The FLP Impossibility Result, 40 Years Later: Why It Still Defines Every Consensus Protocol You Use
In 1985, Fischer, Lynch, and Paterson proved that no deterministic algorithm can guarantee consensus in a fully asynchronous system with even a single faulty process. Forty years on, every protocol you rely on — Paxos, Raft, PBFT, Tendermint — exists precisely because engineers found clever ways to sidestep it. Here is the complete picture.
1. Setting the Scene: What Is Consensus?
Before diving into the theorem, it is worth being precise about the problem it addresses. In distributed systems, consensus means getting a collection of processes to agree on a single value — where each process starts with some initial input and must eventually output a decision that all correct processes share. Simple in principle; deceptively hard in practice.
Formally, a consensus protocol must satisfy three properties simultaneously:
| Property | What It Means | Intuitive Translation |
|---|---|---|
| Termination | Every correct process eventually decides a value | The algorithm does not hang forever |
| Agreement | All correct processes that decide, decide the same value | No two nodes reach different conclusions |
| Validity | The decided value was proposed by some process | The result cannot come from nowhere |
These three constraints seem entirely reasonable. They also turn out to be mutually incompatible under a specific — and surprisingly realistic — set of assumptions. That incompatibility is precisely what Fischer, Lynch, and Paterson proved in their 1985 JACM paper, which went on to win the 2001 Dijkstra Prize for the most influential paper in distributed computing.
2. Three System Models, One Key Distinction
The outcome of any distributed algorithm depends critically on the assumptions made about message timing and process speed. There are three standard models, and understanding where they sit on the spectrum is essential before the FLP result makes sense.
| Model | Message Delay Bounds | Process Speed Bounds | Can Solve Consensus? |
|---|---|---|---|
| Synchronous | Known fixed upper bound Δ | Known fixed upper bound Φ | Yes — even with many faults |
| Partially synchronous | Bounds exist but are unknown a priori | Bounds exist but unknown | Yes — with randomisation or timeouts |
| Asynchronous | No bound whatsoever — infinite delay is possible | No bound | No — FLP proves this impossible |
The partially synchronous model — formalised by Dwork, Lynch, and Stockmeyer in 1988 in a paper that itself won the 2007 Dijkstra Prize — captures the real world much better than either extreme. In practice, your TCP packets usually arrive within milliseconds, but there is no hard guarantee. That “usually” is the opening that every practical consensus protocol exploits.
FLP does not say consensus is hard. It says consensus is impossible to guarantee termination for in a purely asynchronous system. The moment you introduce even the weakest timing assumption — “messages will eventually be delivered in bounded time” — the impossibility dissolves.
3. The FLP Result in Plain English
“Every protocol for this problem has the possibility of nontermination, even with only one faulty process.”— Fischer, Lynch & Paterson, JACM April 1985, p. 374
The theorem targets the weakest possible fault model: just one process that can crash silently (no Byzantine behaviour, no lying, no message corruption — simply a process that stops responding). Even so, in a fully asynchronous network, no deterministic algorithm can simultaneously guarantee all three properties of consensus.
The fundamental reason is straightforward once you see it. In an asynchronous system, a process that has stopped responding is indistinguishable from a process that is merely very slow. Consequently, when a correct process is waiting for a message that would let it decide, it cannot know whether it should wait longer or give up. If it waits forever, termination fails. If it decides without waiting, it risks violating agreement — because that “slow” process might still be alive and heading towards a different decision. The algorithm is trapped between two bad options with no way to tell them apart.
This is not a limitation of clever engineering or insufficient hardware. It is a mathematical proof that the information simply does not exist to make the right call. Furthermore, as the paper noted at the time, the result settled a dispute that had been running in the distributed systems community for over a decade about whether such an algorithm might exist.
4. The Proof: Bivalency and the Indecision Trap
The actual proof is elegant and worth understanding at least structurally, because the technique — called the bivalency argument — has since been used to prove dozens of other impossibility results in distributed computing. The proof proceeds in two major steps.
The concept of valency
A system configuration is called 0-valent if, from that state, all possible future executions eventually decide 0. It is 1-valent if all futures decide 1. A configuration is bivalent if both outcomes are still reachable — the system has not yet committed to either value. Bivalent configurations are exactly the states of indecision.
- Lemma 1 — There always exists a bivalent initial configuration. The authors show that any correct protocol must have at least one starting state where the final decision is not yet determined. If every initial configuration were already decided (all 0-valent or all 1-valent), the protocol could not satisfy validity for all possible inputs.
2. Lemma 2 — From a bivalent configuration, you can always reach another bivalent configuration. This is the core. The adversary (who controls message scheduling) can always delay one critical message — the one that would tip the system into a univalent (decided) state — and instead deliver other messages first. This keeps the configuration bivalent. The process whose message was delayed is indistinguishable from a crashed process.
3. Conclusion — The adversary can maintain bivalency forever. By repeatedly applying Lemma 2, a scheduler can construct an infinite execution in which the system never reaches a decision. The run is admissible — every message is eventually delivered, every correct process takes infinitely many steps — yet no process ever decides. Termination fails.
The adversary in this proof is not a malicious attacker. It is simply an unfortunate message schedule — the kind of thing that happens routinely on any real network experiencing load, GC pauses, or transient congestion. The proof does not require any bad intent; only bad timing.
5. What FLP Does Not Say
The result is frequently misquoted, so it is worth being precise about what it does and does not claim. Getting this right matters a great deal in system design discussions.
| Common Misreading | What FLP Actually Says |
|---|---|
| “Consensus is impossible in distributed systems” | Consensus is impossible to guarantee termination of in a fully asynchronous model with even one crash. It is perfectly solvable in synchronous and partially synchronous models. |
| “Systems like etcd or ZooKeeper are broken” | Those systems operate under partial synchrony and use timeouts. They do not claim to work in a fully asynchronous model, so FLP does not apply to them directly. |
| “Non-terminating runs happen frequently in practice” | FLP shows such runs exist; it does not say they are common. Randomised timeouts make them astronomically rare in practice. |
| “Byzantine faults make things worse beyond FLP” | Technically true — Byzantine faults are a harder model — but FLP targets the simplest fault model (crash-stop). If you cannot solve consensus with one crash, Byzantine tolerance is a separate (harder) problem. |
| “CAP theorem is the same result as FLP” | Related but distinct. CAP (Gilbert & Lynch, 2002) is about consistency vs. availability under network partition. FLP is about termination under asynchrony and crashes. They overlap but address different trade-offs. |
6. Three Escape Routes Engineers Actually Use
Because FLP is a mathematical boundary rather than an engineering obstacle, the response from the research and engineering community was not to give up on consensus — it was to identify exactly which assumption in the impossibility proof could be relaxed, and how. There are three main approaches, and together they cover every protocol you will encounter in production.
Escape Route 1: Partial Synchrony
The most widely adopted approach. Rather than assuming messages can be arbitrarily delayed forever, partial synchrony assumes there exists some Global Stabilisation Time (GST) after which message delays are bounded — even if that bound is unknown in advance. Before GST, anything can happen. After GST, the system behaves enough like a synchronous system that progress is possible.
This is the model used by Raft, Paxos, PBFT, and Tendermint. In Raft, randomised election timeouts ensure that — in a period of network stability — a leader is eventually elected and log replication proceeds. The algorithm does not guarantee termination in the face of sustained asynchrony, but it does guarantee progress once the network behaves reasonably.
Escape Route 2: Randomisation
Ben-Or (1983) showed that if you allow processes to make random choices, you can sidestep the determinism that FLP depends on. The bivalency argument breaks down because the adversary cannot predict which way a coin flip will land. In theory, non-terminating executions still exist but occur with probability approaching zero as the algorithm runs. In practice, randomised algorithms make the probability of non-termination negligible within a small number of rounds.
Ethereum’s Gasper consensus protocol combines Casper FFG (finality) with LMD-GHOST (fork choice) and uses randomised committee selection to achieve liveness under partial synchrony without relying on a single elected leader. This is a direct descendant of the randomisation approach.
Escape Route 3: Failure Detectors
Chandra and Toueg (1996) introduced the idea of an unreliable failure detector — a separate oracle that provides hints about which processes may have crashed, even if those hints are sometimes wrong. They showed that even an eventually accurate failure detector — one that is wrong sometimes but eventually stops making mistakes — is sufficient to solve consensus. This result elegantly separated the “distributed systems” problem from the “timing” problem.
Heartbeat mechanisms in Raft (followers monitoring the leader’s heartbeat and triggering elections on timeout) are a practical implementation of an eventually accurate failure detector. The detector might falsely suspect a slow leader, triggering an unnecessary election — but eventually, either the actual failure is detected or the false alarm resolves and a stable leader takes over.
7. FLP Through the Lens of Every Major Protocol
With the three escape routes in mind, it becomes straightforward to understand what each major consensus protocol actually does — and why it is designed the way it is. None of these protocols breaks FLP; each of them works around it in a specific, explicit way.
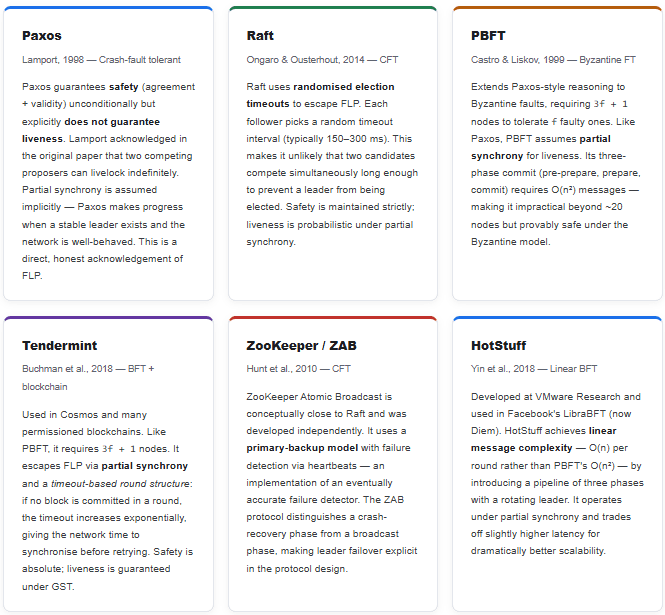
8. Protocol Comparison at a Glance
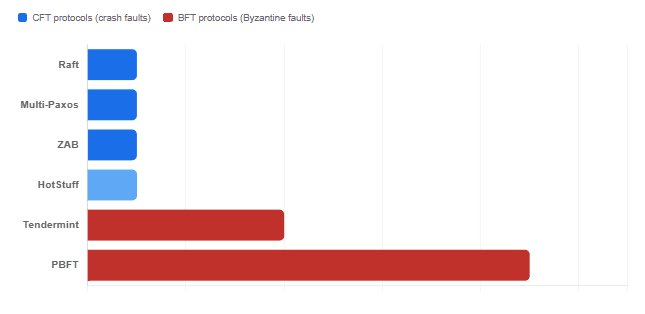
The following charts use published data from the original papers, academic surveys, and industry benchmarks to compare the major consensus protocols on the axes that matter most in system design: fault model, message complexity, and the specific FLP escape route each one uses.
Message Complexity per Consensus Round (number of nodes = n, Byzantine faults = f)
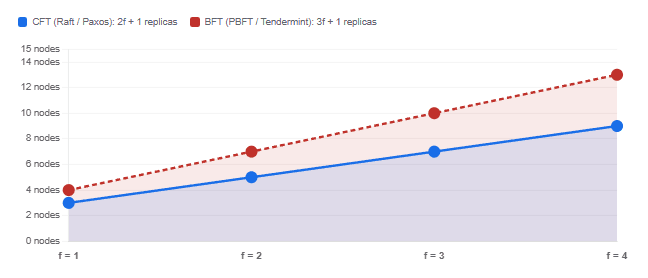
Minimum Replicas Required to Tolerate f Faulty Nodes
9. Why This Still Matters in System Design Interviews
FLP comes up constantly in senior-level system design interviews precisely because it separates candidates who understand the foundations of distributed systems from those who have only used the tools. The following patterns show up repeatedly.
Interview scenario: “Why can’t Raft guarantee it always elects a leader?”
The correct answer traces directly to FLP. Raft uses randomised timeouts, which means in theory two candidates could keep triggering split votes indefinitely. In practice this is vanishingly rare, but the protocol explicitly does not guarantee leader election in a fully asynchronous environment. It guarantees it under partial synchrony — which is why the timeout range matters and why tuning it is a real operational concern.
Interview scenario: “Why does Paxos not guarantee termination?”
Again, FLP. Paxos prioritises safety over liveness. A duelling-proposers scenario — where two proposers repeatedly pre-empt each other’s proposals — can prevent any value from being chosen indefinitely. Multi-Paxos mitigates this by electing a distinguished leader, which is essentially the same partial synchrony escape route that Raft uses, described differently.
Interview scenario: “Why does PBFT need 3f + 1 nodes while Raft only needs 2f + 1?”
Because PBFT must tolerate Byzantine faults where faulty nodes can actively lie. With 2f + 1 nodes and f Byzantine faults, a quorum of f + 1 could include all f Byzantine nodes plus one correct one — giving the Byzantine nodes a majority within the quorum. With 3f + 1 nodes, any quorum of 2f + 1 is guaranteed to contain at least f + 1 correct nodes, which outweighs the f Byzantine ones. This is a consequence of the Byzantine Generals problem (Lamport, Shostak & Pease, 1982), which FLP complements but does not subsume.
When you hear “consensus” in an interview, mentally ask: (1) What is the fault model — crash or Byzantine? (2) What timing assumption does the protocol rely on? (3) Does it guarantee safety, liveness, or both — and under what conditions? Those three questions will always lead you back to FLP.
The relationship to CAP
A common point of confusion is the relationship between FLP and the CAP theorem. They are closely related but address different problems. CAP (as formalised by Gilbert and Lynch in 2002) says that in the presence of a network partition, a distributed system must choose between consistency and availability. FLP says that even without network partition — just with message delays and a single crash — termination cannot be guaranteed deterministically. Together, they paint a thorough picture of why distributed systems are fundamentally harder than single-machine systems, and why systems like Apache Kafka, etcd, and Cassandra make very different design choices.
What We Have Learned
Forty years after it was published, the FLP result remains the bedrock on which every consensus protocol is built. Here is a concise summary of the ground we covered:
- FLP is not about complexity but about impossibility. Fischer, Lynch, and Paterson proved — not merely argued — that no deterministic algorithm can guarantee all three properties of consensus (termination, agreement, validity) in a fully asynchronous system with a single crash fault. The original paper is only 9 pages long and won the Dijkstra Prize in 2001.
- The proof uses the bivalency argument. A configuration is bivalent if both outcomes (0 or 1) are still reachable. The proof shows that a system can always be kept bivalent by a carefully chosen message schedule — and since a bivalent system has not decided, termination is never guaranteed.
- FLP targets the asynchronous model only. Consensus is perfectly solvable in synchronous systems, and in partially synchronous systems with the right tools. The result does not claim that systems like Raft or ZooKeeper are broken — it explains exactly what assumptions they rely on to work.
- There are three practical escape routes: partial synchrony (Raft, Paxos, PBFT, Tendermint), randomisation (Ben-Or, Ethereum’s Gasper), and unreliable failure detectors (heartbeat-based detection in Raft and ZAB). Every production consensus protocol uses at least one.
- CFT vs. BFT is a separate dimension. Crash-fault-tolerant protocols (Raft, Paxos) need only 2f + 1 replicas. Byzantine-fault-tolerant protocols (PBFT, Tendermint, HotStuff) need 3f + 1, because they must handle nodes that actively lie or behave arbitrarily.
- FLP and CAP are related but distinct. CAP concerns consistency versus availability under partition. FLP concerns termination under asynchrony and crash faults. Both are essential to understand before designing any distributed system.
