For over a decade, running Apache Kafka in production meant running two distributed systems simultaneously. Kafka handled message streaming; ZooKeeper handled cluster metadata, controller elections, and configuration storage. Every Kafka deployment came with a ZooKeeper ensemble attached — its own monitoring, its own upgrade cycle, its own failure modes, and its own expertise requirement on your team.
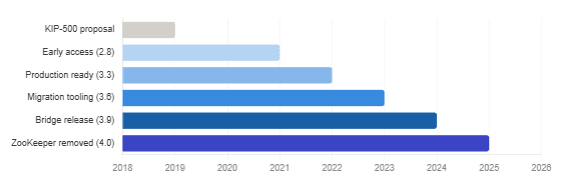
That era ended on March 18, 2025. Apache Kafka 4.0 shipped with ZooKeeper support completely removed — not deprecated, not optional, removed. KRaft (Kafka Raft), the consensus protocol Kafka began building with KIP-500 back in 2019, is now the only supported metadata management mode across the entire Kafka portfolio.
For Java developers working with Spring Kafka, the immediate question is practical: what, specifically, needs to change in your application? The reassuring answer is that most of what you have written stays intact. The @KafkaListener, KafkaTemplate, and the bulk of your application.yml are unaffected. However, several properties did change, one previously optional property became consequential, and the new KIP-848 consumer rebalance protocol introduces a meaningful opt-in that developers on Kafka 4.x should understand.
In this article we cover the architectural shift from ZooKeeper to KRaft, the four configuration properties that differ, what Spring Kafka-specific changes to expect, and a step-by-step migration checklist for teams still running ZooKeeper-based clusters.
ZooKeeper vs KRaft: What Actually Changed Under the Hood
Before jumping to configuration, a clear mental model of the architectural difference helps. The two approaches differ not just in components but in where metadata lives and how it travels through the system.
ZooKeeper Mode (removed in Kafka 4.0)
- Metadata stored in ZooKeeper’s tree structure (
/brokers,/topics,/controller) - Separate ZooKeeper ensemble (3 or 5 nodes) required
- Controller elected via ZooKeeper watches
- Metadata propagated: ZooKeeper → controller → brokers
- Partition limit: practical ceiling ~200K due to ZooKeeper load
- Topic creation with 1,000 partitions could take 10–15 seconds
- Separate TLS, monitoring, and upgrade cadence for ZooKeeper
KRaft Mode (only mode in Kafka 4.0+)
- Metadata stored in Kafka’s own internal topic:
__cluster_metadata - No external dependency; controllers run as designated Kafka nodes
- Controller elected via Raft quorum among controller nodes
- Metadata as an event log — incremental, O(1) append operations
- Partition limit: tested to millions; 600K on a single broker in Instaclustr experiments
- Same operation is near-instantaneous as a log append
- Single system to monitor, secure, and upgrade
The key insight is that KRaft does not merely replace ZooKeeper with an equivalent — it changes the data model itself. ZooKeeper stored metadata as a tree of nodes. KRaft stores metadata as an append-only log, which means every metadata change — topic creation, partition reassignment, ACL update — is a record appended to __cluster_metadata. This is the same model Kafka has always used for messages, applied to the control plane. The result is dramatically faster metadata operations and the removal of a propagation bottleneck.
KRaft maturity timeline — from KIP-500 to Kafka 4.0
The 4 Config Properties That Differ in Kafka 4.x
Most Spring Kafka configuration you have written for Kafka 3.x will compile and run unchanged against Kafka 4.x brokers. The changes are surgical. There are four areas where the property landscape shifted, and understanding each prevents a confusing startup error or silent misconfiguration.
1. bootstrap.servers is now the only cluster entry point
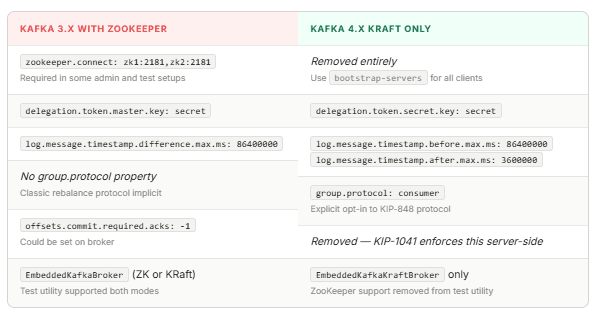
In ZooKeeper-based Kafka, some administrative tooling and legacy client patterns used a zookeeper.connect property to point at the ZooKeeper ensemble. In Spring Kafka, you may have seen it as a custom property in integration tests or admin client configurations. This property is entirely gone in Kafka 4.0 — there is no ZooKeeper ensemble to connect to. The single entry point for all clients, including admin clients, is bootstrap.servers (or its Spring alias spring.kafka.bootstrap-servers). Any code or shell script still using --zookeeper flags must be updated to --bootstrap-server.
2. delegation.token.master.key → delegation.token.secret.key
If your cluster uses Kafka’s delegation token authentication, the broker-side property name changed. The old delegation.token.master.key was removed in Kafka 4.0; the replacement is delegation.token.secret.key. The semantics are identical — only the name changed. Spring Kafka applications that set broker-side properties (for example, in integration tests using an embedded broker with custom configuration) must update this name.
3. log.message.timestamp.difference.max.ms split into two properties
Broker-side validation of message timestamps used a single property, log.message.timestamp.difference.max.ms, that bounded both how far into the past and how far into the future a message timestamp could be. This was removed in Kafka 4.0 and replaced with two explicit properties: log.message.timestamp.before.max.ms for maximum age and log.message.timestamp.after.max.ms for how far ahead a timestamp can be. If you set the old property on a Kafka 4.x broker, the broker will fail to start with an unknown configuration error. Update embedded broker configurations in integration tests that set this property.
4. group.protocol — opt in to the next-generation rebalance protocol
This is the most consequential of the four for application developers. The new consumer rebalance protocol from KIP-848 is enabled on the broker by default in Kafka 4.0, but consumers must explicitly opt in by setting group.protocol=consumer. Without it, your consumer falls back to the classic protocol, which still works but misses the performance improvements. We cover this in detail in the next section.
| Property | Old value / name | Kafka 4.x value / name | Scope | Breaking? |
|---|---|---|---|---|
zookeeper.connect | e.g. zk1:2181,zk2:2181 | Removed entirely — use bootstrap.servers | Client / admin tooling | Yes |
delegation.token.master.key | Any string value | delegation.token.secret.key | Broker config | If used |
log.message.timestamp.difference.max.ms | e.g. 86400000 | log.message.timestamp.before.max.ms + log.message.timestamp.after.max.ms | Broker config | If used |
group.protocol (new) | Not present (classic protocol implicit) | consumer to opt in to KIP-848 | Consumer client | Opt-in |
offsets.commit.required.acks | Broker default -1 | Removed — KIP-1041 hardens offset commit server-side | Broker config | If set |
Kafka 4.0 tightened the format validation for
--bootstrap-server. It now only accepts comma-separated values in the formhost1:port1,host2:port2. Space-separated values (which were silently accepted in earlier versions) now throw an exception. Audit any shell scripts or CI pipeline commands that construct bootstrap server strings dynamically.
What Changes for Your Spring Kafka Producer and Consumer
The good news first: Spring for Apache Kafka 4.0 dropped all ZooKeeper-related support alongside Apache Kafka 4.0. The library’s own ZooKeeper configuration helpers and test utilities were removed, and the EmbeddedKafkaBroker test utility was updated to support only KRaft. For the application layer, this means your Spring Kafka configuration is simpler, not more complex.
A standard Spring Kafka 4.x producer and consumer
application.yml — Spring Kafka 4.x with KRaft broker
spring:
kafka:
# bootstrap.servers is the only broker connection property needed
bootstrap-servers: broker1:9092,broker2:9092,broker3:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
acks: all # wait for all in-sync replicas — recommended
retries: 3
properties:
enable.idempotence: "true" # safe default; idempotent producer
consumer:
group-id: order-processor
auto-offset-reset: earliest
enable-auto-commit: false # always false with @KafkaListener
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
spring.json.trusted.packages: "com.example.orders"
# Opt in to the KIP-848 next-generation rebalance protocol
group.protocol: consumer
The structure is identical to a Kafka 3.x configuration file. The only meaningful addition is group.protocol: consumer in the consumer properties block. Everything else you had before continues to work. Note that there is no zookeeper.connect anywhere — that property never belonged in the Spring Kafka client configuration to begin with, but it sometimes appeared in integration test setups or custom admin client beans.
The KIP-848 rebalance protocol: why it matters
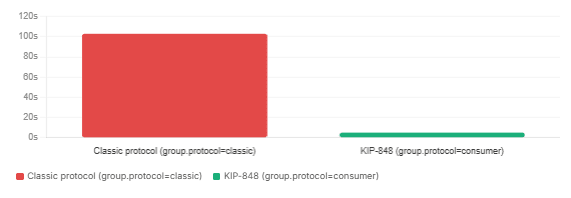
Setting group.protocol=consumer opts your consumer into the next-generation rebalance protocol introduced in KIP-848, which is generally available in Kafka 4.0. The difference is significant for any application that experiences frequent restarts, rolling deployments, or autoscaling events.
Under the classic protocol, any change to the consumer group membership — a consumer joining, leaving, or timing out — triggers a global synchronisation barrier. Every member in the group stops processing, revokes all its partitions, and waits for the group to rebalance completely before anyone resumes. In large groups or active autoscaling environments, this produces recurring processing pauses that are difficult to tune away.
KIP-848 eliminates that barrier. Rebalancing is now incremental and cooperative: a new consumer joining the group receives partitions incrementally, and existing consumers give up only the partitions they need to release — not all of them. The rebalancing logic has also moved server-side, to the group coordinator, simplifying client implementations.
In benchmark data published by the Kafka community, a group with 10 consumers adding 900 partitions completes rebalancing in approximately 5 seconds with the new protocol, compared to over 103 seconds with the classic protocol. The improvement scales with group size and partition count.
Integration tests: switching to EmbeddedKafkaKraftBroker
Spring Kafka’s @EmbeddedKafka annotation in the test module now uses a KRaft broker by default. The specific implementation class is EmbeddedKafkaKraftBroker. For most test classes, no change is needed beyond ensuring the spring-kafka-test dependency tracks version 4.x. Any test that previously instantiated a ZooKeeper-based embedded broker directly will need updating:
Integration test — @EmbeddedKafka with KRaft (Spring Kafka 4.x)
import org.springframework.kafka.test.context.EmbeddedKafka;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.annotation.DirtiesContext;
@SpringBootTest
@DirtiesContext
@EmbeddedKafka(
partitions = 3,
topics = { "order-events", "payment-events" },
// bootstrapServersProperty wired automatically in Spring Kafka 3.0.10+
bootstrapServersProperty = "spring.kafka.bootstrap-servers"
)
class OrderProcessorIntegrationTest {
// No ZooKeeper configuration needed — KRaft runs under the hood
}
Consumer rebalance time: classic protocol vs KIP-848
Before and After: Side-by-Side Configuration
The following comparison isolates the concrete differences between a ZooKeeper-era Spring Kafka configuration and its Kafka 4.x equivalent. Items that are identical in both are omitted to keep the focus on what actually changes.
Migration Checklist for Teams Still on ZooKeeper-Based Clusters
The most critical rule for migrating to Kafka 4.x is one stated plainly in the official upgrade documentation: you cannot upgrade directly from a ZooKeeper-based cluster to Kafka 4.0. The migration is two steps — first migrate from ZooKeeper mode to KRaft mode within the Kafka 3.x line, then upgrade the broker version to 4.0.
- Check your current Kafka version. Run
kafka-broker-api-versions.sh --bootstrap-server localhost:9092 --versionon any broker. If you are below 3.3, plan an incremental upgrade — from 2.x to 3.3, then 3.3 to 3.7+, before touching the ZooKeeper-to-KRaft migration. Each major hop needs its own validation window. - Upgrade to Kafka 3.9 as the bridge release. Kafka 3.9 is the recommended stepping stone to 4.0. It supports dynamic KRaft quorums (add or remove controllers without downtime via KIP-853) and ships the ZooKeeper-to-KRaft migration tooling in its most mature form. If you are already on 3.7 or 3.8, the migration tooling there is production-ready, but 3.9 is preferable.
- Run the ZooKeeper-to-KRaft migration in staging first. Use the official migration tooling introduced in 3.6. The process involves provisioning a KRaft controller quorum alongside the running ZooKeeper ensemble, enabling a dual-write phase where Kafka writes metadata to both systems simultaneously, and then promoting KRaft as the primary. You can roll back until you finalise the migration — after finalisation, the rollback path is closed. Never run the migration first in production.
- Audit every script and tool that uses
--zookeeper. The--zookeeperflag was removed from all Kafka admin commands in 4.0. This includeskafka-topics.sh,kafka-consumer-groups.sh, and others. Replace every--zookeeper zk1:2181argument with--bootstrap-server broker1:9092. Check CI pipelines, runbooks, and monitoring agents — this change bites in unexpected places. - Update broker configuration files. Remove
zookeeper.connect, renamedelegation.token.master.keyif used, splitlog.message.timestamp.difference.max.msinto its two replacements if set, and removeoffsets.commit.required.acks. A Kafka 4.x broker will fail to start if it encounters any of these removed properties as unrecognised configuration entries. - Update Spring Kafka and the Kafka client dependency together. Spring for Apache Kafka 4.0 targets Apache Kafka 4.0 clients. Do not mix Spring Kafka 4.x with Kafka client 3.x jars — the Spring Kafka 4.0.0-M2 announcement explicitly states the Kafka client was bumped to 4.0.0. If you are staying on Spring Boot 3.x, use Spring Kafka 3.3.x with Kafka client 3.9.x (manually overriding the client version in your build file).
- Add
group.protocol: consumerto your consumer configuration. This is technically optional — the classic protocol still works — but it is the right choice for all new and migrated deployments on Kafka 4.x brokers. The new protocol is GA, it is the direction the ecosystem is heading, and the rebalance performance improvement is material for production workloads. Test in a lower environment first to verify that yourConsumerRebalanceListenerimplementations behave correctly under the incremental protocol. - Retire the ZooKeeper ensemble nodes only after confirming the cluster is stable. Do not decommission ZooKeeper immediately after finalising the migration. Let the cluster run under KRaft alone for at least one full business cycle — ideally a week — monitoring metadata consistency, controller failover behaviour, and consumer group coordination. Only then is it safe to remove the ZooKeeper infrastructure from your estate. One fintech team that followed this cadence cut cluster setup time by roughly 40% after the dust settled.
If your organisation uses Confluent Cloud, Amazon MSK, or Google Managed Service for Apache Kafka, the ZooKeeper-to-KRaft migration will be handled transparently by the provider — or has already been completed. Your application-level changes (removing
zookeeper.connect, addinggroup.protocol: consumer) still apply, but the broker-side migration is not your responsibility.
Java Version Requirements
Kafka 4.0 raised the Java floor in two places. Kafka brokers, Connect workers, and command-line tools now require Java 17 at minimum. Kafka client libraries — the producer, consumer, and Kafka Streams API your Spring application uses — require Java 11. Since Spring Boot 4 itself requires Java 17, teams on Spring Boot 4 naturally satisfy the broker requirement too. If you are running Spring Boot 3.x with a Kafka 4.0 broker, ensure your application runtime is at least Java 11.
| Component | Minimum Java for Kafka 4.x | Notes |
|---|---|---|
| Kafka broker, Connect, tools | Java 17 | Raised from Java 11 in Kafka 3.x |
| Kafka client (producer/consumer/Streams) | Java 11 | Also requires broker 2.1+ before upgrading clients to 4.0 |
| Spring Boot 4 + Spring Kafka 4.x | Java 17 | Spring Boot 4 itself requires Java 17 |
| Spring Boot 3.x + Spring Kafka 3.3.x | Java 17 | Spring Boot 3.x minimum; Kafka client 3.9 compatible |
What We Learned
We began by placing the KRaft transition in context: Kafka 4.0 (March 2025) completely removed ZooKeeper — not deprecating it, removing it — replacing it with KRaft, a Raft-based metadata system built directly into Kafka that stores cluster state as an append-only log in the internal __cluster_metadata topic. We then compared the two architectures, noting the practical ceiling difference in partition counts and the elimination of the multi-hop metadata propagation path that made large ZooKeeper clusters a performance bottleneck.
On the configuration side, we walked through the four property areas that concretely change: the removal of zookeeper.connect, the renaming of delegation.token.master.key, the split of log.message.timestamp.difference.max.ms, and the new group.protocol=consumer opt-in for the KIP-848 next-generation rebalance protocol. We covered what those changes look like in Spring Kafka’s application.yml, why the KIP-848 protocol matters (near-instant incremental rebalancing versus stop-the-world barriers), and how the EmbeddedKafkaBroker test utility moved to KRaft-only. We then provided an eight-step migration checklist for teams still running ZooKeeper clusters, emphasising the mandatory two-step path — ZK to KRaft in 3.x, then upgrade to 4.0 — and the importance of auditing every --zookeeper CLI flag before going anywhere near a Kafka 4.0 broker.
