Understanding Consensus Algorithms: What Raft and Paxos Are Actually Solving and Why It Is Difficult
If you have ever configured an etcd cluster for Kubernetes, used CockroachDB, connected to a Consul service registry, or worked with Kafka in KRaft mode, you have already relied on a consensus algorithm. You just may not have needed to think much about it. That is partly by design — the algorithms exist precisely to make distributed coordination feel transparent to the systems built on top of them. However, when things go wrong — when a cluster loses quorum, when a network partition triggers an unexpected leader election, when writes start failing in the minority partition of a split network — the abstractions become leaky, and the underlying mechanics suddenly matter.
This article is for engineers who sit in that position: people who use distributed databases and coordination services daily but have never worked through the original papers. There are no mathematical proofs here, no formal notation. What follows instead is a clear conceptual explanation of what consensus algorithms are solving, how the two dominant approaches — Paxos and Raft — go about solving it, and why the problem is genuinely hard rather than merely bureaucratic.
Who uses these algorithms today: etcd (the backbone of Kubernetes), Consul, CockroachDB, TiKV, and Kafka’s KRaft metadata controller all run Raft. Google’s Spanner and Azure Storage use variants of Paxos. ZooKeeper uses ZAB — its own Paxos-inspired protocol. If you work in cloud-native infrastructure, you interact with one of these every day.
The problem: why agreement is hard across machines
On a single machine, agreement is trivially easy. You write to a variable; the value changes; anyone reading it sees the new value. The concept of “what the current value is” has exactly one answer.
Distribute that same data across three machines and the problem changes fundamentally. Now, when a client writes a new value, the question becomes: which of the three machines received the write first? What if one machine is temporarily unreachable when the write arrives? What if two clients write different values at almost exactly the same time? What if the machine that received the write crashes before telling the others? And critically — if one machine comes back from a crash and rejoins the cluster, how does it know which of its stored values are valid and which were superseded while it was away?
These questions all have the same root: in a distributed system, there is no shared clock, no shared memory, and no guarantee that messages arrive in the order they were sent. Yet most useful distributed systems need to appear to their clients as if they are interacting with a single, coherent data store. Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members. That is the problem these algorithms exist to solve.
The FLP impossibility result: A foundational result in distributed systems theory, proven by Fischer, Lynch, and Paterson in 1985, states that it is impossible for a deterministic distributed system to guarantee consensus in the presence of even one faulty process — if the system is asynchronous, meaning there is no bound on message delivery time. Consensus algorithms work around this by making practical assumptions about the world: that most messages arrive eventually, and that most machines do not fail simultaneously.
The replicated state machine: the concept underneath it all
Before looking at how Raft and Paxos work, it helps to understand the model they are operating on. Both algorithms are built around the idea of a replicated state machine.
Imagine each node in a cluster as a state machine — a system that takes a sequence of commands as input and produces a deterministic output. A hash table that accepts “set x to 3” and “set y to 7” is a simple state machine. If you feed the exact same sequence of commands to two identical state machines starting from the same initial state, they will always end up in the exact same state. Always. That determinism is the foundation everything else builds on.
The challenge, then, is not getting the state machines to agree on a single command. It is getting them to agree on the ordered sequence of all commands — what goes at position 1, what goes at position 2, and so on — even when nodes crash, messages are delayed, and new commands are arriving continuously. Each state machine takes commands from its log as input. The consensus algorithm must ensure that if any state machine applies a given command as the nth entry, no other state machine ever applies a different command at position n. If every node processes the same operations in the same order, they all arrive at the same state, and the cluster looks like a single reliable machine from the outside.
That log — an ordered, append-only sequence of commands — is what consensus algorithms are ultimately protecting. Everything else: leader election, quorum, heartbeats, term numbers — exists in service of keeping that log consistent across all nodes.
Quorum: the mathematics of “enough”
The foundational insight that makes consensus practical without requiring all nodes to be healthy at all times is the concept of a quorum — a majority of nodes whose agreement is sufficient to make a decision.
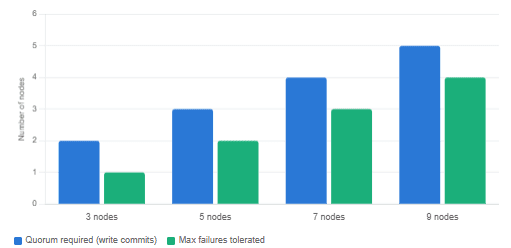
In a three-node cluster, a quorum is two nodes. In a five-node cluster, it is three. The general formula is simple: quorum equals the total number of nodes divided by two, rounded down, plus one. More practically: a cluster of N nodes can tolerate (N−1)/2 node failures before it loses the ability to make decisions. Three nodes tolerate one failure. Five nodes tolerate two.

The quorum requirement does something critical that goes beyond simple fault tolerance. It prevents split-brain — the situation where a network partition divides a cluster into two groups that each independently believe they are the authoritative cluster and each begin accepting writes. If both sides of a partition tried to accept writes, you would end up with two diverging versions of the log with no automatic way to reconcile them when the partition healed.
Quorum prevents this structurally. If a network partition splits a three-node cluster into a group of one and a group of two, the group of one cannot form a quorum — it needs two votes, and it only has one. It stops accepting writes and becomes read-only. The group of two can still form a quorum, elect a leader, and continue operating. When the partition heals, the isolated node rejoins and catches up by replaying the log entries it missed. This asymmetry — majority partition stays alive, minority partition pauses — is what makes consensus algorithms safe. Two overlapping majorities can never both be active simultaneously, because they share at least one node that would have voted for only one of them.
Why always an odd number of nodes? Even-numbered clusters do not improve fault tolerance and can cause ties in elections. A four-node cluster has the same fault tolerance as a three-node cluster — it can lose one node — but requires three votes for a quorum instead of two. The extra node adds cost without adding resilience. This is why production clusters run three, five, or seven nodes, never two or four.
Nodes required for quorum vs. maximum tolerated failures, by cluster size
How Raft works: the intuitive algorithm
Raft was introduced in 2014 by Diego Ongaro and John Ousterhout at Stanford, and its paper was explicitly titled “In Search of an Understandable Consensus Algorithm.” The primary design goal was not to be faster than existing algorithms — it was to be easier to reason about and implement correctly. Raft achieves this by decomposing consensus into three clearly separated sub-problems: leader election, log replication, and safety.
The three node states
Every node in a Raft cluster is always in exactly one of three states. It is either a follower, passively receiving updates and waiting for direction; a candidate, actively campaigning to become leader; or a leader, the single authoritative node accepting all writes and coordinating all log replication. At any given moment in a healthy cluster, there is exactly one leader and the rest are followers.
Terms: Raft’s logical clock
Raft divides time into terms — monotonically increasing integers that act as a logical clock for the cluster. Each term starts with an election and continues until the leader either fails or the cluster is restarted. Every message a node sends carries the sender’s current term number. When a node receives a message with a higher term number than its own, it immediately updates its term and demotes itself to follower status. This mechanism ensures that stale leaders — nodes that were leaders in a previous term but got disconnected and rejoined — can never mistakenly continue acting as leaders after a new election has completed.
Leader election
Raft uses a heartbeat mechanism to detect leader failure. The leader sends periodic heartbeat messages — technically empty AppendEntries RPCs — to all followers to maintain its authority. If a follower receives no communication for a period called the election timeout, it assumes the leader has failed and begins an election.
The election timeout is randomised, typically falling between 150 and 300 milliseconds. This randomisation is intentional and elegant: it makes it very unlikely that multiple followers simultaneously decide to run for leader, which would split votes and potentially delay convergence. The first node to time out campaigns, votes for itself, and asks the other nodes for their votes. A node grants its vote if it has not already voted in the current term and if the candidate’s log is at least as up-to-date as its own. The first candidate to collect a quorum of votes becomes the new leader.
The log-currency check: Raft’s requirement that candidates must have up-to-date logs before receiving votes is one of its most important safety properties. Raft only allows servers with up-to-date logs to become leaders — unlike Paxos, which allows any server to be leader provided it subsequently updates its log. This means a new Raft leader is always guaranteed to already hold all previously committed log entries, eliminating an entire class of data loss scenarios.
Log replication
Once a leader is established, the log replication process follows a simple pattern. When a client sends a write request, the leader appends the operation to its own log as a new entry and simultaneously forwards that entry to all followers. Once the entry has been replicated to a majority of servers, the leader marks it as committed, applies it to its own state machine, and notifies the followers to do the same. Only then does it respond to the client confirming success.
This two-phase approach — first replicate, then commit — is what gives Raft its durability guarantee. A write that returns success to a client is guaranteed to have been stored on a majority of nodes. Even if the leader crashes immediately after responding, at least a majority of nodes hold the entry, ensuring it will survive the subsequent election and eventually be applied to all nodes.
- Client sends write request to the leader node
- Leader appends the entry to its own log
- Leader sends the entry to all followers in parallel (AppendEntries RPC)
- Followers append the entry to their logs and acknowledge the leader
- Once a majority of followers have acknowledged, the leader commits the entry
- Leader applies the entry to its state machine and responds to the client
- Leader notifies followers on the next heartbeat to commit and apply the entry
Log consistency guarantee
One subtle but important property Raft maintains is the log matching property. If two entries in different logs have the same index and the same term number, they are guaranteed to store the same command — and furthermore, all entries preceding that index are also guaranteed to be identical. The leader enforces this by sending a consistency check with every AppendEntries call: it includes the term and index of the entry immediately preceding the new one. A follower only accepts the new entry if its own log contains a matching entry at that position. This interlock prevents diverged logs from silently diverging further.
How Paxos works: the original formulation
Paxos was developed by Leslie Lamport and, in its initial formulation around 1989, was described in a deliberately obfuscated literary style that baffled readers for years. The paper — “The Part-Time Parliament” — described the algorithm through the analogy of a part-time legislature on the Greek island of Paxos, a framing that charmed nobody who was trying to implement a distributed database from it.
The core Paxos algorithm solves a simpler problem than Raft: it achieves consensus on a single value, sometimes called single-decree Paxos. For a replicated log — which needs consensus on an ordered sequence of values — you need Multi-Paxos, an extension that is substantially more complex. This distinction matters, because much of Paxos’s reputation for difficulty comes from the gap between the clean single-value proof and the messy practical extension.
Proposers, acceptors, and learners
Paxos defines three roles. Proposers are the nodes that initiate consensus by proposing a value. Acceptors are the nodes that vote on proposals. Learners are the nodes that learn the outcome once consensus is reached. In practice, most implementations combine all three roles in every node, but the conceptual separation is important for understanding the protocol’s logic.
The two-phase protocol
Paxos achieves consensus through two phases. In the prepare phase, a proposer selects a proposal number — a globally unique, monotonically increasing integer — and sends a prepare request to a majority of acceptors. Each acceptor either promises not to accept any proposal with a lower number than this one, or it informs the proposer of the highest proposal it has already accepted. In the accept phase, if the proposer receives a quorum of promises, it sends an accept request with its proposal number and a value. If no acceptor had previously accepted a value, the proposer can use its own value; otherwise, it must use the value from the highest-numbered proposal it learned about during the prepare phase.
This two-phase handshake ensures that any previously committed value is preserved. The most notable difference between Paxos and Raft in practice is their approach to leader election. Paxos allows any server to become leader provided it then updates its log to ensure it is current, whereas Raft requires candidates to already have up-to-date logs before winning an election. The Paxos approach requires an additional round of log reconciliation after every leadership change; the Raft approach avoids this by making the log-currency check part of the election itself.
Raft vs. Paxos: what the research actually shows
The narrative that Raft is fundamentally simpler than Paxos turns out to be more nuanced than the popular presentation suggests. A 2020 research paper by Heidi Howard and Richard Mortier concluded that Paxos and Raft take a very similar approach to distributed consensus, differing primarily in their approach to leader election — and that much of Raft’s perceived understandability comes from the clarity of its paper’s presentation rather than the underlying algorithm being fundamentally simpler.
That said, the practical engineering consequences of the presentation difference are real. Raft’s explicit decomposition into leader election, log replication, and safety as separate sub-problems makes it considerably easier to implement correctly, to test independently, and to reason about when debugging. The fact that etcd, Consul, CockroachDB, TiKV, and Kafka’s KRaft all chose Raft over Paxos when building new systems is a strong signal about which algorithm engineers find more tractable in practice.
| Dimension | Raft | Paxos / Multi-Paxos |
|---|---|---|
| Introduced | 2014 — Ongaro & Ousterhout, Stanford | 1989 — Leslie Lamport |
| Primary design goal | Understandability and correct implementation | Correctness and theoretical completeness |
| Leader election requirement | Candidate must have up-to-date log to win | Any node can become leader; log reconciliation happens after |
| Log replication direction | Always flows from leader to followers | Any node with a proposal number can drive the protocol |
| Structure | Three explicit sub-problems: election, replication, safety | Single-decree core + Multi-Paxos extension (poorly specified) |
| Complexity in practice | Clear implementation path; widely implemented correctly | Gap between theory and implementation has caused many bugs |
| Adoption in new systems | etcd, Consul, CockroachDB, TiKV, Kafka KRaft | Google Spanner, Azure Storage, ZooKeeper (ZAB variant) |
Network partitions: where the theory meets the real world
Understanding the theory of consensus algorithms is one thing. Seeing how it plays out during a real network partition is another. The partition scenario is the defining test of any consensus algorithm’s correctness guarantees, and it is worth walking through carefully.
Imagine a five-node cluster — nodes A, B, C, D, and E — where A is currently the leader. A network failure cuts the cluster into two groups: A and B on one side, and C, D, and E on the other. What happens?
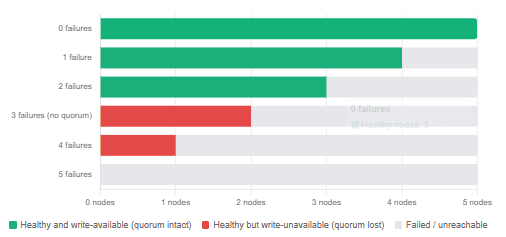
On the C-D-E side, three of the five nodes are present. Since three exceeds the quorum of three required for a five-node cluster, they can elect a new leader among themselves — say, C. They increment the term counter, complete an election, and continue accepting writes normally. On the A-B side, only two nodes are present. Two is less than the quorum of three, so A and B cannot confirm any writes. A, despite still believing itself the leader, will fail every write attempt because it cannot get acknowledgement from a majority. It effectively becomes read-only.
When the partition heals, nodes A and B rejoin the cluster. A realises from the term number in the first message it receives from C that an election has occurred in its absence. It immediately steps down from leadership and rejoins as a follower. Any uncommitted entries A had accepted but not yet replicated to a quorum are discarded, and A’s log is overwritten with the authoritative log from the new leader C. The cluster converges on a single consistent state, and no data that was committed — meaning acknowledged to a client — is ever lost.
The availability trade-off: Notice what the partition scenario means from a client perspective. During the partition, the A-B side refuses writes. Clients connected to A or B will experience write failures or timeouts until the partition heals. This is not a bug — it is the algorithm choosing consistency over availability, exactly as described by the CAP theorem. A cluster that chose to accept writes on both sides of a partition would be available but inconsistent. Raft and Paxos are firmly in the CP corner of CAP: they sacrifice availability in a minority partition in exchange for never serving divergent data.
Write availability in a 5-node Raft cluster under node failures (quorum = 3)
Log compaction and snapshots: solving the infinite log problem
A detail that the simplified description of Raft omits — but which matters considerably in long-running production systems — is that the replicated log cannot grow forever. If every write operation ever performed is retained in the log, nodes that crash and rejoin would need to replay the entire history of the system to recover their state, which would be prohibitively slow in any non-trivial system.
Raft handles this through snapshots. Periodically, a node serialises its current state machine state — the current value of every key in the database, for example — into a snapshot, then discards all log entries that were applied before that snapshot point. When a new node joins the cluster or an existing node falls significantly behind, the leader can send the snapshot directly rather than replaying thousands of individual log entries. The receiving node applies the snapshot and then replays only the log entries that were committed after the snapshot was taken.
This mechanism keeps log size bounded in production and allows fast recovery of lagging nodes — both essential properties that textbook descriptions of consensus algorithms typically leave as an exercise for the reader.
Where consensus algorithms live in the systems you already use
Understanding the theory is more concrete when mapped to the systems it underlies. The following are the places where, as a Java developer working in cloud-native environments, you are most likely to encounter consensus algorithms in practice.
| System | Algorithm | What it is protecting |
|---|---|---|
| etcd | Raft | All Kubernetes cluster state: pod assignments, service definitions, configuration |
| Consul | Raft | Service registry, health check state, distributed key-value configuration |
| CockroachDB | Raft (per range) | Each 512 MB data range has its own independent Raft group; thousands run in parallel |
| Apache Kafka (KRaft) | Raft variant (KRaft) | Cluster metadata: topic configs, partition assignments, broker membership |
| ZooKeeper | ZAB (Paxos-inspired) | Distributed coordination, leader election for systems that delegate to it |
| Google Spanner | Multi-Paxos | Global transaction ordering across geographically distributed data centres |
What engineers actually need to understand about consensus
For most engineers who are not implementing a consensus algorithm themselves, the practical takeaways are fewer and more focused than the full theory might suggest. Nevertheless, they are genuinely important for making good decisions about cluster configuration, failure handling, and client-side retry logic.
First, odd-numbered clusters are not an arbitrary convention — they are a direct consequence of quorum arithmetic. A two-node cluster has no fault tolerance despite having two copies of the data, because losing either node destroys the quorum. A three-node cluster with a quorum of two tolerates exactly one failure. Do not add a fourth node without adding a fifth; you would spend money without gaining resilience.
Second, write latency in a consensus-based system is bounded below by the round-trip time to a quorum of nodes. This is why production Kubernetes clusters run three or five etcd nodes locally rather than distributing them globally — cross-region quorum writes pay cross-region latency on every single write. Geography directly shapes performance when consensus is involved.
Third, reads are not always consistent by default. Many consensus-based systems allow follower nodes to serve reads for performance. A follower may be slightly behind the leader’s committed log, which means reads can return slightly stale data. If your application requires linearisable reads — reading your own writes, for example — you need to ensure you are reading from the leader or using the system’s linearisable read option, not a follower.
The key mental model: A consensus cluster does not guarantee that every node is up-to-date at every moment. It guarantees that any data successfully acknowledged as committed will not be lost, and that all nodes will eventually converge on the same state. The gap between those two guarantees — commitment now, convergence eventually — is where most subtle distributed systems bugs live.
What we have learned
In this article, we explored consensus algorithms from the ground up, starting with the core problem they exist to solve: giving a cluster of independent machines the ability to agree on an ordered sequence of operations despite failures, message delays, and partitions. We introduced the replicated state machine model — the log as a sequence of commands that, if applied identically on all nodes, produces identical state — and explained why maintaining that log consistently is the hard part. We then covered quorum as the mathematical foundation that makes consensus resilient without requiring all nodes to be healthy: a majority of nodes are sufficient to commit a decision, and two majorities can never exist simultaneously, which prevents split-brain. We walked through Raft’s three sub-problems — leader election via randomised timeouts, log replication via majority acknowledgement, and safety via the log-currency check on election — and contrasted it with Paxos’s two-phase prepare-and-accept protocol and its more permissive approach to leader candidacy.
We examined what actually happens during a network partition, tracing the behaviour of a five-node cluster whose minority side must stop accepting writes to preserve consistency. We also covered log compaction and snapshots — the mechanism that prevents infinite log growth — and closed with the practical implications for engineers: why cluster size must be odd, why geography affects write latency, and why reads from followers can be stale.
