Java has always needed a way to call native code. Scientific computing, image processing, hardware drivers, cryptography libraries — the C ecosystem holds decades of production-grade implementations that no one wants to rewrite. Since Java 1.1, the official answer was the Java Native Interface, and for 25 years it was the only answer. That did not make it a good one.
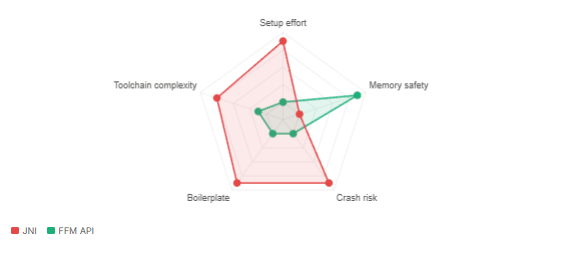
JNI demanded a boilerplate-heavy handshake between worlds: a Java native method declaration, a C header generated by javah, a C implementation that reached back into the JVM through opaque handle types, manual memory management with no safety net, and a separate compiled .so / .dll / .dylib for every target platform. A single incorrect pointer arithmetic calculation could silently corrupt memory or crash the entire JVM — not throw an exception, crash the JVM. The Panama developers estimated that FFM reduces the implementation effort compared to JNI by roughly 90%.
JEP 454 — the Foreign Function & Memory API — went GA in Java 22 (March 2024) after evolving through incubator and preview cycles in JDK 17 through 21. It lives in java.lang.foreign, requires no --enable-preview flag, ships no native glue code, and provides memory-safe off-heap allocation. It is standard Java SE. And it remains surprisingly underused.
This article walks through the three things you actually need to get off the ground: loading a shared library and calling a function, mapping a C struct to a MemoryLayout with proper field access via VarHandle, and understanding when to choose a confined versus a shared Arena. We will also look at the tradeoffs between safe and unsafe segments, and close with one interview question the FFM API tends to surface.
The Five Building Blocks You Need to Know
Before touching any code, it is worth building a clear mental model of the five types that compose the FFM API. They map directly onto the operations you perform when calling native code, and understanding their roles prevents the confusion that trips up most first-time users.
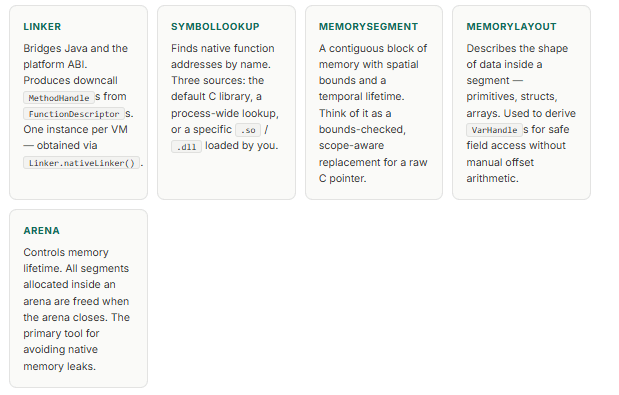
There is one additional type — FunctionDescriptor — which describes a C function’s parameter and return types in terms of MemoryLayout objects. You provide one to the Linker each time you bind a native function. With those six concepts in hand, the entire FFM surface becomes navigable.
Step 1 — Loading a Shared Library and Calling a Function
Let us start with the simplest possible case: calling strlen from the C standard library. This function takes a pointer to a null-terminated string and returns the number of characters. It lives in the default C library on every platform, so we do not even need to load a file — Linker.nativeLinker().defaultLookup() finds it directly.
Calling strlen from C stdlib — complete, runnable example (Java 22+)
import java.lang.foreign.*;
import java.lang.invoke.MethodHandle;
public class StrlenDemo {
public static void main(String[] args) throws Throwable {
// 1. Obtain the platform linker — one instance covers all native calls
Linker linker = Linker.nativeLinker();
// 2. Look up "strlen" in the default C library (libc on Linux/macOS,
// msvcrt on Windows). find() returns Optional.
MethodHandle strlen = linker.downcallHandle(
linker.defaultLookup()
.find("strlen")
.orElseThrow(() -> new RuntimeException("strlen not found")),
// FunctionDescriptor: return type first, then parameter types
// strlen returns size_t (ADDRESS width) and takes a pointer (ADDRESS)
FunctionDescriptor.of(ValueLayout.JAVA_LONG, ValueLayout.ADDRESS)
);
// 3. Arena manages the native memory that backs our C string.
// ofConfined() is single-threaded and faster; freed on Arena close.
try (Arena arena = Arena.ofConfined()) {
// allocateFrom copies the Java String into a null-terminated C string
MemorySegment cString = arena.allocateFrom("Hello, Panama!");
// 4. Invoke the downcall handle — invokeExact requires exact types
long length = (long) strlen.invokeExact(cString);
System.out.println("Length: " + length); // 14
}
// Arena closes here: cString is freed, any further access throws ISE
}
}
Compile and run with a plain
javac StrlenDemo.java && java StrlenDemoon Java 22 or later. No--enable-preview, no extra flags, no native glue code. The FFM API is part ofjava.base.
Notice that the FunctionDescriptor uses ValueLayout.JAVA_LONG for size_t. On 64-bit platforms size_t is 8 bytes, which matches Java’s long. On 32-bit platforms you would use ValueLayout.JAVA_INT. JEP 454 is explicit that developers are responsible for matching C type sizes — the linker implements the platform ABI but cannot guess the C types for you. When loading a third-party library rather than the default stdlib, replace linker.defaultLookup() with:
// Load a specific shared library by path
SymbolLookup myLib = SymbolLookup.libraryLookup(
"/usr/lib/x86_64-linux-gnu/libz.so.1", arena
);
// Then: myLib.find("compress2").orElseThrow(...)
SymbolLookup.libraryLookup()and a handful of other FFM operations are restricted — if used incorrectly they can crash the JVM. The JVM logs a warning the first time a restricted method is called unless you add--enable-native-access=ALL-UNNAMED(or your module name) to the JVM launch flags. This flag suppresses the warning; it does not grant any additional permission. Make it explicit in your run configuration.
JNI vs FFM — effort and risk comparison
Step 2 — Mapping a C Struct to MemoryLayout
Calling scalar functions is the easy case. The real complexity in native interop is structs — C’s answer to value types. A C struct is a contiguous block of fields with platform-defined alignment and possible padding bytes inserted by the compiler. If you mis-describe the layout, you silently read the wrong bytes. MemoryLayout makes the description declarative, and VarHandle eliminates all manual offset arithmetic.
Imagine a C library for sensor readings that exposes this struct:
C definition (sensor.h)
// C struct — compiler will add 4 bytes of padding after 'id'
// to align 'timestamp' on an 8-byte boundary
typedef struct {
int id; // 4 bytes at offset 0
// [4 bytes padding inserted by compiler]
long timestamp; // 8 bytes at offset 8
float temperature; // 4 bytes at offset 16
// [4 bytes padding to round struct size to 24]
} SensorReading;
The critical word there is padding. Struct fields must be naturally aligned: a long at offset 4 would straddle an 8-byte boundary, so the compiler inserts 4 bytes of padding to push it to offset 8. If you forget that padding in your Java layout, every field after the first one reads garbage. MemoryLayout.paddingLayout() is how you express it:
Java — StructLayout with correct padding and VarHandle field access
import java.lang.foreign.*;
import java.lang.invoke.VarHandle;
public class SensorReadingLayout {
// Declare the struct layout once as a constant — reuse it everywhere
static final StructLayout SENSOR_READING = MemoryLayout.structLayout(
ValueLayout.JAVA_INT .withName("id"), // 4 bytes
MemoryLayout.paddingLayout(4), // 4 bytes padding
ValueLayout.JAVA_LONG .withName("timestamp"), // 8 bytes
ValueLayout.JAVA_FLOAT.withName("temperature") // 4 bytes
// final 4 bytes of padding omitted — safe for single-struct use;
// add paddingLayout(4) if this struct appears inside an array
).withName("SensorReading");
// Derive VarHandles from layout paths — no manual byte offsets needed
static final VarHandle ID_HANDLE =
SENSOR_READING.varHandle(MemoryLayout.PathElement.groupElement("id"));
static final VarHandle TS_HANDLE =
SENSOR_READING.varHandle(MemoryLayout.PathElement.groupElement("timestamp"));
static final VarHandle TEMP_HANDLE =
SENSOR_READING.varHandle(MemoryLayout.PathElement.groupElement("temperature"));
public static void main(String[] args) {
try (Arena arena = Arena.ofConfined()) {
// Allocate exactly the bytes the struct requires (20 bytes here)
MemorySegment seg = arena.allocate(SENSOR_READING);
// Write fields — VarHandle knows the offsets from the layout
ID_HANDLE .set(seg, 0L, 42);
TS_HANDLE .set(seg, 0L, System.currentTimeMillis());
TEMP_HANDLE.set(seg, 0L, 36.6f);
// Read them back
int id = (int) ID_HANDLE .get(seg, 0L);
long ts = (long) TS_HANDLE .get(seg, 0L);
float temp = (float) TEMP_HANDLE.get(seg, 0L);
System.out.printf("Sensor %d at %d: %.1f°C%n", id, ts, temp);
}
}
}
You can verify the offsets the layout computed by calling
SENSOR_READING.byteOffset(MemoryLayout.PathElement.groupElement("timestamp"))— it returns 8 for this struct, confirming the padding is in the right place. Print all offsets during development and compare them againstoffsetof()values from a small C program to catch any mismatch early.
Mapping an array of structs
When the C function returns a pointer to an array of structs, you wrap the single-struct layout in a SequenceLayout and add an extra long coordinate to your VarHandle path to address the element index:
Sequence of structs — reading element i
// Sequence of 100 SensorReading structs — trailing padding IS needed here
static final StructLayout PADDED_SENSOR = MemoryLayout.structLayout(
ValueLayout.JAVA_INT .withName("id"),
MemoryLayout.paddingLayout(4),
ValueLayout.JAVA_LONG .withName("timestamp"),
ValueLayout.JAVA_FLOAT.withName("temperature"),
MemoryLayout.paddingLayout(4) // required to align next array element
).withName("SensorReading");
static final SequenceLayout SENSORS_ARRAY =
MemoryLayout.sequenceLayout(100, PADDED_SENSOR);
// VarHandle now takes (MemorySegment, long baseOffset, long elementIndex)
static final VarHandle SEQ_TEMP =
SENSORS_ARRAY.varHandle(
MemoryLayout.PathElement.sequenceElement(),
MemoryLayout.PathElement.groupElement("temperature")
);
// Reading element 7's temperature:
float t = (float) SEQ_TEMP.get(segment, 0L, 7L);
Step 3 — Safe vs Unsafe Segments and the Arena Tradeoff
Every MemorySegment has two kinds of safety guarantees: spatial (you cannot read or write outside its bounds — you get an IndexOutOfBoundsException, not a silent corruption or JVM crash) and temporal (you cannot access a segment after its arena closes — you get an IllegalStateException). Together these two guarantees are what make FFM fundamentally safer than JNI.
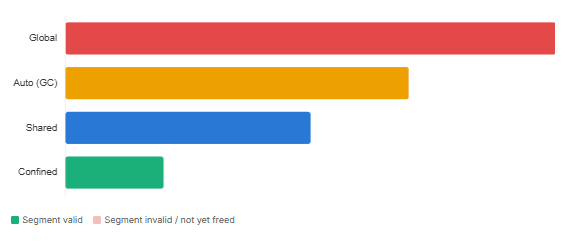
The choice of arena type determines the shape of the temporal guarantee and has a meaningful performance implication:
| Arena type | Factory | Thread access | Who closes | Use case | Relative cost |
|---|---|---|---|---|---|
| Confined | Arena.ofConfined() | Owner thread only | Owner thread only | Single-threaded scoped native call | Lowest |
| Shared | Arena.ofShared() | Any thread | Any thread (atomic close) | Multi-threaded or long-lived native buffers | Higher |
| Auto | Arena.ofAuto() | Any thread | GC (non-deterministic) | Exploratory code, testing | Higher |
| Global | Arena.global() | Any thread | Never closed | Process-lifetime constants (e.g. shared lib handle) | Never freed |
The shared arena’s higher cost comes from the synchronization it needs during closure: it must atomically invalidate all outstanding segments while ensuring no thread is mid-access. The JEP describes this as needing to “detect and cancel pending concurrent access operations.” For tight inner loops, this overhead matters — use confined arenas there and promote to shared only when cross-thread access is genuinely required.
Arena.ofAuto() is tempting because it removes the need to manage the arena’s own lifetime. Resist that temptation in production code. Non-deterministic GC-driven release means a program under memory pressure can hold onto large native buffers for far longer than you intend. Treat it the way you would treat finalizers: useful for experiments, wrong for production.
The “unsafe segment” scenario
Not every MemorySegment you encounter is safe. When a C library returns a pointer — say, the address of a struct it allocated internally — you need to wrap that raw address in a MemorySegment so Java can read from it. The problem is that Java has no idea how large that allocation is, so the resulting segment has unknown size. You produce it via MemorySegment.ofAddress() and immediately reinterpret it with a known size:
Reinterpreting a raw C pointer returned by a native function
// Suppose a C function returns: SensorReading* get_latest_reading() // Its downcall handle returns a MemorySegment with zero-size (just a pointer) MemorySegment rawPointer = (MemorySegment) getLatestReading.invokeExact(); // Zero-size: any read/write on rawPointer will throw IndexOutOfBoundsException // Reinterpret as the correct size — YOU are asserting the C library's contract here MemorySegment reading = rawPointer.reinterpret(SENSOR_READING.byteSize()); // Now safe to read fields via VarHandles float temp = (float) TEMP_HANDLE.get(reading, 0L);
reinterpret() is a restricted method. You are asserting to the JVM that the pointer really does point to a valid allocation of at least that many bytes. If the C library returns a dangling pointer or your size assertion is wrong, you can still crash the JVM — this is the one place where FFM hands the safety responsibility back to you. Treat every reinterpret() call as a documented assumption about the native library’s contract, and write a comment explaining it.
Arena lifetime model — when memory is freed
Beyond Hand-Written Layouts: jextract
Writing MemoryLayout definitions by hand works well for small structs and a handful of functions. For a library exposing hundreds of functions and dozens of types — zlib, OpenSSL, a hardware SDK — the manual approach is impractical. The answer is jextract, a companion tool under Project Panama that reads a C header file and generates a complete, correct Java binding.
# Generate Java bindings from a C header — jextract ships separately from the JDK jextract \ --output src/generated \ --target-package com.example.sensor.native \ -l sensor \ /usr/local/include/sensor.h
The generated code includes the StructLayout, all VarHandle accessors, and a downcall handle factory per exported function — all platform-correct with proper padding. Match your jextract version to your JDK version, as the generated API surface tracks the FFM API’s own evolution. Re-generate whenever the C headers change; the generated code is intentionally not hand-editable.
Java 24 performance noteJava 24 delivered significant FFM performance improvements without any API changes. If you benchmarked FFM on Java 22 and found hotspots around downcall overhead, re-run those benchmarks on Java 24 or 25 — the JIT got substantially smarter about inlining and specializing downcall stubs. Plain function call throughput on Java 24 is on par with JNI in most benchmarks.
Interview Question
What is the difference between a confined Arena and a shared Arena in the FFM API, and when would you choose one over the other?
A confined arena has an owner thread: only the thread that created it can allocate from it, access its segments, or close it. Because no synchronization is needed, access is fast and the close operation is deterministic and instant. The right choice for any native call that is scoped to a single thread — the common case in request-handling or batch-processing code.
A shared arena has no owner thread: any thread may access its segments and any thread may close it. The close is atomic and safe — it detects and cancels concurrent accesses — but that synchronization adds overhead. Use a shared arena when native memory genuinely must be shared across threads: a long-lived off-heap buffer shared by a producer and consumer, or a native handle passed to a thread pool. The distinction matters for correctness, not just performance: accessing a confined arena’s segment from a non-owner thread throws
WrongThreadExceptionimmediately.
Why FFM Adoption Has Lagged — and Why That Is Changing
Despite being standard since Java 22, FFM remains less common in production codebases than its maturity warrants. A few honest reasons account for most of that gap.
| Barrier | Reality check | Mitigation |
|---|---|---|
| JNI muscle memory | Teams with existing JNI wrappers have little incentive to migrate working code | Migrate at new-feature boundaries; FFM and JNI coexist in the same JVM |
| Manual layout definition | Padding bugs are silent and hard to diagnose | Use jextract for any library with >3 structs; verify with byteOffset() |
| –enable-native-access warning | Looks alarming in CI logs; teams add it and forget why | Add to JVM flags deliberately and document the module name |
| invokeExact type strictness | MethodHandle.invokeExact() throws WrongMethodTypeException if types don’t match precisely — even int vs long | Derive Java types directly from FunctionDescriptor; use invoke() during prototyping, switch to invokeExact() for production |
| Java version floor | Teams on Java 17 or 21 were on preview — legitimate concern until recently | Java 22 is GA; Java 21 LTS users should target Java 25 LTS (September 2025) |
The trajectory is positive. As more libraries ship jextract-generated bindings and the Java ecosystem standardises on LTS releases past Java 22, FFM will become the default rather than the exception for native interop. The fact that Kotlin 2 and several JVM languages already treat FFM as the preferred native bridge accelerates that transition.
What We Learned
We began by tracing why JNI was never a good answer to native interop and how JEP 454 replaced it with a cohesive, memory-safe model in Java 22. We then unpacked the five core building blocks — Linker, SymbolLookup, MemorySegment, MemoryLayout, and Arena — establishing a mental model before writing any code. The first practical example showed a complete strlen downcall, illustrating how FunctionDescriptor, Arena.ofConfined(), and allocateFrom() cooperate to produce a runnable, flag-free Java 22 program. The struct section introduced StructLayout with explicit padding — the most common source of silent bugs — and showed how VarHandle paths eliminate manual offset arithmetic for both single structs and SequenceLayout arrays.
We then examined all four arena types, their thread-access rules, and the GC-driven pitfall of Arena.ofAuto() in production, before covering the one genuinely unsafe operation (reinterpret()) and why it still belongs in any production FFM codebase as a documented assumption. We rounded out with jextract for library-scale bindings and the Java 24 performance improvements, and closed with an interview question that tests understanding of the confined-versus-shared trade-off — a distinction that is simultaneously about performance and correctness.
