Platform Engineering in 2026: What It Actually Is, Why It’s Not Just DevOps Renamed, and How to Build an Internal Developer Platform
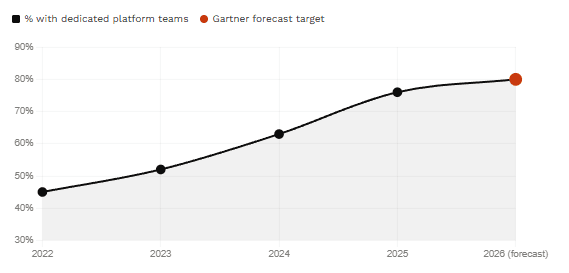
Gartner predicts 80% of large engineering organisations will have dedicated platform teams by 2026. The DORA 2025 report confirms high-quality internal platforms are the single strongest predictor of AI value delivery. Here is what the discipline actually means, what separates it from DevOps, and how to build one.
Every few years, a new label arrives and engineering leaders must decide: genuine paradigm shift, or repackaged convention? Platform engineering has suffered more than most from that scepticism. To a casual observer, it can sound like DevOps with a shinier name, a product manager bolted onto an ops team, or simply a Backstage.io installation dressed up as strategy.
That reading is wrong, and the gap between organisations that understand why and those that do not is widening. The DORA 2025 Report — drawing on nearly five thousand technology professionals — found a direct correlation between internal platform quality and an organisation’s ability to unlock value from AI. Not a loose association: a direct, measurable correlation. Teams with fragmented tooling and no coherent internal platform saw AI amplify their existing dysfunction. Teams with mature platforms saw the opposite. The quality of your internal developer platform is now the floor on which every AI initiative stands.
This article is aimed at engineering leaders making real decisions: whether to invest, how to structure the team, what to build first, and how to avoid the most expensive mistakes. It does not treat platform engineering as aspirational. It treats it as infrastructure — because in 2026, that is exactly what it is.
1. What Platform Engineering Actually Is
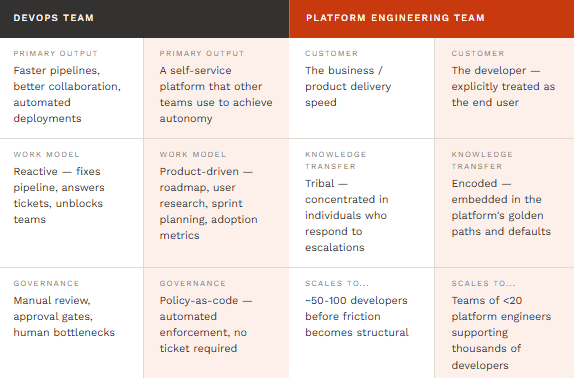
The most widely cited definition comes from Gartner: platform engineering is the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering teams in the cloud-native era. That is accurate but abstract. A more practical framing: platform engineering is the practice of treating your internal infrastructure and delivery system as a product, with developers as customers.
The word “product” is doing real work in that sentence. A product has a roadmap, a product manager, user research, onboarding, adoption metrics, and a feedback loop. Most internal infrastructure has none of those things. It has a Confluence page no one reads, a Jenkins job no one understands, and an undocumented Terraform module that three people have prod access to for reasons nobody remembers. Platform engineering replaces that with intentional design.
The output of that design is called an Internal Developer Platform (IDP). An IDP is not a single tool — it is a curated set of capabilities exposed through a coherent self-service interface, typically built around an Internal Developer Portal (which is the user-facing layer of the IDP, confusingly sharing the same acronym). Northflank’s breakdown distinguishes these clearly: the platform is the engine; the portal is the dashboard.
Internal Developer Platform (IDP): the backend system that actually provisions infrastructure, manages deployments, handles secrets, orchestrates CI/CD, and enforces policy. Internal Developer Portal: the self-service interface developers use to interact with the platform — usually built on Backstage.io or a commercial alternative. One is the car; the other is the steering wheel.
The five layers of a mature IDP

2. Why It Is Not Just DevOps Renamed
This question comes up in every leadership conversation about platform engineering, and it deserves a direct answer rather than careful hedging. Platform engineering is not DevOps renamed. It is not a rebrand. It is a response to a specific failure mode that emerges when DevOps principles are applied at scale without structural support. Understanding that failure mode is the fastest path to understanding why platform engineering exists as a distinct discipline.
DevOps, as a cultural movement, made a genuinely important contribution: it demolished the wall between development and operations by pushing operational ownership to the people building the software. “You build it, you run it” was the mantra. It worked brilliantly in fast-moving, small organisations. As EITT’s 2026 analysis documents, research from Spotify’s developer productivity team found that developers in DevOps-mature organisations were spending 30–40% of their time on infrastructure tasks entirely unrelated to business logic. The State of DevOps Report 2025 confirmed this: organisations with high developer cognitive load had 40% longer lead times for changes.
“You build it, you run it sounds empowering in a keynote. In practice, it means a front-end developer must also understand Kubernetes network policies, Ingress configuration, TLS certificates, cloud IAM policies, pipeline configuration, alerting rules, and secret rotation.”— EITT Platform Engineering Report 2026
Platform engineering does not abandon DevOps principles. It extends them by introducing a new abstraction boundary. Instead of every development team reinventing the same infrastructure knowledge, a platform team builds the abstractions themselves and exposes them through a self-service layer. The cognitive load does not disappear — it shifts downward into the platform, where it can be handled once, by specialists, at scale.
3. Golden Paths: The Core Concept You Need to Understand
If you take only one concept from this article, make it this one. A golden path is a pre-approved, opinionated route through a complex engineering task. Not the only route — developers can deviate — but the route that works, that is supported, that satisfies compliance requirements, and that does not require a ticket. Microsoft’s platform engineering documentation describes it well: “paved paths that guide developers through critical requirements and standards without sacrificing delivery velocity.”
Think of new paths starting as dirt trails, becoming paved as more people use them. That is exactly the lifecycle of a golden path. You start by observing what developers actually do repeatedly. You identify the highest-friction, highest-volume patterns — service creation, database provisioning, CI pipeline setup, environment cloning. Then you encode those patterns into a reproducible template that any developer can invoke through the portal with a few clicks, getting a compliant, production-ready result without ever needing to understand the underlying infrastructure.
Concretely, a golden path for “create a new microservice” might produce a GitHub repository with your organisation’s standard structure, a CI pipeline already configured, Kubernetes manifests referencing your standard resource limits and security policies, monitoring dashboards pre-wired to your observability stack, and a Backstage catalogue entry with ownership and documentation — all in under three minutes. The Calmops 2026 IDP guide describes this as “turning days into minutes” for service onboarding, and that compression is the headline metric of a well-built platform.
Rabobank’s platform engineering programme focused specifically on documenting standards, building golden paths, and automating onboarding. The result: new teams became productive within weeks rather than months. Port’s documented case study confirms this is not unusual — the compression of onboarding time from months to weeks is one of the most consistently cited outcomes of mature IDP adoption.
4. Backstage.io and the Internal Developer Portal Landscape
Backstage.io, originally built by Spotify to solve its own platform chaos and later donated to the CNCF, has become the dominant open-source framework for building developer portals. As of 2026, it powers IDPs at thousands of organisations from startups to Fortune 500 companies. Understanding what Backstage is — and is not — is essential before committing to it.
What Backstage gives you out of the box
Backstage provides four core components. The Software Catalog is a centralised registry of every service, API, library, and resource in your organisation, tracking ownership, dependencies, and metadata. The Scaffolder (Software Templates) allows you to define golden paths as code — parameterised templates that create repositories, configure pipelines, and register services in the catalogue. TechDocs treats documentation as code, publishing Markdown docs stored in your repositories as a searchable, versioned documentation site. The Plugin ecosystem — with hundreds of community and first-party plugins — integrates Backstage with your existing tool stack: PagerDuty, Datadog, Kubernetes clusters, GitHub Actions, and more.
The honest cost conversation
Backstage is free and open source. It is also not cheap. The total cost of ownership includes significant upfront engineering effort for installation, authentication configuration, and plugin development. Ongoing investment is needed to keep plugins maintained, handle upstream Backstage releases, and build new golden paths as your engineering organisation evolves. DevOps.com’s independent analysis notes that meaningful engineering investment is required for installation, customisation, maintenance, internal support, and product management. For teams without dedicated platform engineers comfortable with React, that cost is frequently underestimated.
| Portal Option | Type | Best For | Key Trade-off |
|---|---|---|---|
| Backstage.io | Open-source framework | Orgs with dedicated platform teams, high customisation needs, CNCF alignment | High TCO — needs React engineers and ongoing maintenance |
| Port | Commercial SaaS | Teams wanting rapid time-to-value without building from scratch | Vendor dependency; strong automation model reduces platform debt |
| Cortex | Commercial SaaS | Service ownership, scorecards, and maturity tracking at scale | ~$65–$69/user/month; 6-month+ full rollout timeline |
| OpsLevel | Commercial SaaS | Automated service cataloguing with minimal manual data entry | Less flexible than Backstage for deeply custom workflows |
| Roadie | Managed Backstage SaaS | Backstage benefits without self-hosting overhead | Less control than self-hosted; Backstage limitations still apply |
| Harness IDP | Commercial (Backstage-based) | Enterprise teams wanting AI-powered delivery pipelines with IDP integration | Best value when already using Harness for CI/CD |
N-iX’s 2025 platform engineering trends analysis found that 75% of developers lose over six hours weekly due to tool fragmentation. Custom Backstage deployments often require years of ongoing engineering. Commercial portals like Port and OpsLevel deliver 80% of Backstage’s functionality with a fraction of the effort. For CTOs making a build-vs-buy decision, the honest question is not “which is better” but “do we have the platform engineers to sustain a custom Backstage for the next five years?”
5. The DORA 2025 Finding That Changes Everything
One finding from the 2025 DORA Report deserves to be highlighted explicitly, because it reframes platform engineering as a business-critical investment rather than an infrastructure project. DORA’s platform engineering capability page states it directly:
“When platform quality is high, the effect of AI adoption on organisational performance becomes strong and positive. Conversely, when platform quality is low, the effect of AI adoption on organisational performance is negligible.”— DORA Research, 2025
This is remarkable, and it is not a soft finding. Google’s announcement of the 2025 DORA Report confirms: 90% of organisations have adopted at least one platform, and there is a direct correlation between a high-quality internal platform and an organisation’s ability to unlock the value of AI. The report calls platform engineering “an essential foundation for success” — not for software delivery alone, but specifically for realising AI investment.
Furthermore, the survey data from the State of Platform Engineering Report Volume 4 (518 engineers globally, 2025) shows that nearly 30% of platform teams do not measure success at all. Those teams are running on faith. In an economic climate demanding efficiency, that is a governance risk as much as an operational one.
Platform Engineering Adoption Curve (2022–2026)
6. Measuring Your Platform: Beyond Deployment Frequency
Platform engineering without metrics is, as the State of Platform Engineering report bluntly puts it, faith rather than engineering. Two frameworks dominate the measurement conversation, and neither alone tells the whole story.
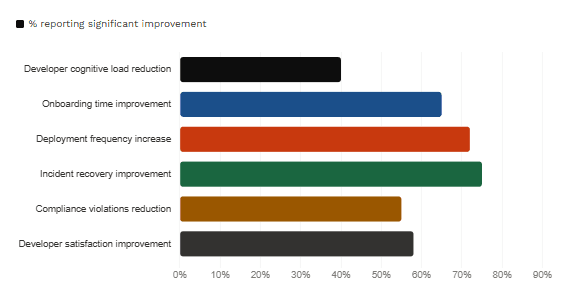
DORA metrics (deployment frequency, lead time for changes, change failure rate, mean time to recover) measure software delivery performance at the system level. They are essential baselines. EITT’s 2026 analysis confirms that organisations with mature platforms achieve 3.5× higher deployment frequency and 4× shorter lead times than organisations without. These are the numbers to present to a board.
SPACE metrics (Satisfaction and wellbeing, Performance, Activity, Communication and collaboration, Efficiency and flow) measure developer productivity holistically. A well-built platform impacts all five dimensions. Crucially, DORA’s 2025 research found that the platform capability most correlated with positive developer experience is giving “clear feedback on the outcome of my tasks.” That means logs, diagnostics, and deployment status exposed through the portal — not just successful deployments.
Reported Outcomes From IDP Adoption (2025)
7. How to Actually Build One: A Practical Roadmap
Most IDP initiatives fail not because the technology is wrong, but because the team tries to build everything at once. The discipline’s practitioners — particularly those at Netflix, Spotify, and Rabobank — are consistent on one point: start small, instrument early, and expand based on evidence. Microsoft’s platform engineering guidance explicitly warns against a “big bang” approach.
Phase 0 Weeks 1–4 Discovery First
Map the pain before writing a line of code
Interview developers across teams. Map their critical user journeys: “spin up a new service,” “debug a production issue,” “onboard a new engineer.” Quantify friction in hours per week. Identify the top three highest-volume, highest-pain patterns. These become your first golden paths. If you skip this phase, you will build the wrong thing with complete technical correctness.
Phase 1 Months 1–3 Foundation
Build one golden path end-to-end
Pick the single highest-friction journey from Phase 0. Build it completely — from developer click to running, compliant service — before adding anything else. This is your proof of concept and your internal sales pitch. Deploy it to a willing pilot team. Measure onboarding time before and after. This single metric, clearly evidenced, is how you justify the next quarter’s investment to leadership.
Phase 2 Months 3–6 Portal Layer
Deploy the developer portal and service catalogue
Add a developer portal — Backstage, Port, or your chosen platform — and populate the service catalogue with real services from your organisation. This is the moment the platform becomes visible and discoverable to the broader engineering organisation. Invest in UX. The portal’s quality is the platform’s perceived quality. A clunky portal will tank adoption regardless of how good the underlying engine is.
Phase 3 Months 6–12 Scale
Add golden paths, encode governance, expand coverage
Based on adoption metrics from Phase 2, identify the next highest-priority golden paths and build them. Simultaneously, begin encoding governance as policy-as-code (OPA, Conftest) rather than manual approval gates. Integrate observability — your platform should expose deployment status, alerts, and SLO compliance without developers leaving the portal. This is the phase where the platform starts paying back its construction cost.
Phase 4 Year 2+ Maturity
Platform-as-a-product operating model
Establish a platform product manager role. Define an SLA for the platform itself. Run regular developer satisfaction surveys (NPS or CSAT). Publish a public-internal roadmap. Treat the platform team’s quarterly planning the same way you treat a product team’s: user research, prioritisation, outcome metrics. This is the organisational posture that sustains a platform through leadership changes and budget cycles.
8. Common Failure Modes (And How to Avoid Them)
The State of Platform Engineering Vol. 4 found that nearly 30% of platform teams do not measure success at all. That is not the only failure mode, but it is the one that makes all the others invisible. Here are the patterns that consistently derail platform initiatives.
| Failure Mode | What It Looks Like | The Fix |
|---|---|---|
| No product owner | Platform decisions made by the most vocal engineer. Roadmap is a list of technical debt, not developer outcomes. | Assign a dedicated platform PM. Define developer experience as the primary success metric from day one. |
| Building too much too soon | Six-month build before any developer touches the platform. By launch, priorities have shifted and adoption never materialises. | Ship one golden path to one team in the first quarter. Instrument it. Expand based on evidence. |
| Mandatory adoption | Developers forced to use the platform by policy. Resentment grows. Workarounds proliferate. The platform becomes a compliance checkbox. | Make the platform the path of least resistance, not the only path. Good golden paths win adoption by making developers’ lives easier. |
| No feedback loop | Platform team builds in isolation. Developer pain points accumulate invisibly. Platform drifts from actual needs. | Run quarterly developer satisfaction surveys. Treat low NPS scores as P1 incidents. Make feedback visible and responded to publicly. |
| Underestimating Backstage TCO | Organisation adopts Backstage assuming “it’s free.” Two years later, three platform engineers spend 40% of their time on Backstage maintenance. | Calculate fully-loaded cost including salaries, hosting, and ongoing plugin development. Compare honestly against commercial alternatives for your organisation’s size. |
| Treating it as a tooling project | Platform team delivers Backstage + ArgoCD + Crossplane and declares victory. Adoption stalls because no one changed the operating model. | Platform engineering is organisational change with technology as an enabler. The culture shift — from reactive ops to proactive product — takes longer than the tooling. |
9. The Platform Engineering and AI Intersection in 2026
Platform engineering has acquired a new urgency in 2026 precisely because of AI. The DORA 2025 finding is a strategic inflection point: organisations that have neglected their internal platform are now discovering that AI coding assistants amplify their dysfunction rather than alleviating it. More code generated faster, pushed into fragile pipelines with slow feedback loops, results in more incidents, not fewer.
Organisations with mature platforms, conversely, see AI unlock a genuine multiplier effect. Fast feedback loops absorb AI-generated code changes without destabilising production. Policy-as-code guardrails catch AI-generated misconfigurations before deployment. Golden paths guide AI-generated service scaffolding toward compliant patterns from the start. The internal platform, in this model, becomes the “distribution layer for AI-based changes,” as platformengineering.com’s 2026 analysis puts it — enabling AI adoption without increasing organisational risk.
The State of Platform Engineering Vol. 4 report has released a new reference architecture specifically for AI/ML Internal Developer Platforms, addressing the unique governance and resource requirements of data scientists and MLOps workflows. AI is not replacing platform engineering — it is deepening the need for it.
If you are evaluating AI coding tools for your engineering organisation, your ROI calculation must include platform maturity as a variable. Faros AI’s analysis of DORA 2025 data found incidents per PR increased by 242.7% in organisations using AI without robust control systems. A platform investment is not a prerequisite for an AI investment — but it is a prerequisite for that AI investment paying off.
10. What We Learned
This article covered the full scope of platform engineering as a discipline — from first principles through to practical implementation. Here is the distilled version of what matters most.
- Platform engineering is the practice of treating internal infrastructure and delivery tooling as a product, with developers as customers. It is not DevOps renamed — it is a structural response to the cognitive load problem that emerges when DevOps scales beyond ~100 developers.
- The Internal Developer Platform (IDP) is the engine; the Internal Developer Portal is the steering wheel. Backstage.io is the dominant open-source framework for the portal layer, but its total cost of ownership is frequently underestimated. Commercial alternatives (Port, Cortex, OpsLevel) deliver 80% of the functionality at a fraction of the maintenance cost for teams without deep React and platform engineering expertise.
- Golden paths — pre-approved, opinionated, self-service templates for common engineering tasks — are the atomic unit of platform value. They encode organisational knowledge, encode compliance, and compress onboarding from months to days. Build these before building anything else.
- The DORA 2025 Report found a direct correlation between internal platform quality and an organisation’s ability to unlock AI value. This is the most strategically significant finding in the discipline’s recent history. Platform investment is no longer a developer experience initiative — it is an AI readiness initiative.
- The most consistent failure modes are: treating the platform as a tooling project (not an organisational change), not assigning a product owner, building too much before shipping to real users, and not measuring adoption or developer satisfaction.
- Start with discovery, not tooling. Map developer journeys. Build one golden path end-to-end in the first quarter. Instrument it. Expand based on evidence. The teams that succeeded at platform engineering — Netflix, Spotify, Rabobank — all started small and grew incrementally.
