Isolating Noisy Neighbors in Distributed Systems: The Power of Shuffle-Sharding
Every team running a multi-tenant service eventually meets the same uninvited guest: a tenant whose workload quietly monopolizes shared resources, degrading the experience for everyone else on the platform. The industry calls this the noisy neighbor problem, and it is one of the oldest, most stubborn challenges in distributed systems design. Naive load balancing does not solve it. Simple sharding only partially contains it. Shuffle-sharding, a combinatorial technique originally pioneered and open-sourced by AWS, reduces it to a statistically negligible event — without requiring additional infrastructure.
This article walks through the noisy neighbor problem from first principles, contrasts the three main isolation strategies, and explains exactly why shuffle-sharding’s mathematics are so powerful in practice.
- Real-world adoption: Shuffle-sharding is not a theoretical pattern. It powers Amazon Route 53, AWS Lambda’s asynchronous invocation pipeline, Grafana Cortex and Loki, and the Kubernetes API server’s priority and fairness flow control system.
Understanding the noisy neighbor problem
To appreciate shuffle-sharding, you first need to understand what it is protecting against. Picture a horizontally scaled service with eight worker nodes sitting behind a load balancer. Multiple tenants send requests, and the load balancer distributes those requests across all eight workers evenly. Under normal conditions, this architecture is both efficient and resilient. One node fails? The other seven absorb its load.
Then something unexpected happens. A single tenant — perhaps due to a runaway retry loop, a misconfigured batch job, a seasonal traffic spike, or even a deliberate DDoS attack — begins sending a flood of expensive requests. Each one lands on a different worker, because the load balancer is doing its job. Within seconds, every worker is saturated. The blast radius is total: all tenants on the platform suffer equally, even though only one of them is the source of the problem.
The key insight here is that the problem is not caused by the load balancer malfunctioning. It is caused by the architectural assumption that all workers are equally exposed to all tenants at all times. As long as that assumption holds, a single misbehaving tenant has a vector to reach every shared resource in the system.
The cascade risk: In the worst case, a noisy neighbor does not just slow a service down — it triggers a cascade. One overloaded node begins timing out, the load balancer routes its traffic elsewhere, remaining nodes become overloaded in turn, and the failure propagates until the entire cluster is down. AWS describes this as one of the primary failure modes they designed shuffle-sharding to prevent.
The three isolation strategies compared
Before diving into shuffle-sharding specifically, it helps to understand the landscape of isolation approaches and where each one breaks down.
Strategy 1: No isolation (uniform load balancing)
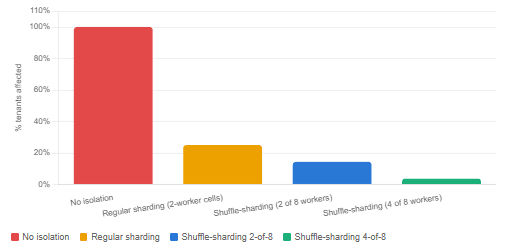
This is the default for most services at launch. All tenants share all workers. Operationally simple, easy to scale, and maximally efficient under normal load. However, the blast radius of any single misbehaving tenant is the entire cluster — 100% of other tenants are affected. Furthermore, as research from DZone has shown, CPU saturation under a noisy neighbor occurs almost immediately even at low request rates, because resource monopolization is unbounded.
Strategy 2: Regular sharding (static cells)
The natural first fix is to split workers into fixed cells and dedicate each cell to a fixed set of tenants. With eight workers divided into four cells of two workers each, a noisy tenant can only damage their own cell. Blast radius drops from 100% to 25%. That is a genuine improvement, and AWS internally calls this pattern cellularization. Availability Zones and isolated regions are macroscopic examples of exactly this idea.
The limitation, however, is equally clear. Regular sharding multiplies your operational complexity by the number of cells, effectively provisioning four independent services instead of one. Each cell must be sized to handle peak load independently, which means significant over-provisioning. More importantly, the number of cells — and therefore the number of distinct shard assignments — grows only linearly with the number of workers. There is a ceiling on how much blast radius reduction you can achieve.
Strategy 3: Shuffle-sharding (virtual overlapping shards)
Shuffle-sharding does something cleverly different. Instead of creating hard, non-overlapping cells, it assigns each tenant a virtual shard composed of a small subset of the available workers — say, two out of eight. Crucially, these assignments are randomized (or deterministically hashed) such that no two tenants share the exact same pair of workers. The workers still serve multiple tenants; however, the specific combination of workers any given tenant can reach is unique to that tenant.
When a noisy tenant saturates their two assigned workers, only the other tenants who happen to share at least one of those specific workers are affected. Because assignments are randomized and overlaps are minimized, the probability of any given innocent tenant sharing workers with the noisy one drops dramatically — and the mathematics behind that drop is where shuffle-sharding’s real power lives.

The combinatorial mathematics behind the magic
The reason shuffle-sharding is so dramatically effective comes down to a simple piece of combinatorics. When you assign a tenant to two workers chosen from a pool of eight, the number of possible unique assignments is 8 choose 2, which equals 28 distinct combinations. That means 28 different virtual shards can coexist in a fleet of just eight physical workers.
By contrast, regular sharding with cells of two workers produces only four cells from eight workers — a 7× difference in the number of distinct partitions. AWS observes that shuffle-sharding is seven times more effective than regular sharding in this configuration, and crucially, the improvement is not linear — it scales factorially as the fleet grows.
Consider what happens when you increase the shard size to four workers out of a fleet of eight. Now the number of unique shard combinations is 8 choose 4, which is 70. With 70 unique virtual shards available, the probability that any given innocent tenant overlaps with the noisy one is dramatically reduced. AWS’s own calculations show that with four workers per shard from a fleet of eight, blast radius drops to 1/1680 of the total customer base — a reduction that would be impossible to achieve with any static sharding scheme of equivalent fleet size.
The lottery analogy: Think of your worker nodes as lottery numbers and each tenant’s shard as their ticket. For two tickets to collide — meaning two tenants share all the same workers — both tickets must contain identical numbers. The more numbers on each ticket and the larger the pool, the more combinations exist and the less likely a complete overlap becomes. AWS engineer Colm MacCárthaigh described it precisely this way when he first explained the technique publicly.
Chart: blast radius reduction across strategies
How the shard assignment works in practice
A shuffle-sharding system needs to solve one core problem: given a tenant identifier, deterministically and consistently pick the same small subset of workers every time a request arrives. There are two main approaches to this, each with different operational trade-offs.
Stateless hashing
The most common approach uses a hash of the tenant identifier combined with a seed value to generate a shuffle of the worker list, then takes the first K workers from that shuffled list as the tenant’s virtual shard. Because the hash is deterministic, the same tenant always maps to the same workers, and no central state is needed. AWS’s Route Infima library implements exactly this: a hashed shuffle that produces stable, low-overlap shard assignments without requiring a coordination service. The trade-off is a small, bounded probability of shard overlap between tenants, acceptable in most systems.
Stateful assignment tracking
For tighter guarantees, a central coordinator can maintain an explicit map of tenant-to-worker assignments, actively minimizing overlaps when assigning new tenants. This eliminates the probabilistic overlap of stateless hashing but introduces a coordination dependency. Systems like Grafana Cortex use a ring-based approach to achieve shuffle-sharding across distributed ingester fleets, balancing zone awareness with shard minimization.
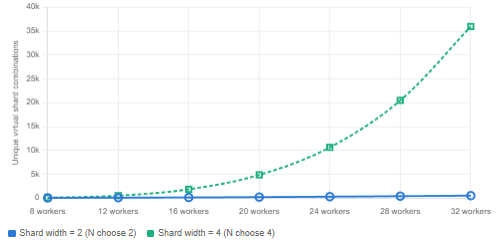
Chart: unique shard combinations available by fleet size and shard width
Number of unique virtual shards (N choose K) — as fleet grows from 8 to 32 workers
Where shuffle-sharding is used today
Understanding the real-world deployment context helps clarify both the power and the limits of the technique.
| System | How it uses shuffle-sharding | What it protects |
|---|---|---|
| Amazon Route 53 | Assigns each customer DNS zone to a virtual shard of name-server nodes | A DDoS against one customer’s zone cannot saturate the name servers serving other customers’ zones |
| AWS Lambda async invocations | Distributes tenants across randomly assigned queues using shuffle-sharding | A tenant with a seasonal traffic spike cannot exhaust the queue workers serving all other tenants |
| Grafana Cortex / Loki | Assigns each tenant a shard of ingester and querier instances | An out-of-memory query from one tenant only crashes the queriers in that tenant’s shard |
| Kubernetes API server | Uses shuffle-sharding within its Priority and Fairness flow control system to assign API requests to queues | A misconfigured controller flooding the API server cannot starve other controllers of request budget |
The requirements shuffle-sharding demands from its clients
Shuffle-sharding does not work in isolation. It places specific demands on the systems around it, and understanding those demands is what separates a successful deployment from a broken one.
The most fundamental requirement is client-side fault tolerance. Because a tenant’s shard is a small subset of the total worker pool, a failure or saturation in one shard worker does not automatically reroute the tenant to a healthy worker outside their shard. The client — or the routing layer — must be prepared to retry across the workers within the shard, or to declare partial availability gracefully. Systems that cannot tolerate any individual worker being unavailable will not benefit from shuffle-sharding; in fact, they may be made worse by it.
The second requirement is a routing mechanism that understands shard membership. In the simplest deployment, this is DNS — each virtual shard gets its own DNS name, and Route 53 health checks ensure only healthy shard members are returned. In more complex systems, a content-aware load balancer or a control plane maintains the tenant-to-shard mapping and routes accordingly. Either way, a plain round-robin load balancer cannot implement shuffle-sharding without modification.
Shuffle-sharding is not a silver bullet: It contains blast radius; it does not eliminate it. A tenant repeatedly sending a “query of death” — a request that crashes whichever worker picks it up — will eventually exhaust all workers in their shard, requiring additional mitigations like querier forget-delay, circuit breaking, or dedicated attack capacity.
Shuffle-sharding and the broader resilience toolkit
Shuffle-sharding is most effective when it is one layer in a multi-layer resilience strategy rather than the only one. The pattern controls the blast radius of a failure, but it does not prevent individual shard members from being overwhelmed; that is the job of rate limiting and back-pressure mechanisms. It does not heal a crashed worker; that is the job of health checks and auto-scaling. And it does not protect against a tenant who gradually exhausts resources over a long period; that is the job of quotas and fair-share schedulers.
Additionally, as Christopher Curtin observed at DevNexus 2024, shuffle-sharding should always be paired with outage simulation and auto-scaling policies, since the technique’s benefits only manifest when the rest of the system can respond autonomously to the contained failure. A shard isolation that engineers cannot observe or react to quickly becomes a silent hazard.
| Resilience concern | Primary mechanism | Where shuffle-sharding fits |
|---|---|---|
| Blast radius of a noisy tenant | Shuffle-sharding | Core purpose |
| Individual worker overload | Rate limiting, back-pressure, auto-scaling | Reduces the surface area shuffle-sharding needs to protect |
| Worker crash recovery | Health checks, process supervisors | Ensures shard members recover so isolation is not permanent |
| Deliberate DDoS attacks | Shuffle-sharding + traffic scrubbing (e.g., AWS Shield) | Isolates the victim; scrubbing handles the attack itself |
| Cross-zone failures | Zone-aware shard assignment | Shard members should span availability zones, not concentrate in one |
| Gradual resource exhaustion | Per-tenant quotas and metering | Shuffle-sharding does not constrain slow-burn resource consumption |
Why the technique scales better as systems grow
One of the most counterintuitive properties of shuffle-sharding is that it becomes more effective as the system scales, not less. Most architectural challenges grow harder with scale: more workers mean more coordination, more failure modes, more operational surface area. Shuffle-sharding inverts this relationship.
As the worker pool grows, the number of unique shard combinations grows combinatorially. With 32 workers and a shard width of 4, there are 35,960 distinct virtual shards available. That is enough to give each tenant in a very large multi-tenant system a nearly unique combination, reducing blast radius to a rounding error. AWS notes explicitly that with enough workers, there can be more shuffle shards than there are customers — at which point each customer is effectively isolated even in a shared infrastructure.
Furthermore, because shuffle-sharding does not require provisioning dedicated resources, the cost of this isolation is essentially zero in terms of infrastructure. The same eight workers that served everyone before now serve everyone better, simply by changing which worker each tenant is allowed to reach.
The scalability inversion: Traditional sharding’s blast-radius improvement scales as 1/N (linearly with cell count). Shuffle-sharding’s improvement scales as 1/(N choose K) — a factorial relationship. At eight workers, that is already a 7× advantage. At 32 workers with shard width 4, the difference is measured in orders of magnitude.
Operational considerations worth knowing
Deploying shuffle-sharding in a production system raises a handful of practical questions that are worth thinking through before committing to the pattern.
First, shard rebalancing is non-trivial. When a new worker joins the fleet, existing shard assignments do not automatically redistribute. Depending on the assignment strategy, some tenants may need to be migrated to new shard members to maintain the minimized-overlap guarantee. Stateless hashing handles this gracefully since the hash function adapts automatically; stateful assignment systems need explicit rebalancing logic.
Second, observability must be shard-aware. Standard cluster-level metrics will show aggregate load, but the value of shuffle-sharding comes from the fact that different tenants experience different subsets of the fleet. Monitoring dashboards and alerting rules need to surface per-shard and per-tenant health, not just overall averages. AWS’s personal health dashboard — which shows status for your specific resources rather than the global service — is a macroscopic example of exactly this principle applied to customer communication.
Third, uneven load distribution becomes a consideration as shard assignments age. Because tenants are mapped to specific subsets of workers, and because tenant activity is rarely uniform, some shard combinations may see heavier load than others over time. Cortex’s documentation notes that shuffle-sharding may lead to less evenly balanced instances compared to uniform distribution under normal load — a worthwhile trade-off in exchange for dramatically better isolation under abnormal load.
What we have learned
In this article, we explored the noisy neighbor problem from its root cause — the architectural assumption that all workers are equally reachable by all tenants — through the progression of isolation strategies designed to contain it. We saw how naive load balancing produces a 100% blast radius, how regular sharding reduces it linearly to around 25% in a typical fleet, and how shuffle-sharding reduces it combinatorially to single-digit percentages using the same infrastructure. The mathematics behind that reduction, the N-choose-K formula, grow more powerful as fleets scale, inverting the usual relationship between system size and complexity.
We also covered where the pattern is deployed in production today — Route 53, AWS Lambda, Grafana Cortex, Loki, and the Kubernetes API server — along with its requirements: fault-tolerant clients, shard-aware routing, and complementary resilience layers for concerns shuffle-sharding does not address on its own. Finally, we noted the operational realities: shard rebalancing, shard-aware observability, and the small load-balance cost that is almost always worth paying for the isolation gains in multi-tenant systems.
