingestion: Authoritative data loads into a vector database. Spring AI’s ETL framework supports pluggable DocumentReader components for local files, web pages, GitHub repositories, AWS S3, Azure Blob Storage, and JDBC databases. LangChain4j provides similar document loaders with support for PDFs, Word documents, and various text formats.
Retrieval: When users query, the system converts their question to a vector embedding and searches the database for semantically similar content. This comparison uses approximate nearest neighbor algorithms like HNSW that scale efficiently to billions of vectors.
Augmentation: Retrieved documents combine with the original query into an enriched prompt. This augmented prompt provides context by combining relevant data from an external source with the user’s query, encouraging the LLM to use accurate information from search results.
Generation: The LLM generates responses grounded in retrieved context, dramatically reducing hallucinations while enabling citation of source documents.
4.2 Advanced RAG Techniques
As of 2025, RAG has evolved beyond simple similarity search. Agentic RAG systems use modular reasoning patterns—reflection, planning, tool invocation, and multi-agent collaboration—to build flexible and adaptive retrieval pipelines. These systems conduct iterative reasoning similar to human analysts, automatically falling back to web search when knowledge bases prove insufficient.
Hybrid search combines vector similarity with keyword matching (BM25) and metadata filtering in single queries. Self-RAG systems critique their own retrievals using reflection tokens to assess relevance, reducing hallucinations by up to 52% in open-domain tasks. Corrective RAG triggers web searches to update outdated retrievals, critical for financial or medical advice requiring current information.

5. Vector Database Integration
5.1 Selection Criteria
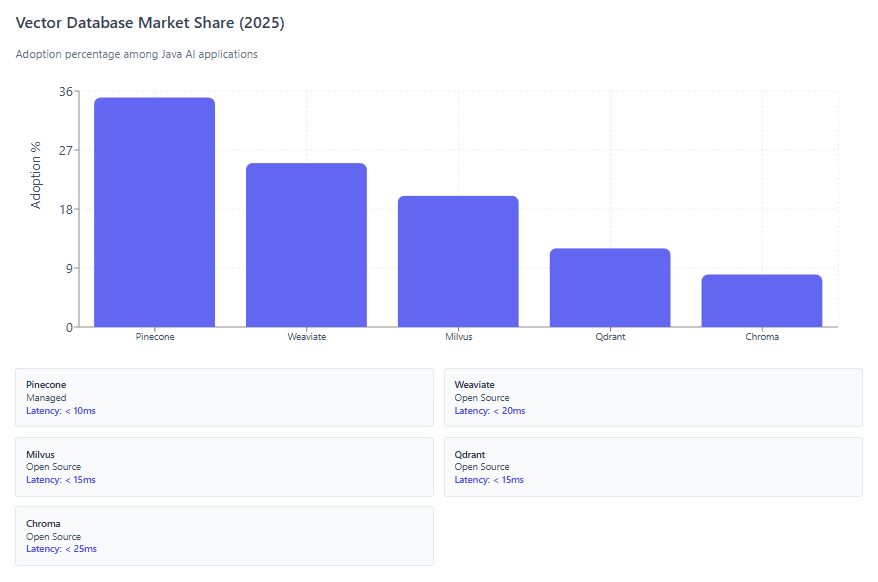
The vector database landscape offers diverse options optimized for different trade-offs. Pinecone delivers consistently low latency with p50 latencies under 10ms and p99 under 50ms, even at billion-vector scale, through serverless architecture that automatically optimizes query routing and caching.
Weaviate excels at hybrid search, natively combining vector similarity, keyword matching, and metadata filtering in single queries—making it ideal for RAG applications requiring comprehensive search capabilities. Milvus offers excellent configurability with support for IVF, HNSW, and PQ indexing methods, allowing precise balance between accuracy and speed. Qdrant provides sophisticated filtering capabilities with Rust-based performance.
5.2 Integration Patterns
Spring AI provides first-class vector store abstractions with auto-configuration for major providers. Configuration typically involves adding the appropriate starter dependency and specifying connection details:
spring.ai.vectorstore.pinecone.api-key=${PINECONE_API_KEY}
spring.ai.vectorstore.pinecone.environment=production
spring.ai.vectorstore.pinecone.index-name=documents
LangChain4j offers similar simplicity through unified embedding store interfaces. The pattern remains consistent across providers—create embeddings, store with metadata, query by similarity:
EmbeddingStore<TextSegment> embeddingStore =
PineconeEmbeddingStore.builder()
.apiKey(System.getenv("PINECONE_API_KEY"))
.index("documents")
.build();
5.3 Cost Considerations
Managed services like Pinecone trade operational simplicity for higher costs—typically $0.025 per GB-hour storage plus query charges. Self-hosted options (Weaviate, Milvus, Qdrant) eliminate subscription fees but require infrastructure management and DevOps expertise. The decision hinges on team capabilities and scale requirements.
6. Prompt Engineering in Java
6.1 Structured Prompting
Both frameworks support template-based prompt engineering with variable substitution. Spring AI’s PromptTemplate class enables parameterized prompts:
PromptTemplate template = new PromptTemplate(
"Summarize the following document in {length} words: {document}"
);
Prompt prompt = template.create(Map.of(
"length", "100",
"document", documentText
));
LangChain4j takes a more Java-native approach using interfaces and annotations:
interface Assistant {
@SystemMessage("You are a technical documentation expert")
@UserMessage("Summarize this in {{length}} words: {{document}}")
String summarize(@V("length") int wordCount,
@V("document") String text);
}
The annotation approach leverages Java’s type system, providing compile-time validation and IDE support that template strings cannot match.
6.2 Few-Shot Learning
Few-shot prompting provides examples to guide model behavior. Both frameworks support this pattern through message history construction. The technique proves particularly effective for domain-specific tasks where model training data may lack coverage.
6.3 Chain of Thought
For complex reasoning, chain-of-thought prompting encourages models to show their work. Explicitly requesting step-by-step reasoning improves accuracy on multi-step problems by 20-30% compared to direct answers, though at the cost of increased token usage.
7. Cost and Performance Optimization
7.1 Caching Strategies
LLM API calls represent the primary cost driver in AI applications. Implementing response caching can reduce costs by 60-80% for applications with repeated queries. Both Spring AI and LangChain4j support integration with Redis or Caffeine for semantic caching based on embedding similarity.
The strategy works by embedding incoming queries, checking for semantically similar cached queries within a threshold, and returning cached responses when matches exist. This approach balances exact-match caching’s limitations with the cost of regenerating responses.
7.2 Token Management
The ETL framework supports chunking strategies with overlap to maintain semantic context across chunks. Optimal chunk size depends on use case—typically 512-1024 tokens for general retrieval, smaller for precise answers. Overlap of 50-100 tokens prevents context loss at boundaries.
Context window management becomes critical for long conversations. Memory compaction techniques summarize older messages periodically, retaining essential context while reducing token consumption. Sliding window approaches maintain only recent history, appropriate for applications where historical context matters less.
7.3 Model Selection
Cost varies dramatically across models. GPT-4 provides superior reasoning but costs approximately 10x more than GPT-3.5 per token. The strategy involves routing: use smaller models for classification, summarization, and simple Q&A; reserve expensive models for complex reasoning, creative tasks, and critical decisions.
Both frameworks support dynamic model selection, allowing runtime switching based on task complexity or user tier. This flexibility enables cost optimization without sacrificing quality where it matters.
8. Ethical AI Considerations
8.1 Bias and Fairness
LLMs inherit biases from training data. Both frameworks support guardrails that filter or reject problematic content. LangChain4j’s InputGuardrails and OutputGuardrails check prompts and responses against criteria before allowing them through. Azure OpenAI includes built-in moderation checking for violence, hate speech, and self-harm.
The responsibility extends to application design. Developers should log and review AI decisions, particularly in high-stakes domains like healthcare, finance, or legal contexts. Human-in-the-loop patterns keep humans involved in critical decisions rather than fully automating.
8.2 Data Privacy
Spring Security and OAuth address control over what data is presented to LLMs and what APIs are made available, with the MCP spec supporting OAuth for enterprise concerns. For sensitive data, consider self-hosted models (Ollama) or private cloud deployments where data never leaves your infrastructure.
Implement data anonymization pipelines that strip personally identifiable information before sending content to external LLM APIs. Both frameworks support preprocessing chains that transform data before model interaction.
8.3 Transparency and Explainability
RAG inherently improves explainability by providing source citations. Applications should surface these sources to users, enabling verification of AI-generated claims. The pattern builds trust while allowing users to assess information quality independently.
Consider implementing confidence scores and uncertainty indicators. When retrieval quality is low or model confidence drops, surface these signals rather than presenting potentially incorrect information as fact.
9. Conclusion: What We’ve Learned
Building AI-powered applications in Java has matured from experimental to enterprise-ready in remarkably short time. Spring AI and LangChain4j represent complementary approaches: Spring AI provides deep integration with Spring ecosystem and emerging standards like MCP, while LangChain4j offers framework flexibility and extensive LLM provider support.
Key Takeaways:
- Framework Selection Matters: Choose Spring AI for Spring-native applications prioritizing enterprise features and MCP integration. Choose LangChain4j for framework flexibility, multimodal AI, or when building agentic architectures.
- RAG is Essential: Retrieval-Augmented Generation patterns reduce hallucinations while grounding responses in authoritative sources. Advanced techniques like agentic RAG and hybrid search address complex enterprise requirements.
- Vector Databases Enable Scale: Purpose-built vector databases (Pinecone, Weaviate, Milvus, Qdrant) provide the semantic search capabilities RAG requires. Selection depends on operational preferences (managed vs self-hosted) and specific requirements (hybrid search, filtering, latency).
- Cost Optimization is Critical: Caching strategies, token management, and intelligent model selection can reduce operational costs by 60-80% while maintaining quality. Production applications require monitoring and optimization.
- Ethics Cannot Be Afterthoughts: Implementing guardrails, ensuring data privacy, and maintaining transparency aren’t optional features—they’re fundamental requirements for responsible AI deployment.
The Java ecosystem now offers production-ready tools for building sophisticated AI applications. The question is no longer whether to integrate AI into Java systems, but how to do so responsibly, efficiently, and effectively. Both Spring AI and LangChain4j provide the abstractions, patterns, and integrations necessary to answer that question confidently.
